go_backwards() — Unravelling its ‘hidden’ secrets and techniques
Understanding its hidden nuances & exploring its leaky nature!
Introduction
Lengthy Brief Time period Reminiscence (LSTM) are superior variations of Recurrent Neural Networks (RNN) and are able to storing ‘context’, because the title suggests, over comparatively lengthy sequences. This permits them to be an ideal utility for NLP duties comparable to doc classification, speech recognition, Named Entity Recognition (NER), and so forth.
In lots of purposes, comparable to machine translation, speech recognition, and so forth., context from either side improves the efficiency of the language primarily based fashions. To implement this in follow, we use Bi-Directional LSTMs. Nonetheless, if you must extract the embeddings for the ahead and the backward run individually, you would wish to implement two separate LSTMs the place the primary takes in ahead enter and the opposite processes the enter within the backward style.
To save lots of plenty of your effort, Tensorflow’s LSTM provides you the pliability to make use of give the enter usually whereas processing it within the reversed style internally to be taught the context from right-to-left! That is made doable by placing go_backwards( )=True within the LSTM layer. In easy phrases, when you have the enter as [‘I’, ‘am’, ‘the’, ‘author’], then the LSTM would learn it from proper to left, due to go_backwards( ), and treats the enter as [‘author’, ‘the’, ‘am’, ‘I’]. This permits the mannequin to be taught the bi-directional context!
To this point so good. Nonetheless, right here’s a bit of warning! While you add the ahead and reversed contexts within the pipeline, you are likely to leak numerous data within the course of, and this will result in the mannequin giving ~100% accuracy throughout analysis!! It is because we miss understanding the true, refined implementation of go_backwards( ).
On this weblog, I unravel the true implementation of go_backwards( ) utilizing an actual NLP instance and discover how a slight change from anticipated behaviour of go_backwards( ) can result in huge leaks throughout mannequin analysis!
Process: Subsequent Phrase Prediction
Contemplate the subsequent phrase prediction job the place primarily based on the present enter the mannequin must predict the subsequent phrase. The backward path takes in, say, phrase at index 2 of the unique sentence, so it must predict the phrase at index 1 there!

Mannequin Structure
Allow us to think about the next structure. We’ve two separate inputs, one for the ahead path of LSTMs and one other with backward path.

We create or make the most of pre-trained embeddings like Word2Vec, Glove, and so forth. for every phrase, move them by way of the LSTMs, use a skip connection by passing the embeddings by way of a dense layer and including it with LSTM1 outputs, move the sum by way of one other set of LSTM layer, lastly going by way of a standard Softmax layer to get probably the most possible prediction amongst your entire vocabulary!
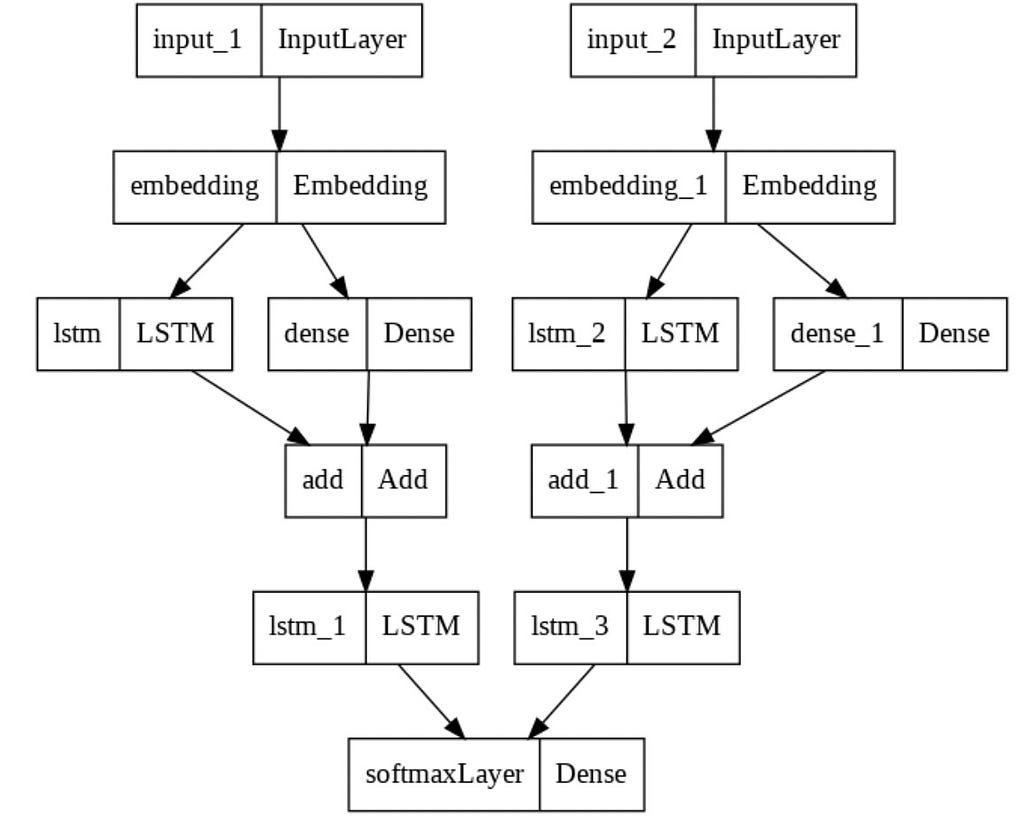
Observations
The above mannequin is educated over the IMDB coaching dataset over 75 epochs with first rate batch dimension, studying charge and early stopping applied. The mannequin coaching stopped round 35 epochs as a consequence of latter. You need to discover the astonishing outcomes for the output from the backward LSTM layers!
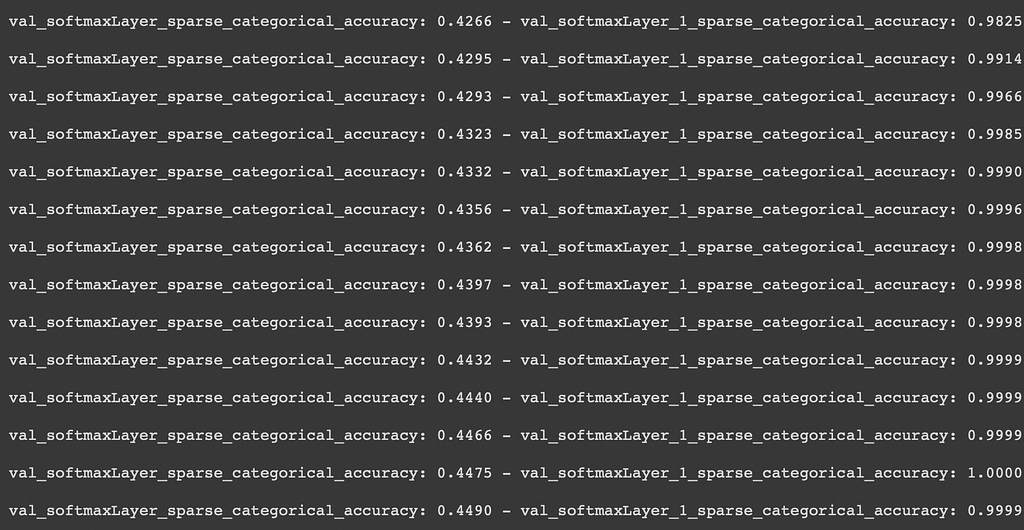
Do you discover that 100% accuracy within the second final row!!! Loopy, proper? That signifies that the mannequin has ‘completely learnt’ the proper sample to offer out the output primarily based on the enter. However subsequent phrase prediction shouldn’t be a job that may be discovered completely. That is like saying prediction of future is feasible with 100% accuracy. 😮
However we all know that there have to be some leakage taking place someplace within the mannequin that the output is already hinted at earlier than. And that’s what I spotted whereas working my undertaking within the course AI-3 (NLP) at Univ.AI. This revelation is the primary agenda of this submit — to determine the WHY behind this unusual behaviour!
One thing secretive about go_backwards( ) ?:
The ahead path LSTM is generally clear by way of the documentation. Nonetheless, the go_backwards( ) perform appears a bit tough. In case you have a look at its documentation, you’ll discover that it takes the inputs sequence within the ahead path, reverses it internally after which processes it, lastly giving out the reversed sequence.


Nonetheless, not like our expectations, reversing the sequence shouldn’t be that easy in LSTMs. As per the official documentation of go_backwards( ), tf.reverse_sequence( ) is the perform used to reverse the inputs and this isn’t a easy reverse. Reasonably than placing all of it proper to left, the perform solely reverse the variety of tokens attributed by ‘sequence size’ and retains remainder of the sentence intact, since different tokens are pad tokens and needn’t be reversed!
The argument go_backwards()=True signifies that the LSTM layer would take within the enter, reverse it utilizing tf.reverse_sequence technique, discover the output by way of the LSTM layer and at last, places the padded tokens in entrance!! This last reverse is made utilizing tf.reverse().
Below-the-Hood: First LSTM
So that is what’s going on under-the-hood whenever you put the go_backwards() argument as True within the first LSTM layer. Notice that we’ve got assumed LSTM to be an id mapper i.e. giving output because the enter. That is performed for ease of illustration and understanding.
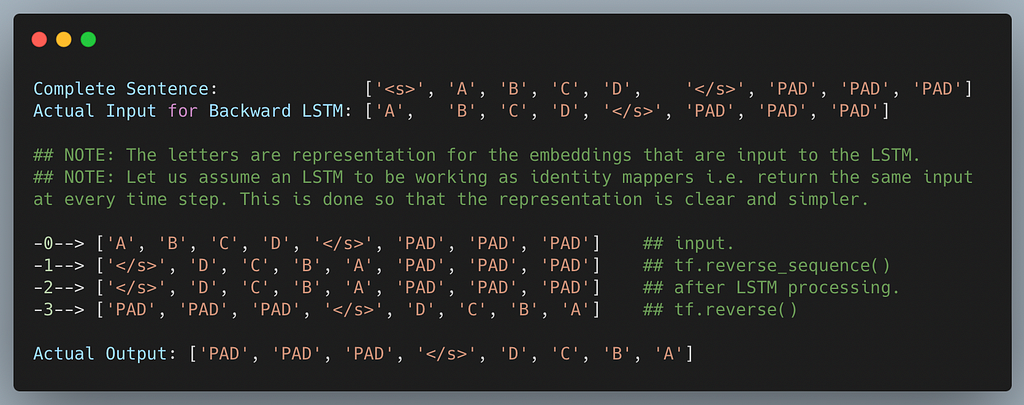
In case you discover rigorously, the output of the LSTM layer with go_backwards()=True is doing its job as talked about within the documentation. The ultimate output is definitely the true reverse (in literal sense) of the output we have been anticipating (taking the belief to be true)
However, slightly than reversing this output, we have been straight utilizing it for a skip connection and utilizing is down the pipeline! And that is the place issues go south!
Zeroing down on the problem!
In our mannequin, we’re including the output (really the reverse output from above xD) to the dense enter simply earlier than passing it to the subsequent backward LSTM. Let’s do a dry-run with our above instance and see how issues work out for the second LSTM layer with the reverse output that you just get from LSTM 1:

Do you discover how the output is symmetric!! Even when we weight the additions and take away the symmetry, you received’t have the ability to escape the LSTM2!

Now suppose PAD=0, <s>=1, A=2, B=3, C=4, D=5, </s>=6 (numericals for simplicity) then the inputs is:

Given the enter of line 0, how tough would it not be for a neural community of the value of LSTM to seek out the sample within the output? 😌 That is the explanation the second LSTM layer catches up extraordinarily quick and goes to just about 100% validation accuracy!!
And the foundation of the issue was that the output of an LSTM with go_backwards()=True is reversed in nature, as talked about within the documentation. It’s essential flip it earlier than passing it by way of!
Experimentation
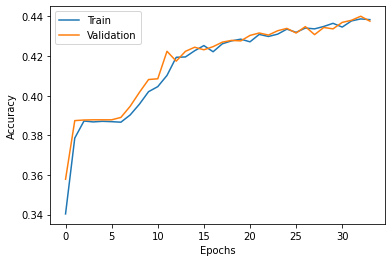
I manually flipped the outputs of the 2 LSTM layers, with go_backwards()=True, on axis=1 and received about 44% accuracy for each layers over 75 epochs with early stopping. Later, I noticed the next outcomes for threee totally different switch studying implementations over IMDB dataset for sentiment classification:
1. Baseline: 85.75%
2. Word2Vec: 84.38%
3. ELMo: 80.17% [using embeddings from the embeddings layer, concatenated outputs of first LSTM’s forward and reverse runs, and the concatenated outputs of second LSTM.
(about 50 epochs with early stopping)

If you are interested in understanding in detail what runs under-the-hood of a fancy LSTM, check out the proceeding link:
Moral of the story!
Always carefully read the documentation before implementation! 🤓
Know your tools well before you use them! 🙂
LSTM go_backwards() — Unravelling its ‘hidden’ secrets was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.

{kind=link}