An summary of ETL in healthcare, a important a part of the info lifecycle in scientific knowledge science
That is the second article in my scientific knowledge science collection. Within the first article, I offered a radical overview of the expansive area of scientific knowledge science, and that units the inspiration upon which this version is constructed. In case you are unfamiliar with the realm of scientific knowledge science otherwise you simply desire a quick refresher on the important thing concepts, you would possibly need to have a sneak peek of the introductory article. With that stated, the remainder of the article is organized as follows;
- Common overview of ETL
- ETL in scientific knowledge science/healthcare area
- ETL life cycle
- ETL instruments
- Scientific Information Warehouse
- Challenges with ETL in healthcare.
Common overview of ETL
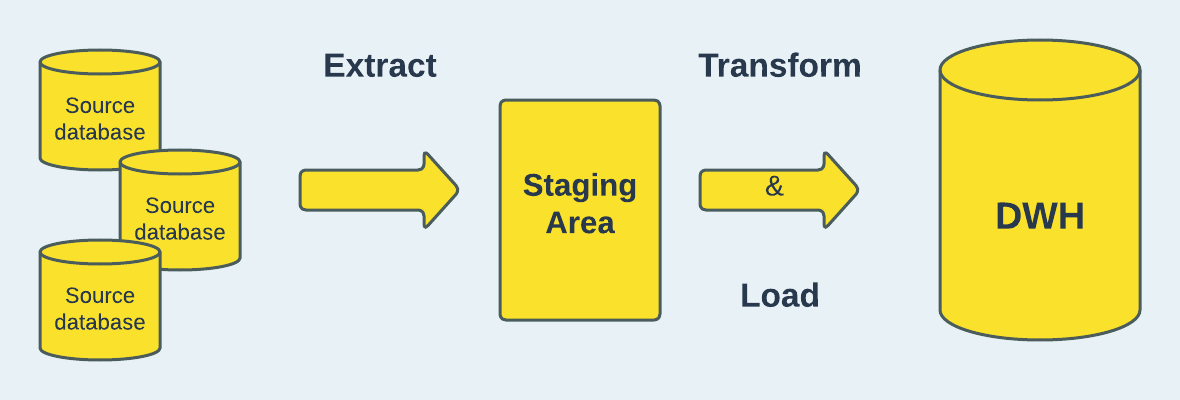
Extract, Remodel and Load (ETL) is a three-stage course of that entails fetching the uncooked knowledge from a number of sources and transferring it to an intermediate, non permanent storage referred to as staging space; remodeling the extracted knowledge to implement knowledge validity requirements and conformity with the goal system; and loading the info into the goal database, usually an information warehouse or repository.
The extract part of ETL offers with exporting and validating the info, the remodel part entails cleansing and manipulating the info to make sure it matches into the goal and the ultimate stage, which is loading entails integrating the extracted and cleaned knowledge into the ultimate vacation spot. This course of is what varieties the inspiration upon which workflows in knowledge analytics is constructed. By way of using a set of technical and enterprise standards, the ETL course of makes certain the info is clear and correctly organized to fulfill the wants of enterprise intelligence.

A typical ETL course of employs a step-by-step strategy which begins by understanding the construction and semantics of the info contained within the supply system. The supply of the info we are attempting to fetch might be an information storage platform, legacy system, cell units, cell apps, net pages, present databases and so forth. After establishing the technical and enterprise necessities, there’s a want to grasp the fitting fields/attributes that meet these requirement and in addition the format through which they’re saved. Many of those codecs, together with relational varieties, XML, JSON, flat recordsdata, and so forth., might be used for the info within the supply system.
In an effort to put together the extracted knowledge for integration into an information warehouse, a collection of guidelines are utilized to scrutinize, cleanse, and arrange the info to make sure solely the ‘match’ knowledge are loaded. Throughout this part, a lot of transformation sorts are utilized. As an illustration, not each area within the supply system can be utilized within the goal system; the transformation course of will look into selecting the exact fields that may be synchronized between the supply and the goal. A very good illustration of it is a scenario the place now we have a area named “date_of_birth” within the supply system which is a date worth making up the yr, month and date of delivery of a person. Whereas, within the goal system, the fields are damaged down into “year_of_birth”, “month_of_birht”, and “day_of_birth” fields. In our transformation pipeline, we’ll have to create a rule for breaking down the one area within the supply system to the corresponding three fields within the goal system to make sure they’re in conformity.

After extraction and transformation, the info is able to be loaded into the goal system both for querying or additional analytics processing. As beforehand acknowledged, the most common instance of a goal system is an information warehouse, which merely serves as a repository for knowledge that has been compiled from a wide range of sources. Extra on this later.
ETL in scientific knowledge science/healthcare area
Answering health-related questions requires a radical understanding of the sophisticated nature of the info generated within the healthcare business, in addition to how the info from the supply system are organized within the vacation spot database. ETL is important within the healthcare business to export knowledge from one supply, usually an EHR, and remodel it right into a type that’s suitable with the goal database’s construction, the place the info shall be saved, both for later use or provided in a presentation-ready format. EHR, which provides info on folks’s well being state, is an important info supply within the healthcare business, as was talked about within the first collection. Information from EHRs give each practitioners and researchers the prospect to reinforce affected person outcomes and health-related decision-making.
ETL in healthcare will be so simple as combining knowledge from a number of departments in a scientific setting to enhance decision-making, or as refined as integrating knowledge from a lot of EHR techniques right into a Frequent Information Fashions (CDMs) comparable to these of the Observational Medical Outcomes Partnership (OMOP), Informatics for Integrating Biology and the Bedside (i2b2), Mini-Sentinel (MS) and the Affected person Centered Consequence Analysis Community (PCORNet), that are usually utilized by analysis networks for the aim of knowledge-sharing and analysis.
In an effort to populate the goal database for extraction and supply the mappings between the supply knowledge and goal knowledge parts, the extract part of ETL in healthcare entails defining the appropriate fields within the supply knowledge (comparable to EHR or claims knowledge) by people with area experience.
As described by Toan et al., after figuring out the right knowledge parts to map to the goal database, engineers/database programmers outline the principles/strategies for knowledge transformation and the schema mappings for loading knowledge into the harmonized schema. To evolve to the goal schema format and codes to allow them to be put into the goal database, transformation is a fancy course of of information “cleansing” (e.g., knowledge de-duplication, battle decision), standardization(e.g., native terminology mapping). This stage necessitates handbook database programming utilizing languages like structured question language (SQL). These processes are steadily repeated till the altered knowledge are acknowledged as complete and correct.
Within the context of scientific science, integrating knowledge from disparate sources is a demanding process that requires a number of iterations within the ETL course of. These iteration processes steadily have their very own difficulties, which can be attributable to inaccurate mappings, prolonged question instances, and knowledge high quality issues. Incorrect mappings often stem from compatibility conflicts between the supply knowledge and the vacation spot system through which case the supply database typically have totally different knowledge illustration, vocabularies, phrases for knowledge parts, and ranges of information granularity.
ETL life cycle
On the granular stage, the ETL course of entails a number of iterations beginning with ETL specification, knowledge extractions, knowledge validation, ETL rule creation, question technology (with SQL), testing & debugging, and knowledge high quality reporting.
- ETL specs is a doc gathering needed info for growing ETL scripts.
- Information validation in easy phrases, is the method of making certain that the info that’s transported as a part of ETL course of is constant, appropriate, and full within the goal manufacturing dwell techniques to serve the enterprise necessities.
- Rule creation and question technology entails creating the principles for knowledge extraction and implementing the principles utilizing (mostly with SQL).
- The testing and debugging ensures that the info is correct, reliable, and constant throughout the info pipeline, together with the info warehouse and migration levels. By measuring the effectiveness of your complete ETL course of, we could discover any bottlenecks and be sure that the process is ready to scale with the growing volumes of information.
- Information high quality reporting offers the account of any high quality flaws discovered through the ETL course of and that is needed to make sure knowledge integrity. To extra precisely mirror its dimensions and influences, knowledge high quality is acknowledged as multi-dimensional. Every dimension has a set of metrics that allow its evaluation and measurement.
In scientific knowledge science, knowledge high quality issues can happen by way of accessibility, validity, freshness, relevance, completeness, consistency, reliability and integrity. The scientific knowledge high quality is a important difficulty as a result of it impacts the choice making and reliability of analysis.
ETL Instruments
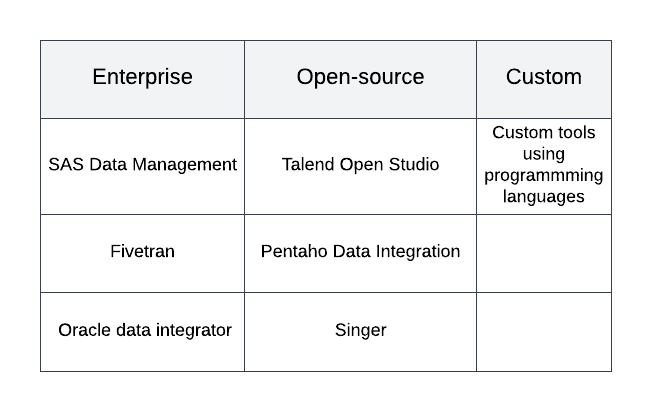
ETL instruments are technological options designed to facilitate the ETL processes. When used appropriately, ETL applied sciences supply a constant strategy to knowledge consumption, sharing, and storage, which simplifies knowledge administration strategies and enhances knowledge high quality. Industrial companies produce and supply assist for a number of the ETL instruments which might be available. They provide a wide range of capabilities, together with a Graphical Consumer Interface (GUI) for growing ETL pipelines, assist for relational and non-relational databases, and a wealthy documentation. They’re fairly strong and mature in design. Examples of those embody SAS Information Administration, Fivetran, Oracle knowledge integrator, and so forth.
As a consequence of excessive price ticket and the extent of coaching required to make use of enterprise-built ETL instruments, different options embody utilizing open supply software program like Talend Open Studio, Pentaho Information Integration, Singer, or Hadoop. Nevertheless, open-source instruments would possibly fail to fulfill up with the precise wants of a corporation. As well as, since open-source ETL applied sciences are steadily not backed by for-profit companies, their upkeep, documentation, usability, and usefulness can range.
As argued by Toan et al. of their paper, an information integration resolution with a GUI, can facilitate the ETL course of and reduce the handbook workload related to the ETL design course of. Nevertheless, GUI-based applied sciences steadily lack the flexibleness wanted to deal with complicated transformation operation wants, comparable to distinctive protocols for performing knowledge de-duplication or incremental knowledge loading. Moreover, it is perhaps difficult to judge transformation points with GUI-based instruments since they steadily lack transparency of the underlying question instructions executing the transformation.
If an institution values management over flexibility extremely, they could design an inside resolution if they’ve the required growth assets. The flexibility to create an answer that’s particular to the group’s priorities and processes is the principle good thing about this strategy. In style programming languages like SQL, Python, and Java can be utilized for this. The first drawback of this technique is the inner assets required for testing, upkeep, and updates of a bespoke ETL device.
Scientific Information Warehouse (CDW)
An information warehouse is a set of previous knowledge that has been organized for reporting and analysis. It makes knowledge entry simpler by bringing collectively, and linking, knowledge from varied sources thereby making them simply accessible. One of the essential instruments for decision-making by stakeholders throughout many disciplines is an information warehouse (DW). Information within the DW are mixed and represented in multidimensional type, facilitating fast and easy show and evaluation.
In line with Wikipedia, a Scientific Information Warehouse (CDW) or Scientific Information Repository (CDR) is an actual time database that consolidates knowledge from a wide range of scientific sources to current a unified view of a single affected person. It’s optimized to permit clinicians to retrieve knowledge for a single affected person moderately than to determine a inhabitants of sufferers with widespread traits or to facilitate the administration of a particular scientific division. Typical knowledge sorts which are sometimes discovered inside a CDR embody: scientific laboratory check outcomes, affected person demographics, pharmacy info, radiology experiences and pictures, pathology experiences, hospital admission, discharge and switch dates, ICD-9 codes, discharge summaries, and progress notes.
The CDW can function a base for documenting, conducting, planning, and facilitating scientific analysis. Moreover, CDW improves scientific decision-making whereas streamlining knowledge evaluation and processing. In standard ETL initiatives, the extracted and remodeled knowledge are loaded into an information warehouse (DW); nonetheless, in scientific knowledge science, the info are loaded right into a scientific knowledge warehouse (CDW). The info imported into the CDW is pretty much as good because the scientific choice and analysis it’s being utilized for, therefore it’s essential that each one elements of the ETL course of are completely executed.
Challenges with ETL in healthcare
It’s acknowledged that knowledge harmonization operations is a demanding process that consumes a number of assets. As such, there was a number of work executed prior to now to deal with the challenges related to ETL in healthcare.
In line with Toan et al., the standard technical challenges of an ETL course of embody compatibility between the supply and goal knowledge, supply knowledge high quality, and scalability of the ETL course of.
Whereas many EHR techniques are versatile of their design, permitting well being personnel, together with medical doctors and nurses the power to enter info in a non-codified method, this results in an absence of uniformity within the knowledge that should be built-in from varied sources, which is why compatibility is an issue. There could also be inconsistencies within the supply system resulting from fields, vocabularies, and terminology which might be conflicting between techniques. Compatibility points may result in info loss if the goal knowledge system is unable to successfully combine the supply knowledge.
Owing to the truth that well being knowledge is often of excessive quantity and there’s a continuing updates and operational adjustments within the supply system, designing and sustaining a device that may adapt to the rising knowledge dimension and workload, whereas sustaining an inexpensive response time turns into difficult, therefore the problem of scalability.
The info being extracted from the supply could have originated from a system the place the group of the info is solely totally different from the design used within the vacation spot system. Because of this, it’s difficult to make sure the accuracy of the info obtained through ETL procedures. To offer finish customers with knowledge that’s as clear, thorough, and proper as doable, knowledge high quality points that may vary from easy misspellings in textual traits to worth discrepancies, database constraint violations, and contradicting or lacking info should be eradicated.
Step one in resolving these issues is acknowledging their existence and realizing that you’ll in all probability encounter a lot of them when creating an ETL resolution. By concentrating and extracting the info that fulfill the necessities of CDW stakeholders and storing them in a sure format, knowledge high quality could also be ensured.
As argued by Fred Nunes in his weblog publish, the absence of high-quality knowledge pipelines for the time being is the most important barrier to the widespread adoption of the out there cutting-edge approaches within the healthcare sector. This impediment shouldn’t be inherent to the business, neither is it related to its practitioners or sufferers
Conclusion
On this collection, we went over the basics of ETL earlier than displaying how it’s utilized in healthcare. Then, we examined the ETL instruments and the combination of the extracted knowledge right into a repository as the method’s last output. I made the purpose that ETL in scientific knowledge science and healthcare is delicate to knowledge integrity and high quality since low-quality knowledge can have a detrimental impact on a corporation’s decision-making course of or the outcomes of the research the info is utilized for. The complexity of scientific knowledge construction and variety of medical operations requires implementation of complicated ETL earlier than the info are loaded into CDW storage.
References
Information Pipelines within the Healthcare Business (daredata.engineering)
A Survey of Extract-Remodel-Load Know-how. (researchgate.web)
ETL Challenges inside Healthcare Enterprise Intelligence — Well being IT Solutions
13 Finest ETL Instruments for 2022 (hubspot.com)
ETL Testing Information Warehouse Testing Tutorial (A Full Information) (softwaretestinghelp.com)

{kind=link}