
How you can Successfully Talk Knowledge with Tables (together with Cheat Sheet)

On the finish of your information evaluation, it is advisable to determine the way to talk your findings. Tables might be extra appropriate than graphs for speaking information while you want your viewers to lookup particular person exact values and examine them to different values. Nevertheless, tables include lots of info that your viewers processes by studying, which makes it tough to your viewers to grasp your message instantly. Random design of the desk, equivalent to too many colours, daring borders, or an excessive amount of info, can moreover distract your viewers. Nevertheless, purposeful utilization of formatting and styling can information your viewers’s consideration to crucial quantity in a desk.
Purposeful utilization of formatting and styling can information your viewers’s consideration to crucial quantity in a desk.
DataFrames from the pandas library are nice to visualise information as tables in Python. Moreover, the pandas library supplies strategies to format and elegance the DataFrame by way of the model attribute. Subsequently, this text discusses important strategies to format and elegance pandas DataFrames to successfully talk information.
If you wish to mess around with the strategies describes on this article, you may obtain or fork this text’s code together with the instance dataset from my associated Kaggle Pocket book.
For this tutorial, we will probably be utilizing the next small fictional dataset:

Earlier than you get began with customizing the visualizations for particular person DataFrames, you may alter the worldwide show habits of pandas with the .set_option() methodology [1]. Two widespread duties you may deal with are:
- displaying all columns of a DataFrame and
- adjusting the width of a DataFrame column.
When your DataFrame has too many columns, pandas doesn’t render all columns however as a substitute hides columns within the center. To power pandas to show all columns, you may set:
pd.set_option("show.max_columns", None)
When you find yourself working with lengthy texts, pandas truncates the textual content within the column. To power pandas to show the complete column contents by growing the column width, you may set:
pd.set_option("show.max_colwidth", None)
The DataFrame’s model attribute, returns an object of the category Styler. This class comprises varied formatting and styling strategies. The next ideas apply to all strategies of the Styler object.
You may mix a number of stylings by chaining a number of strategies collectively.
E.g. df.model.set_caption(...).format(...).bar(...).set_properties(...)
By default, the styling is utilized column-wise (axis = 0).
df.model.highlight_max() # default is axis = 0

If you wish to apply the styling row-wise, use axis = 1 within the properties as a substitute.
df.model.highlight_max(axis = 1))

By default, the styling strategies are utilized to all columns.
df.model.background_gradient()

If you wish to apply the stylings solely to 1 column or a particular subset of columns, use the subset parameter.
df.model.background_gradient(subset = ["A", "D"]))

Earlier than we start with any particular coloring, let’s take a look at some basic formatting strategies to make your DataFrame look extra polished.
Including a caption to a desk is crucial to supply some context to your viewers. You may add the caption to the DataFrame with the .set_caption() methodology.
df.model.set_caption("Caption Textual content")

If the column names are variable names or abbreviated, it may not be clear to your viewers what information they’re . Giving the columns intuitive column names, can help your viewers’s understanding of the info.
There are two choices to rename your columns:
- Renaming all columns without delay
- Renaming solely a subset of columns
If it is advisable to work with the DataFrame afterward, it’d make sense to create a replica of the DataFrame for visualization functions solely.
# Create a replica of the DataFrame for visualization functions
df_viz = df.copy()
You may rename all columns without delay by altering the columns attribute:
# Rename all columns
df_viz.columns = ["New Column Name A",
"New Column Name B",
"New Column Name C",
"New Column Name D"]
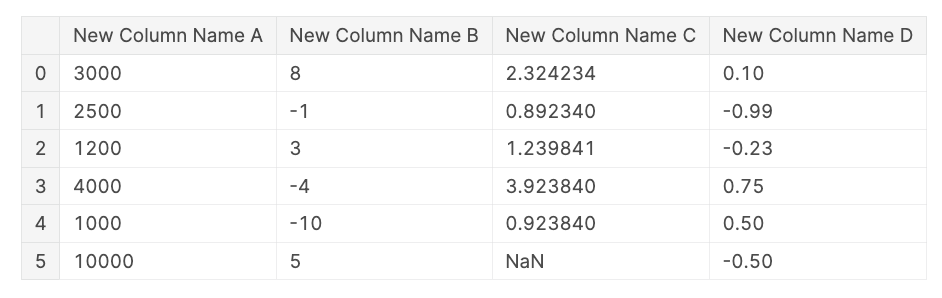
Or you may rename solely a subset of columns with the .rename() methodology and a dictionary.
# Rename number of columns
df_viz.rename(columns = {"A" : "New Column Title A",
"B" : "New Column Title B"},
inplace = True)

Does the index add any beneficial info? If not, you may disguise the index with the .hide_index() methodology.
df.model.hide_index()

Including thousands-separators or truncating the floating-point numbers to fewer decimal locations can improve the readability of your DataFrame. For this function, the Styler object can distinguish the show values from the precise values.
By utilizing the .format() methodology you may manipulate the show values in keeping with a format spec string [3]. You may even add a unit earlier than or after the quantity as a part of the formatting.
df.model.format({"A" : "{:,.0f}",
"B" : "{:d} $",
"C" : "{:.3f}",
"D" : "{:.2f}"})

Nevertheless, to not disturb the eye, I might suggest placing the unit in sq. brackets within the column identify, e.g., “Wage [$]”.
Typically, all you wish to do is perhaps to spotlight a single column within the DataFrame by adjusting the background and font colour. For this function, you should use the .set_properties() methodology to regulate the related CSS properties of the DataFrame equivalent to colours, fonts, borders, and so on.
df.model.set_properties(subset = ["C"],
**{"background-color": "lightblue",
"colour" : "white",
"border" : "0.5px strong white"})

The Model class has some built-in strategies for widespread styling duties.
Highlighting particular person cells is a simple option to information your viewers’s consideration to what you wish to present. Widespread values you would possibly wish to spotlight are minimal, most, and null values. For these circumstances, you should use the respective built-in strategies.
You may alter the spotlight colour with the parameter colour for minimal and most highlighting and nullcolor for null highlighting.
df.model.highlight_null(null_color = "yellow")
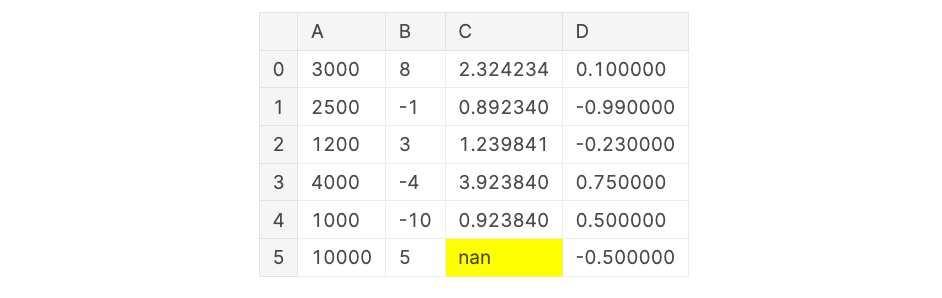
If you wish to spotlight each minimal and most values, you are able to do so by chaining each features collectively.
df.model.highlight_min(colour = "pink")
.highlight_max(colour = "inexperienced")

Including gradient types will help the viewers perceive the connection of the numerical values inside the desk, a single column or a single row. For instance, gradients can point out whether or not a price is massive or small, optimistic or unfavourable, and even good or dangerous.
There are additionally two strategies so as to add gradients to the DataFrame:
- You may apply gradient types both to the textual content or
- you may apply gradient types to the background [2].
With the cmap parameter and vmin and vmax you may set the properties of the gradient. The cmap units the used colormap and vmin and vmax set the related begin and finish values.
You may apply gradients to the textual content with the .text_gradient() methodology:
df.model.text_gradient(subset = ["D"],
cmap = "RdYlGn",
vmin = -1,
vmax = 1)

Or you may apply gradients to the background with the .background_gradient() methodology:
df.model.background_gradient(subset = ["D"],
cmap = "RdYlGn",
vmin = -1,
vmax = 1)

One other means of visualizing the connection and order inside a column or a row is to attract bars within the cell’s background [2].
Once more, there are two important strategies to make the most of bars in your DataFrames:
- The easy utility is to make use of a regular uni-colored bar.
- Or you can even create bi-colored bar charts from a mid-point.
For the usual bar chart, easy use the .bar() methodology as follows:
df.model.bar(subset = ["A"],
colour = "lightblue",
vmin = 0)

To create bi-colored bar charts set the alignment to mid and outline colours for the decrease and higher values. When utilizing this methodology, I like to recommend combining it with some borders to extend the readbility.
df.model.bar(subset = ["D"],
align = "mid",
colour = ["salmon", "lightgreen"])
.set_properties(**{'border': '0.5px strong black'})

If the built-in styling strategies are usually not ample to your wants, you may write your individual styling operate and apply it to the DataFrame. You may both apply styling element-wise with the .applymap() methodology or column- or row-wise with the .apply() methodology [2].
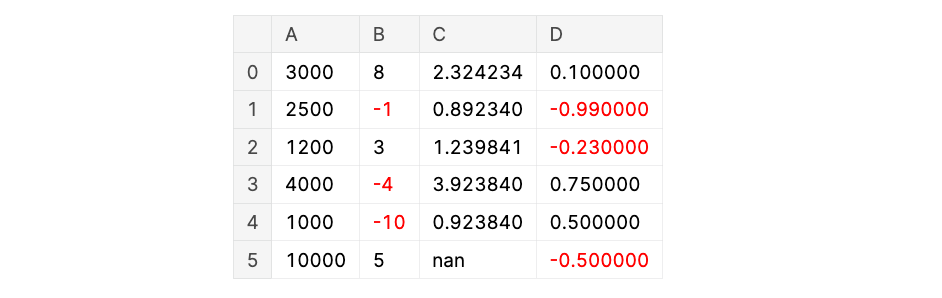
A well-liked instance of that is to show unfavourable values of a DataFrame in pink colour as proven beneath:
def custom_styling(val):
colour = "pink" if val < 0 else "black"
return f"colour: {colour}"df.model.applymap(custom_styling)
In case you want your styled DataFrame in Excel format, you may export it together with its styling and formatting to an .xlsx file [3]. For this, it is advisable to have the openpyxl bundle put in.
pip set up openpyxl
To export the DataFrame, you may apply the styling and formatting to your DataFrame as traditional and comply with it with the .to_excel() methodology.
df.model.background_gradient(subset = ["D"],
cmap = "RdYlGn",
vmin = -1,
vmax = 1)
.to_excel("styled.xlsx", engine = "openpyxl")
The pandas DataFrame’s model attribute allows you to format and elegance a DataFrame to successfully talk the insights out of your information evaluation. This text mentioned important strategies to model pandas DataFrames together with the way to set international show choices, format and customise stylings, and even the way to export your DataFrame to Excel format. There are various extra styling and formatting choices out there on the pandas documentation.
For additional experimentation, you may obtain or fork this text’s code together with the instance dataset from my associated Kaggle Pocket book.
Beneath I’ve summarized all ideas in a cheat sheet:

[1] “pandas 1.4.2 documentation”, “Choices and settings.” pandas.pydata.org. https://pandas.pydata.org/docs/user_guide/choices.html (accessed June 13, 2022)
[2] “pandas 1.4.2 documentation”, “Model.” pandas.pydata.org. https://pandas.pydata.org/docs/reference/model.html (accessed June 16, 2022)
[3] “pandas 1.4.2 documentation”, “Desk Visualization.” pandas.pydata.org. https://pandas.pydata.org/docs/user_guide/model.html (accessed June 16, 2022)
[4] “Python”, “string — Widespread string operations.” python.org. https://docs.python.org/3/library/string.html#formatspec (accessed June 13, 2022)

{kind=link}