
Are Imaginative and prescient Transformers truly helpful?
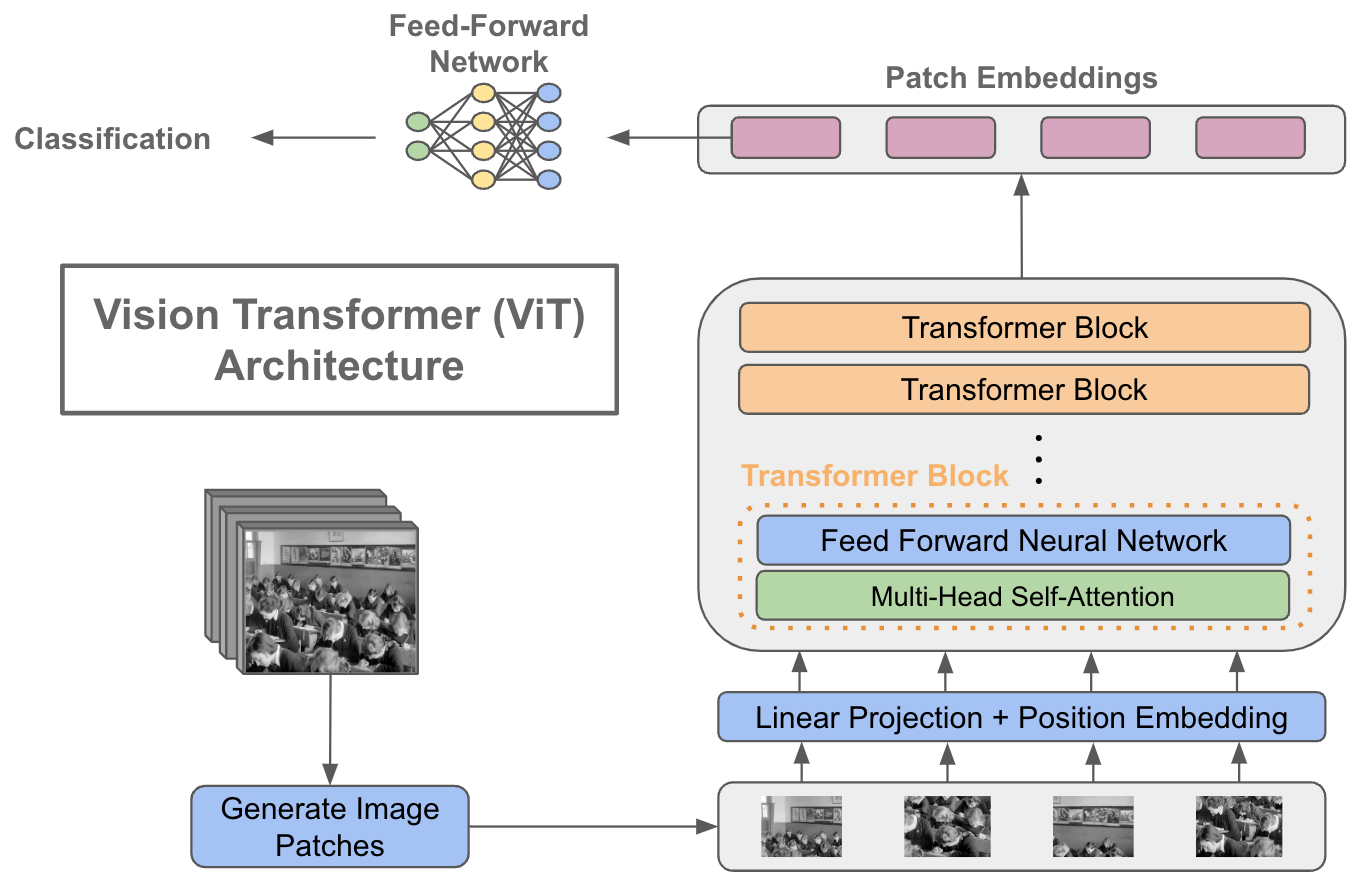
Transformers are a kind of deep studying structure, based mostly primarily upon the self-attention module, that have been initially proposed for sequence-to-sequence duties (e.g., translating a sentence from one language to a different). Latest deep studying analysis has achieved spectacular outcomes by adapting this structure to pc imaginative and prescient duties, resembling picture classification. Transformers utilized on this area are usually referred to (not surprisingly) as imaginative and prescient transformers.
Wait … how can a language translation mannequin be used for picture classification? Good query. Though this publish will deeply discover this matter, the essential thought is to:
- Convert a picture right into a sequence of flattened picture patches
- Go the picture patch sequence by the transformer mannequin
- Take the primary component of the transformer’s output sequence and cross it by a classification module
In comparison with widely-used convolutional neural community (CNN) fashions, imaginative and prescient transformers lack helpful inductive biases (e.g., translation invariance and locality). Nonetheless, these fashions are discovered to carry out fairly properly relative to fashionable CNN variants on picture classification duties, and up to date advances have made their effectivity — each by way of the quantity of knowledge and computation required — extra cheap. As such, imaginative and prescient transformers are actually a viable and useful gizmo for deep studying practitioners.
self-attention
The transformer structure is comprised of two main elements: feed-forward networks and self-attention. Although feed-forward networks are acquainted to most, I discover that self-attention is oftentimes much less widely-understood. Many thorough descriptions of self-attention exist on-line, however I’ll present a quick overview of the idea right here for completeness.
what’s self-attention? Self-attention takes n components (or tokens) as enter, transforms them, and returns n tokens as output. It’s a sequence-to-sequence module that, for every enter token, does the next:
- Compares that token to each different token within the sequence
- Computes an consideration rating for every of those pairs
- Units the present token equal to the weighted common of all enter tokens, the place weights are given by the eye scores
Such a process adapts every token within the enter sequence by trying on the full enter sequence, figuring out the tokens inside it which might be most necessary, and adapting every token’s illustration based mostly on probably the most related tokens. In different phrases, it asks the query: “Which tokens are price listening to?” (therefore, the title self-attention).
multi-headed self-attention. The variant of consideration utilized in most transformers is barely completely different than the outline supplied above. Particularly, transformers oftentimes leverage a “multi-headed” model of self consideration. Though this may occasionally sound sophisticated, it’s not … in any respect. Multi-headed self-attention simply makes use of a number of completely different self-attention modules (e.g., eight of them) in parallel. Then, the output of those self-attention fashions is concatenated or averaged to fuse their output again collectively.
the place did this come from? Regardless of using self-attention inside transformers, the concept predates the transformer structure. It was used closely with recurrent neural community (RNN) architectures [6]. In these functions, nevertheless, self-attention was normally used to mixture RNN hidden states as a substitute of performing a sequence-to-sequence transformation.
the transformer structure
Imaginative and prescient transformer architectures are fairly just like the unique transformer structure proposed in [4]. As such, a primary understanding of the transformer structure — particularly the encoder part — is useful for growing an understanding of imaginative and prescient transformers. On this part, I’ll describe the core elements of a transformer, proven within the determine under. Though this description assumes using textual knowledge, completely different enter modalities (e.g., flattened picture patches, as in imaginative and prescient transformers) can be used.
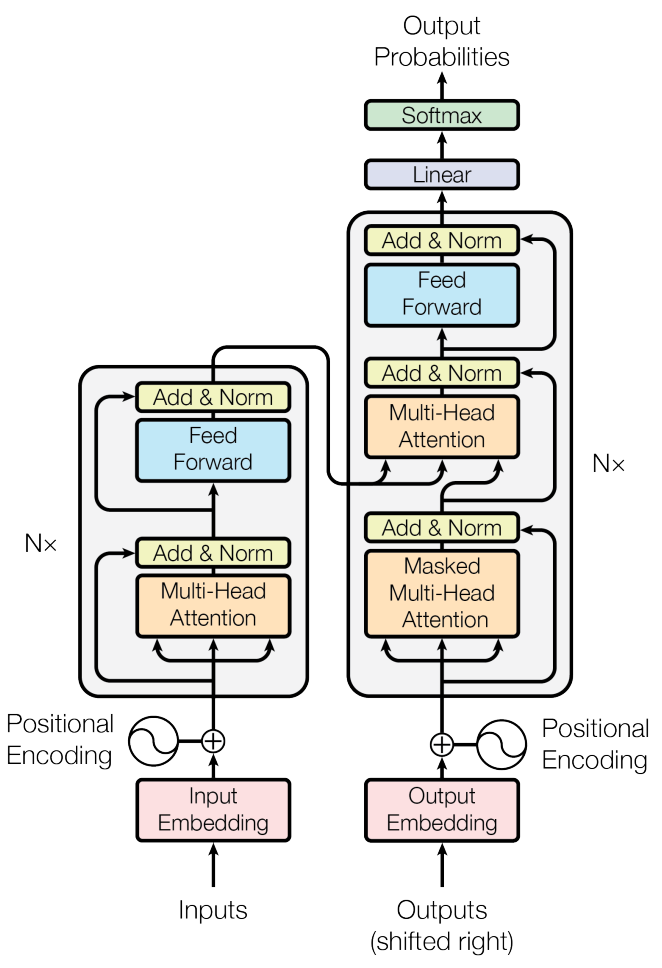
establishing the enter. The transformer takes a sequence of tokens as enter. These tokens are generated by passing textual knowledge (e.g., one or a number of sentences) by a tokenizer that divides it into particular person tokens. Then, these tokens, every related to a novel integer ID, are transformed into their corresponding embedding vectors by indexing a learnable embedding matrix based mostly on the token IDs, forming an (N x d) matrix of enter knowledge (i.e., N tokens, every represented with a vector of dimension d).
Usually, a whole mini-batch of measurement (B x N x d), the place B is the batch measurement, is handed to the transformer directly. To keep away from points with completely different sequences having completely different lengths, all sequences are padded (i.e., utilizing zero or random values) to be of an identical size N. Padded areas are ignored by self-attention.
As soon as the enter is tokenized and embedded, one ultimate step should be carried out — including positional embeddings to every enter token. Self-attention has no notion of place — all tokens are thought of equally regardless of their place. As such, learnable place embeddings should be added to every enter token to inject positional info into the transformer.

the encoder. The encoder portion of the transformer has many repeated layers of an identical construction. Particularly, every layer accommodates the next modules:
- Multi-Headed Self-Consideration
- Feed-Ahead Neural Community
Every of those modules are adopted by layer normalization and a residual connection. By passing the enter sequence by these layers, the illustration for every token is reworked utilizing:
- the representations of different, related tokens within the sequence
- a realized, multi-layer neural community that implements non-linear transformation of every particular person token
When a number of of such layers are utilized in a row, these transformations produce a ultimate output sequence of an identical size with context-aware representations for every token.
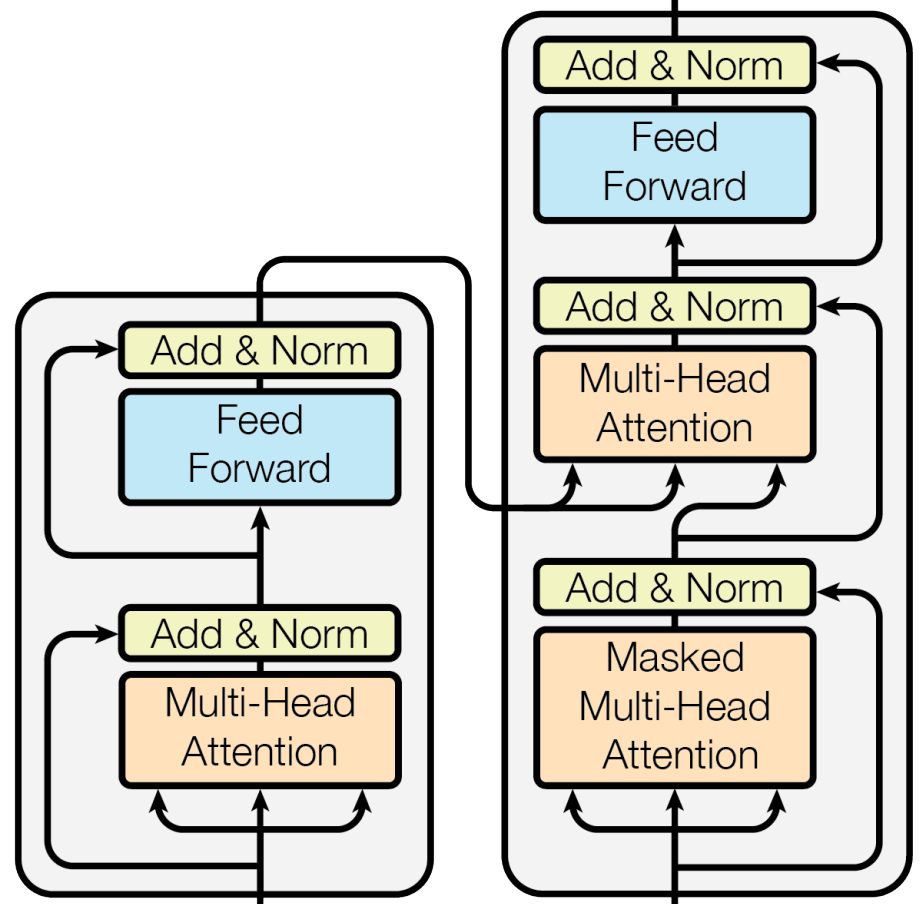
the decoder. Decoders aren’t related to imaginative and prescient transformers, which encoder-only architectures. Nonetheless, we are going to briefly overview the decoder structure right here for completeness. Equally to the encoder, the transformer’s decoder accommodates a number of layers, every with the next modules:
- Masked Multi-Head Consideration
- Multi-Head Encoder-Decoder Consideration
- Feed-Ahead Neural Community
Masked Self-Consideration is just like regular/bi-directional self-attention, but it surely prevents “trying forward” within the enter sequence (i.e., that is vital for sequence-to-sequence duties like language translation). Every token can solely be tailored based mostly on tokens that come earlier than it within the enter sequence. Encoder-decoder self-attention can be fairly just like regular self-attention, however representations from the encoder are additionally used as enter, permitting info from the encoder and the decoder to be fused. Then, the results of this computation is once more handed by a feed-forward neural community.
completely different structure variants. Along with the sequence-to-sequence transformer mannequin described on this part, many architectural variants exist that leverage the identical, primary elements. For instance, encoder-only transformer architectures, generally utilized in language understanding duties, fully discard of the decoder portion of the transformer, whereas decoder-only transformer architectures are generally used for language era. Imaginative and prescient transformer usually leverage an encoder-only transformer structure, as there isn’t any generative part that requires using masked self-attention.
self-supervised pre-training
Although transformers have been initially proposed for sequence-to-sequence duties, their reputation expanded drastically because the structure was later utilized to issues like textual content era and sentence classification. One of many main causes for the widespread success of transformers was using self-supervised pre-training methods.
Self-supervised duties (e.g., predicting masked phrases; see determine above) might be constructed for coaching transformers over uncooked, unlabeled textual content knowledge. As a result of such knowledge is broadly accessible, transformers could possibly be pre-trained over huge portions of textual knowledge earlier than being fine-tuned on supervised duties. Such an thought was popularized by BERT [7], which achieved surprising enhancements in pure language understanding. Nonetheless, this method was adopted in lots of later transformer functions (e.g., GPT-3 [9]).
Apparently, regardless of the huge influence of self-supervised studying in pure language functions, this method has not been as profitable in imaginative and prescient transformers, although many works have tried the concept [11, 12].
some revolutionary transformer functions…
With a primary grasp on the transformer structure, it’s helpful to place into perspective the drastic influence that this structure has had on deep studying analysis. Initially, the transformer structure was popularized by its success in language translation [4]. Nonetheless, this structure has continued to revolutionize quite a few domains inside deep studying analysis. A couple of notable transformer functions (in chronological order) are listed under:
- BERT makes use of self-supervised pre-training to study high-quality language representations [paper][code]
- GPT-2/3 make the most of decoder-only transformer architectures to revolutionize generative language modeling [blog][paper]
- AlphaFold2 makes use of a transformer structure to resolve the long-standing protein folding downside [paper][code]
- DALLE-2 leverages CLIP latents (and diffusion) to realize surprising ends in multi-modal era [blog][paper]
Though the functions of transformers are huge, the primary takeaway that I need to emphasize is easy: transformers are extraordinarily efficient at fixing all kinds of various duties.
An Picture is Price 16×16 Phrases: Transformers for Picture Recognition at Scale [1]
Though the transformer structure had a large influence on the pure language processing area, the extension of this structure into pc imaginative and prescient took time. Preliminary makes an attempt fused fashionable CNN architectures with self-attention modules to create a hybrid method, however these methods have been outperformed by ResNet-based CNN architectures.
Past integrating transformer-like elements into CNN architectures, a picture classification mannequin that instantly makes use of the transformer structure was proposed in [1]. The Imaginative and prescient Transformer (ViT) mannequin divides the underlying picture right into a set of patches, every of that are flattened and projected (linearly) to a hard and fast dimension. Then, a place embedding is added to every picture patch, indicating every patch’s location within the picture. Just like some other transformer structure, the mannequin’s enter is only a sequence of vectors; see under.
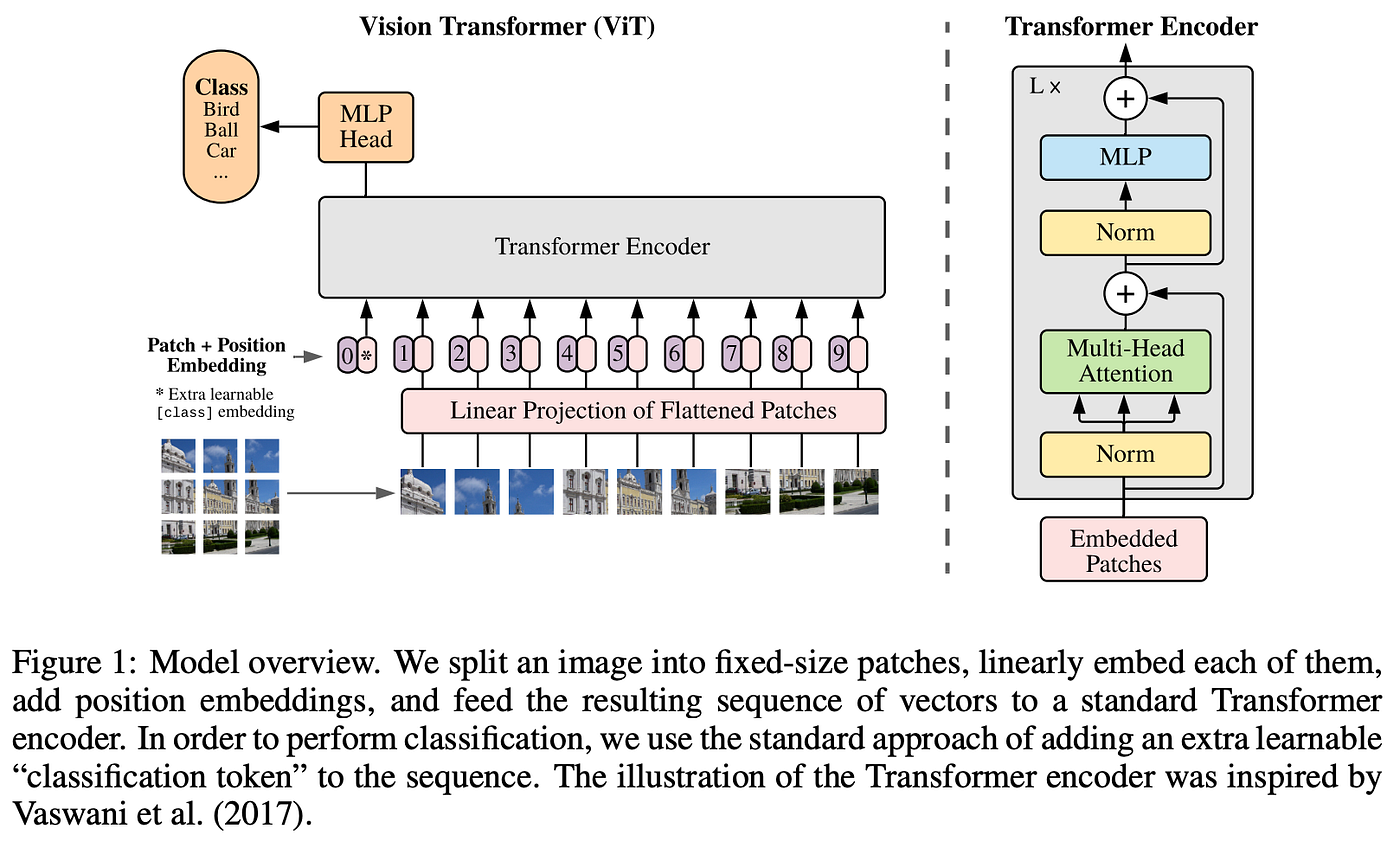
The authors undertake BERT base and huge [7] (i.e., encoder-only transformer architectures) for his or her structure, which is then skilled by attaching a supervised classification head to the primary token within the mannequin’s output. For coaching, a two step pre-training and fine-tuning process is adopted. Both the JFT-300M (very giant), ImageNet-21K (giant), or ImageNet-1K (medium) dataset is used for supervised pre-training. Then, the mannequin is fine-tuned on some goal dataset (e.g., Oxford Flowers or CIFAR-100), after which ultimate efficiency is measured.
With out pre-training over ample knowledge, the proposed mannequin doesn’t match or exceed state-of-the-art CNN efficiency. Such a pattern is probably going resulting from the truth that, whereas CNNs are naturally invariant to patterns like translation and locality, transformers haven’t any such inductive bias and should study these invariances from the info. Because the mannequin is pre-trained over extra knowledge, nevertheless, efficiency enhance drastically, finally surpassing the accuracy of CNN-based baselines even with decrease pre-training value; see the outcomes under.
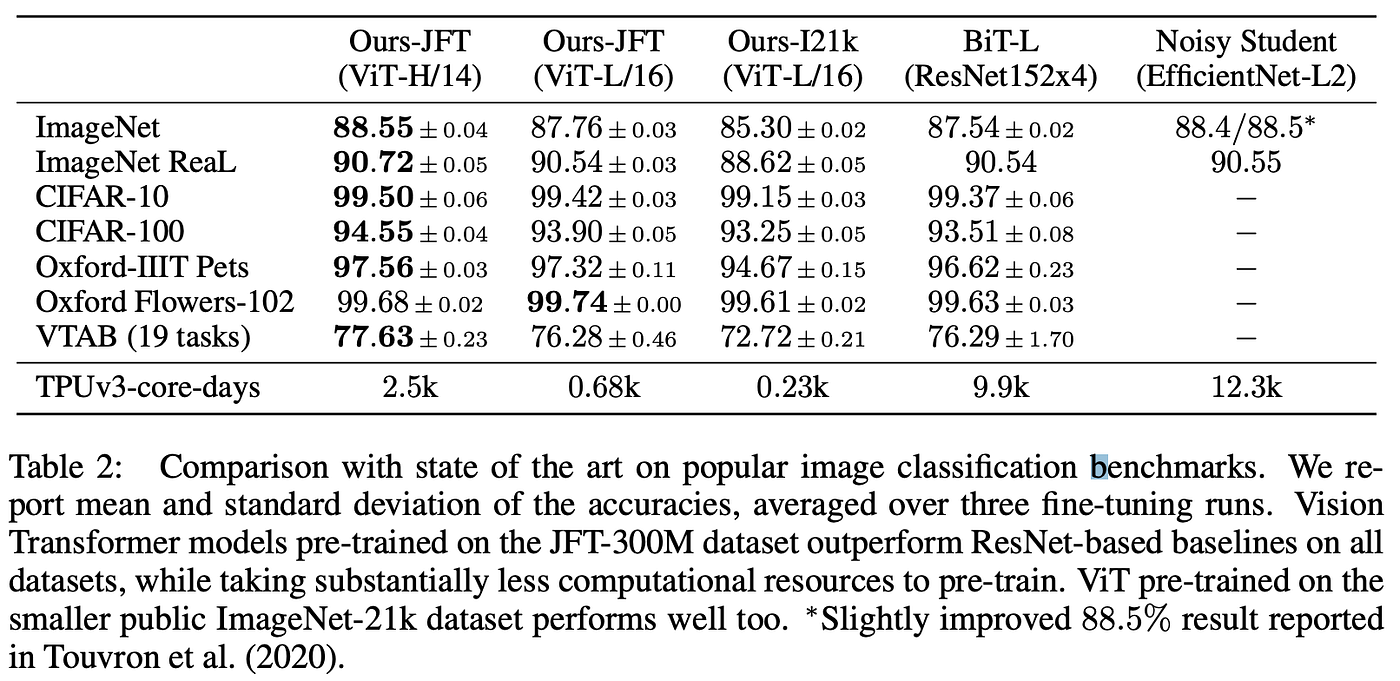
Coaching data-efficient picture transformers & distillation by consideration [2]
Though imaginative and prescient transformers have been demonstrated to be efficient for picture classification in earlier work, such outcomes relied upon in depth pre-training over exterior datasets. For instance, one of the best ViT fashions carried out pre-training over the JFT-300M dataset that accommodates 300 million pictures previous to fine-tuning and evaluating the mannequin on downstream duties.
Though prior work claimed that in depth pre-training procedures have been vital, authors inside [3] provided another proposal, known as the Knowledge-efficient Picture Transformer (DeiT), that leverages a curated information distillation process to coach imaginative and prescient transformers to excessive Prime-1 accuracy with none exterior knowledge or pre-training. Actually, the total coaching course of might be accomplished in three days on a single pc.
The imaginative and prescient transformer structure used on this work is sort of an identical to the ViT mannequin. Nonetheless, an additional token is added to the enter sequence, which is known as the distillation token; see the determine under.
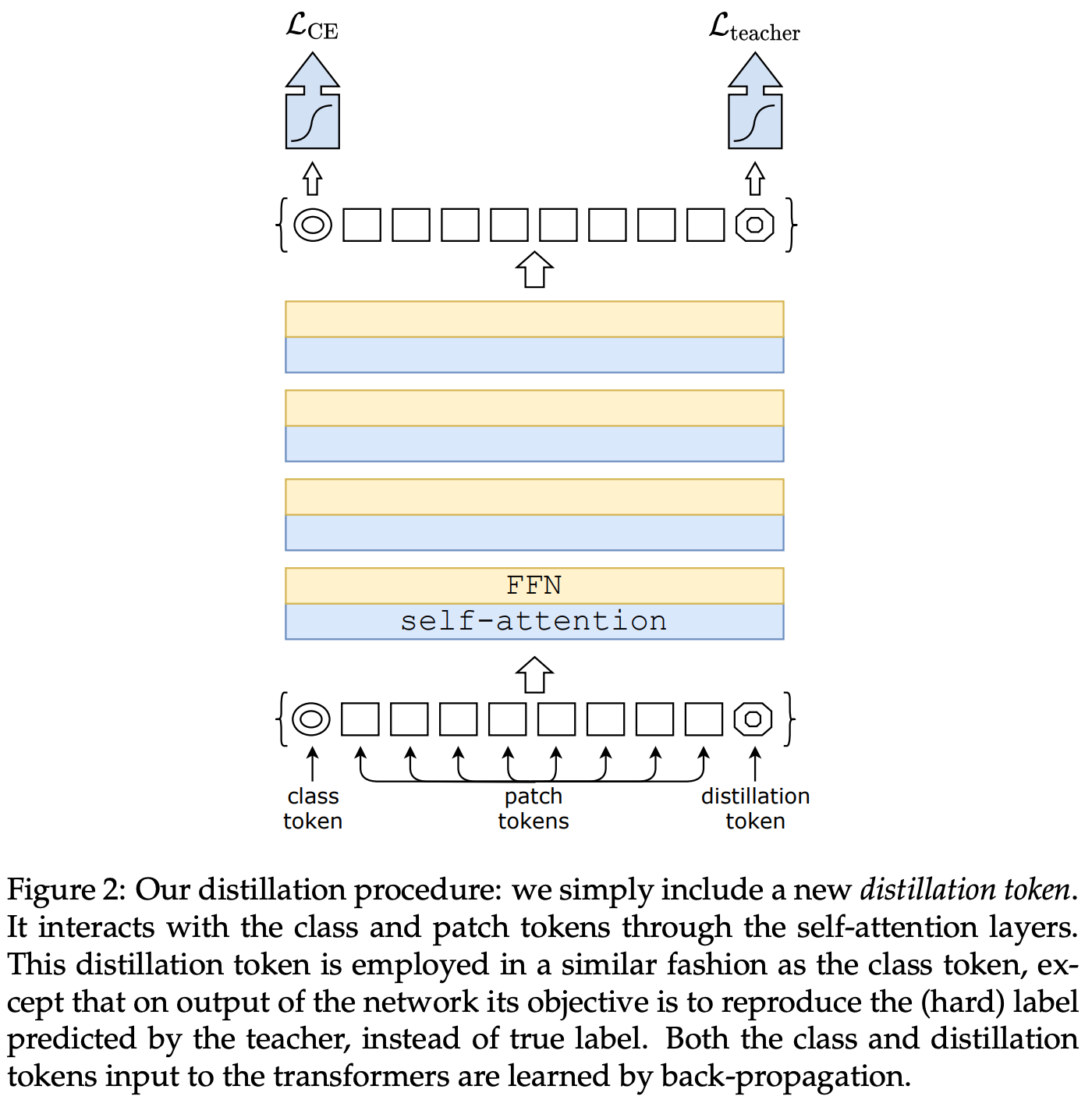
This token is handled identically to the others. However, after exiting the ultimate layer of the transformer, it’s used to use a distillation part to the community’s loss. Particularly, a tough distillation (i.e., versus tender distillation) loss is adopted that trains the imaginative and prescient transformer to duplicate the argmax output of some instructor community (usually a CNN).
At take a look at time, the token output for the category and distillation tokens are fused collectively and used to foretell the community’s ultimate output. The DeiT mannequin outperforms a number of earlier ViT variants which might be pre-trained on giant exterior datasets. DeiT achieves aggressive efficiency when pre-trained on ImageNet and fine-tuned on downstream duties. In different phrases, it achieves compelling efficiency with out leveraging exterior coaching knowledge.
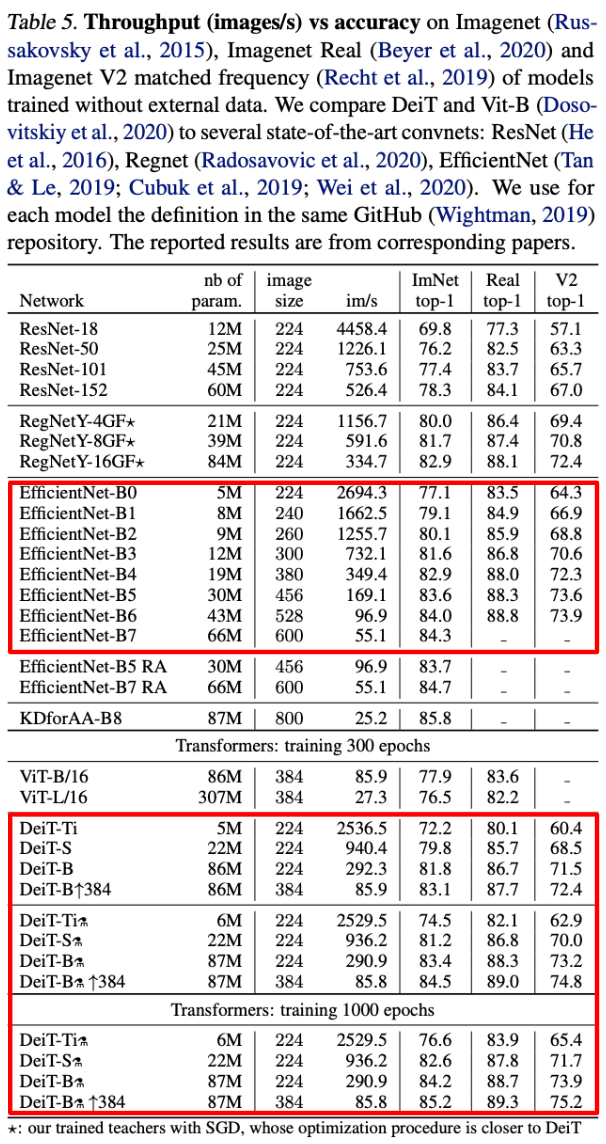
Past its spectacular accuracy, the modified studying technique in DeiT can be fairly environment friendly. Contemplating the throughput (i.e., pictures processed by the mannequin per second) of varied completely different picture classification fashions, DeiT achieves a steadiness between throughput and accuracy that’s just like the widely-used EfficientNet [4] mannequin; see the determine under.
Studying Transferable Visible Fashions From Pure Language Supervision [3]
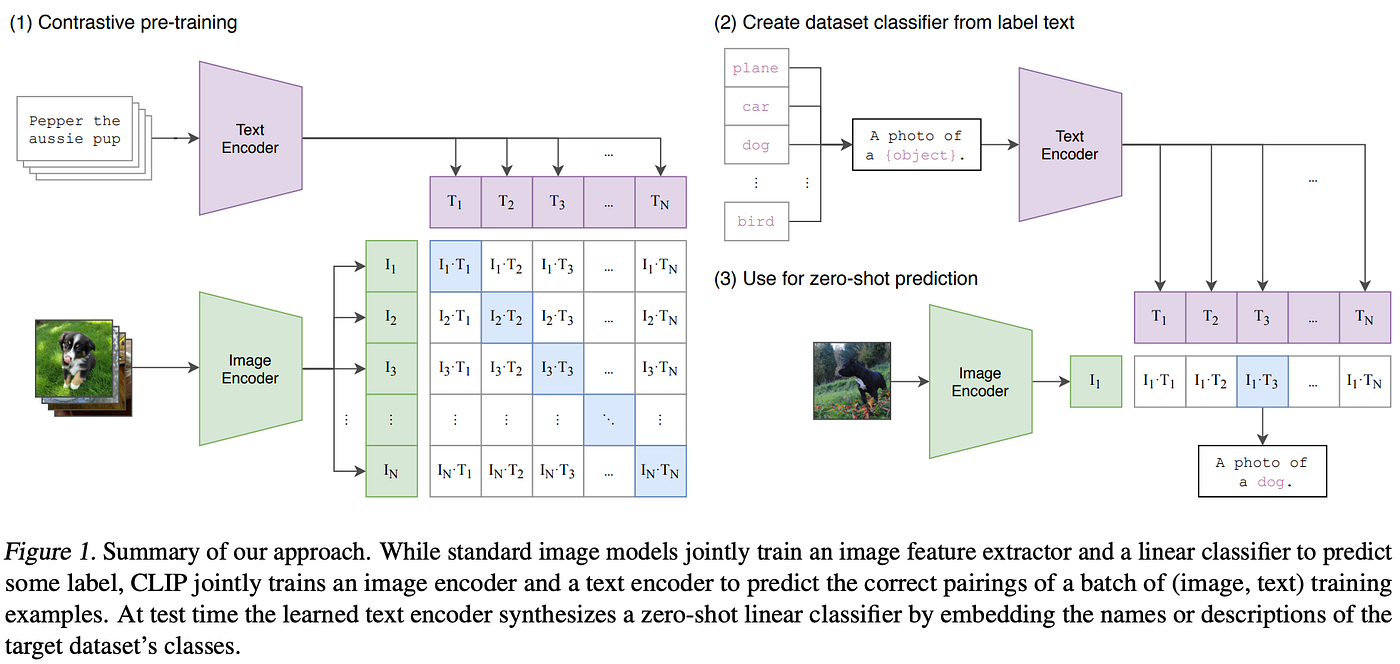
The Contrastive Language-Picture Pre-training Mannequin (CLIP) — just lately re-popularized resulting from its use in DALLE-2–was the primary to indicate that enormous numbers of noisy image-caption pairs can be utilized for studying high-quality representations of pictures and textual content. Earlier work struggled to correctly leverage such weakly-supervised knowledge, resulting from using poorly-crafted pre-training duties; e.g., instantly predicting every phrase of the caption utilizing a language mannequin. CLIP presents a extra easy pre-training job — matching pictures to the proper caption inside a gaggle of potential captions. This simplified job gives a greater coaching sign to the mannequin that permits high-quality picture and textual representations to be realized throughout pre-training.
The mannequin used inside CLIP has two important elements–a picture encoder and a textual content encoder; see the determine above. The picture encoder is both carried out as a CNN or a imaginative and prescient transformer mannequin. Nonetheless, authors discover that the imaginative and prescient transformer variant of CLIP achieves improved computational effectivity throughout pre-training. The textual content encoder is a straightforward decoder-only transformer structure, that means that masked self-attention is used inside the transformer’s layers. The authors select to make use of masked self-attention in order that the textual part of CLIP might be prolonged to language modeling functions sooner or later.
Utilizing this mannequin, the pre-training job is carried out by individually encoding pictures and captions, then making use of a normalized, temperature-scaled cross entropy loss to match picture representations to their related caption representations. The ensuing CLIP mannequin revolutionized zero-shot efficiency for picture classification, enhancing zero-shot take a look at accuracy on ImageNet from 11.5% to 76.2%. To carry out zero-shot classification, authors merely:
- Encode the title of every class utilizing the textual content encoder
- Encoder the picture utilizing the picture encoder
- Select the category that maximizes the cosine similarity with the picture encoding
Such a process is depicted inside the determine above. For extra info on CLIP, please see my earlier overview of the mannequin.
ViTs work … however are they sensible?
Personally, I used to be initially fairly skeptical of utilizing imaginative and prescient transformers, regardless of being conscious of their spectacular efficiency. The coaching course of appeared too computationally costly. Many of the compute value of coaching imaginative and prescient transformers, nevertheless, is related to pre-training. In [2], authors eradicated the necessity for in depth pre-training and instantly demonstrated that the coaching throughput of imaginative and prescient transformers was akin to highly-efficient CNN architectures like EfficientNet. Thus, imaginative and prescient transformers are a viable and sensible deep studying device, as their overhead doesn’t important surpass that of a traditional CNN.
Though transformer are broadly profitable in pure language processing, this overview ought to (hopefully) talk the actual fact that also they are helpful for pc imaginative and prescient duties. CNNS are a tough baseline to beat, as they obtain spectacular ranges of efficiency in an environment friendly — each by way of knowledge and compute — method. Nonetheless, current modifications to the imaginative and prescient transformer structure, as outlined in [2], have made clear that imaginative and prescient transformers carry out favorably relative to CNNs and are literally fairly environment friendly.
imaginative and prescient transformers in code. For individuals who are excited about implementing and/or taking part in round with imaginative and prescient transformer architectures, I might suggest beginning right here. This tutorial means that you can (i) obtain pre-trained ViT parameters and (ii) fine-tune these parameters on downstream imaginative and prescient duties. I discover the code on this tutorial fairly easy to comply with. One can simply prolong this code to completely different functions, and even implement among the extra advanced coaching procedures overviewed inside [2] or different work.
future papers to learn. Though a number of of my favourite imaginative and prescient transformer works have been overviewed inside this publish, the subject is fashionable and a whole bunch of different papers exist. A couple of of my (different) private favorites are:
- Pyramid Imaginative and prescient Transformer: A Versatile Spine for Dense Prediction with out Convolutions [paper]
- Tokens-to-Token ViT: Coaching Imaginative and prescient Transformers from Scratch on ImageNet [paper]
- Mlp-mixer: An all-mlp structure for imaginative and prescient [paper]
Conclusion
Thanks a lot for studying this text. For those who appreciated it, please comply with my Deep (Studying) Focus publication, the place I choose a single, bi-weekly matter in deep studying analysis, present an understanding of related background info, then overview a handful of fashionable papers on the subject. I’m Cameron R. Wolfe, a analysis scientist at Alegion and PhD pupil at Rice College finding out the empirical and theoretical foundations of deep studying. You too can take a look at my different writings on medium!
[1] Dosovitskiy, Alexey, et al. “A picture is price 16×16 phrases: Transformers for picture recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[2] Touvron, Hugo, et al. “Coaching data-efficient picture transformers & distillation by consideration.” Worldwide Convention on Machine Studying. PMLR, 2021.
[3] Radford, Alec, et al. “Studying transferable visible fashions from pure language supervision.” Worldwide Convention on Machine Studying. PMLR, 2021.
[4] Vaswani, Ashish, et al. “Consideration is all you want.” Advances in neural info processing programs 30 (2017).
[5] Tan, Mingxing, and Quoc Le. “Efficientnet: Rethinking mannequin scaling for convolutional neural networks.” Worldwide convention on machine studying. PMLR, 2019.
[6] Lin, Zhouhan, et al. “A structured self-attentive sentence embedding.” arXiv preprint arXiv:1703.03130 (2017).
[7] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[8] Radford, Alec, et al. “Language fashions are unsupervised multitask learners.” OpenAI weblog 1.8 (2019): 9.
[9] Brown, Tom, et al. “Language fashions are few-shot learners.” Advances in neural info processing programs 33 (2020): 1877–1901.
[10] Ramesh, Aditya, et al. “Hierarchical text-conditional picture era with clip latents.” arXiv preprint arXiv:2204.06125 (2022).
[11] Chen, Xinlei, Saining Xie, and Kaiming He. “An empirical research of coaching self-supervised imaginative and prescient transformers.” Proceedings of the IEEE/CVF Worldwide Convention on Laptop Imaginative and prescient. 2021.
[12] Caron, Mathilde, et al. “Rising properties in self-supervised imaginative and prescient transformers.” Proceedings of the IEEE/CVF Worldwide Convention on Laptop Imaginative and prescient. 2021.

{kind=link}