
CUDA is a parallel computing platform and programming mannequin developed by NVIDIA for normal computing by itself GPUs (graphics processing items). CUDA allows builders to hurry up compute-intensive purposes by harnessing the facility of GPUs for the parallelizable a part of the computation.
Whereas there have been different proposed APIs for GPUs, similar to OpenCL, and there are aggressive GPUs from different firms, similar to AMD, the mixture of CUDA and NVIDIA GPUs dominates a number of software areas, together with deep studying, and is a basis for a few of the quickest computer systems on the earth.
Graphics playing cards are arguably as previous because the PC—that’s, should you contemplate the 1981 IBM Monochrome Show Adapter a graphics card. By 1988, you may get a 16-bit 2D VGA Marvel card from ATI (the corporate ultimately acquired by AMD). By 1996, you may purchase a 3D graphics accelerator from 3dfx in order that you may run the first-person shooter recreation Quake at full pace.
Additionally in 1996, NVIDIA began making an attempt to compete within the 3D accelerator market with weak merchandise, however discovered because it went, and in 1999 launched the profitable GeForce 256, the primary graphics card to be referred to as a GPU. On the time, the principal purpose for having a GPU was for gaming. It wasn’t till later that individuals used GPUs for math, science, and engineering.
The origin of CUDA
In 2003, a staff of researchers led by Ian Buck unveiled Brook, the primary extensively adopted programming mannequin to increase C with data-parallel constructs. Buck later joined NVIDIA and led the launch of CUDA in 2006, the primary industrial answer for normal function computing on GPUs.
OpenCL vs. CUDA
CUDA competitor OpenCL was launched in 2009, in an try to offer a normal for heterogeneous computing that was not restricted to Intel/AMD CPUs with NVIDIA GPUs. Whereas OpenCL sounds engaging due to its generality, it hasn’t carried out in addition to CUDA on NVIDIA GPUs, and lots of deep studying frameworks both don’t help OpenCL or solely help it as an afterthought as soon as their CUDA help has been launched.
CUDA efficiency enhance
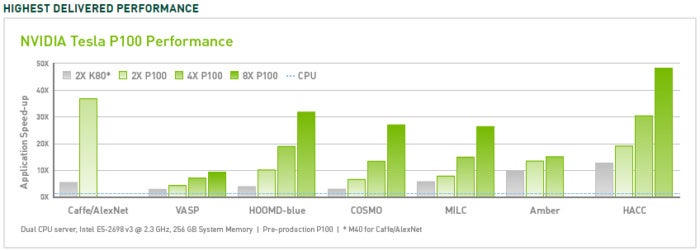
CUDA has improved and broadened its scope through the years, kind of in lockstep with improved NVIDIA GPUs. Utilizing a number of P100 server GPUs, you possibly can notice as much as 50x efficiency enhancements over CPUs. The V100 (not proven on this determine) is one other 3x quicker for some masses (so as much as 150x CPUs), and the A100 (additionally not proven) is one other 2x quicker (as much as 300x CPUs). The earlier technology of server GPUs, the K80, provided 5x to 12x efficiency enhancements over CPUs.
Word that not everybody studies the identical pace boosts, and that there was enchancment within the software program for mannequin coaching on CPUs, for instance utilizing the Intel Math Kernel Library. As well as, there was enchancment in CPUs themselves, principally to offer extra cores.
 NVIDIA
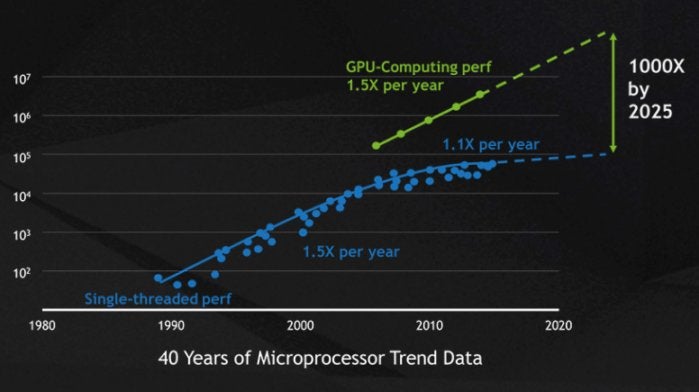
NVIDIAThe pace enhance from GPUs has come within the nick of time for high-performance computing. The only-threaded efficiency improve of CPUs over time, which Moore’s Regulation urged would double each 18 months, has slowed all the way down to 10% per 12 months as chip makers encountered bodily limits, together with dimension limits on chip masks decision and chip yield in the course of the manufacturing course of and warmth limits on clock frequencies at runtime.
 NVIDIA
NVIDIACUDA software domains
 NVIDIA
NVIDIACUDA and NVIDIA GPUs have been adopted in lots of areas that want excessive floating-point computing efficiency, as summarized pictorially within the picture above. A extra complete record contains:
- Computational finance
- Local weather, climate, and ocean modeling
- Knowledge science and analytics
- Deep studying and machine studying
- Protection and intelligence
- Manufacturing/AEC (Structure, Engineering, and Development): CAD and CAE (together with computational fluid dynamics, computational structural mechanics, design and visualization, and digital design automation)
- Media and leisure (together with animation, modeling, and rendering; coloration correction and grain administration; compositing; ending and results; enhancing; encoding and digital distribution; on-air graphics; on-set, evaluation, and stereo instruments; and climate graphics)
- Medical imaging
- Oil and fuel
- Analysis: Larger training and supercomputing (together with computational chemistry and biology, numerical analytics, physics, and scientific visualization)
- Security and safety
- Instruments and administration
CUDA in deep studying
Deep studying has an outsized want for computing pace. For instance, to coach the fashions for Google Translate in 2016, the Google Mind and Google Translate groups did a whole bunch of one-week TensorFlow runs utilizing GPUs; they’d purchased 2,000 server-grade GPUs from NVIDIA for the aim. With out GPUs, these coaching runs would have taken months reasonably than every week to converge. For manufacturing deployment of these TensorFlow translation fashions, Google used a brand new customized processing chip, the TPU (tensor processing unit).
Along with TensorFlow, many different deep studying frameworks depend on CUDA for his or her GPU help, together with Caffe2, Chainer, Databricks, H2O.ai, Keras, MATLAB, MXNet, PyTorch, Theano, and Torch. Usually they use the cuDNN library for the deep neural community computations. That library is so vital to the coaching of the deep studying frameworks that all the frameworks utilizing a given model of cuDNN have basically the identical efficiency numbers for equal use instances. When CUDA and cuDNN enhance from model to model, all the deep studying frameworks that replace to the brand new model see the efficiency positive factors. The place the efficiency tends to vary from framework to framework is in how nicely they scale to a number of GPUs and a number of nodes.
CUDA Toolkit
The CUDA Toolkit contains libraries, debugging and optimization instruments, a compiler, documentation, and a runtime library to deploy your purposes. It has parts that help deep studying, linear algebra, sign processing, and parallel algorithms.
Normally, CUDA libraries help all households of NVIDIA GPUs, however carry out greatest on the most recent technology, such because the V100, which might be 3x quicker than the P100 for deep studying coaching workloads as proven under; the A100 can add an extra 2x speedup. Utilizing a number of libraries is the best method to benefit from GPUs, so long as the algorithms you want have been carried out within the acceptable library.
 NVIDIA
NVIDIACUDA deep studying libraries
Within the deep studying sphere, there are three main GPU-accelerated libraries: cuDNN, which I discussed earlier because the GPU element for many open supply deep studying frameworks; TensorRT, which is NVIDIA’s high-performance deep studying inference optimizer and runtime; and DeepStream, a video inference library. TensorRT helps you optimize neural community fashions, calibrate for decrease precision with excessive accuracy, and deploy the educated fashions to hyperscale information facilities, embedded techniques, or automotive product platforms.
 NVIDIA
NVIDIACUDA linear algebra and math libraries
Linear algebra underpins tensor computations and subsequently deep studying. BLAS (Primary Linear Algebra Subprograms), a group of matrix algorithms carried out in Fortran in 1989, has been used ever since by scientists and engineers. cuBLAS is a GPU-accelerated model of BLAS, and the highest-performance method to do matrix arithmetic with GPUs. cuBLAS assumes that matrices are dense; cuSPARSE handles sparse matrices.
 NVIDIA
NVIDIACUDA sign processing libraries
The quick Fourier remodel (FFT) is among the primary algorithms used for sign processing; it turns a sign (similar to an audio waveform) right into a spectrum of frequencies. cuFFT is a GPU-accelerated FFT.
Codecs, utilizing requirements similar to H.264, encode/compress and decode/decompress video for transmission and show. The NVIDIA Video Codec SDK hastens this course of with GPUs.
 NVIDIA
NVIDIACUDA parallel algorithm libraries
The three libraries for parallel algorithms all have completely different functions. NCCL (NVIDIA Collective Communications Library) is for scaling apps throughout a number of GPUs and nodes; nvGRAPH is for parallel graph analytics; and Thrust is a C++ template library for CUDA primarily based on the C++ Normal Template Library. Thrust offers a wealthy assortment of information parallel primitives similar to scan, kind, and cut back.
NVIDIACUDA vs. CPU efficiency
In some instances, you should use drop-in CUDA features as a substitute of the equal CPU features. For instance, the gemm matrix-multiplication routines from BLAS might be changed by GPU variations just by linking to the NVBLAS library:
 NVIDIA
NVIDIACUDA programming fundamentals
In the event you can’t discover CUDA library routines to speed up your applications, you’ll should attempt your hand at low-level CUDA programming. That’s a lot simpler now than it was once I first tried it within the late 2000s. Amongst different causes, there’s simpler syntax and there are higher growth instruments out there.
My solely quibble is that macOS help for operating CUDA has disappeared, after a protracted descent into unusability. Probably the most you are able to do on macOS is to management debugging and profiling periods operating on Linux or Home windows.
To grasp CUDA programming, contemplate this straightforward C/C++ routine so as to add two arrays:
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
You possibly can flip it right into a kernel that may run on the GPU by including the __global__ key phrase to the declaration, and name the kernel by utilizing the triple bracket syntax:
add<<<1, 1>>>(N, x, y);
You even have to vary your malloc/new and free/delete calls to cudaMallocManaged and cudaFree so that you’re allocating house on the GPU. Lastly, it’s essential anticipate a GPU calculation to finish earlier than utilizing the outcomes on the CPU, which you’ll accomplish with cudaDeviceSynchronize.
The triple bracket above makes use of one thread block and one thread. Present NVIDIA GPUs can deal with many blocks and threads. For instance, a Tesla P100 GPU primarily based on the Pascal GPU Structure has 56 streaming multiprocessors (SMs), every able to supporting as much as 2048 energetic threads.
The kernel code might want to know its block and thread index to search out its offset into the handed arrays. The parallelized kernel usually makes use of a grid-stride loop, similar to the next:
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
In the event you take a look at the samples within the CUDA Toolkit, you’ll see that there’s extra to contemplate than the fundamentals I coated above. For instance, some CUDA perform calls have to be wrapped in checkCudaErrors() calls. Additionally, in lots of instances the quickest code will use libraries similar to cuBLAS together with allocations of host and machine reminiscence and copying of matrices forwards and backwards.
In abstract, you possibly can speed up your apps with GPUs at many ranges. You possibly can write CUDA code, you possibly can name CUDA libraries, and you should use purposes that already help CUDA.
Copyright © 2022 IDG Communications, Inc.

{kind=link}