Now I do know as a lot about cash laundering as the typical individual on the road, which is to say not a lot, so it was an interesting and tedious learn on the identical time. Fascinating due to the dimensions of operations and the numerous large names concerned, and tedious as a result of there have been so many gamers that I had a tough time protecting observe of them as I learn by means of the articles. In any case, I had simply completed some work on my fork of the open supply NERDS toolkit for coaching Named Entity Recognition fashions, and it occurred to me that figuring out the entities on this set of articles and connecting them up right into a graph may assist to make higher sense of all of it. Type of like how folks draw mind-maps when attempting to grasp advanced data. Besides our course of goes to be (principally) automated, and our mind-map may have entities as a substitute of ideas.
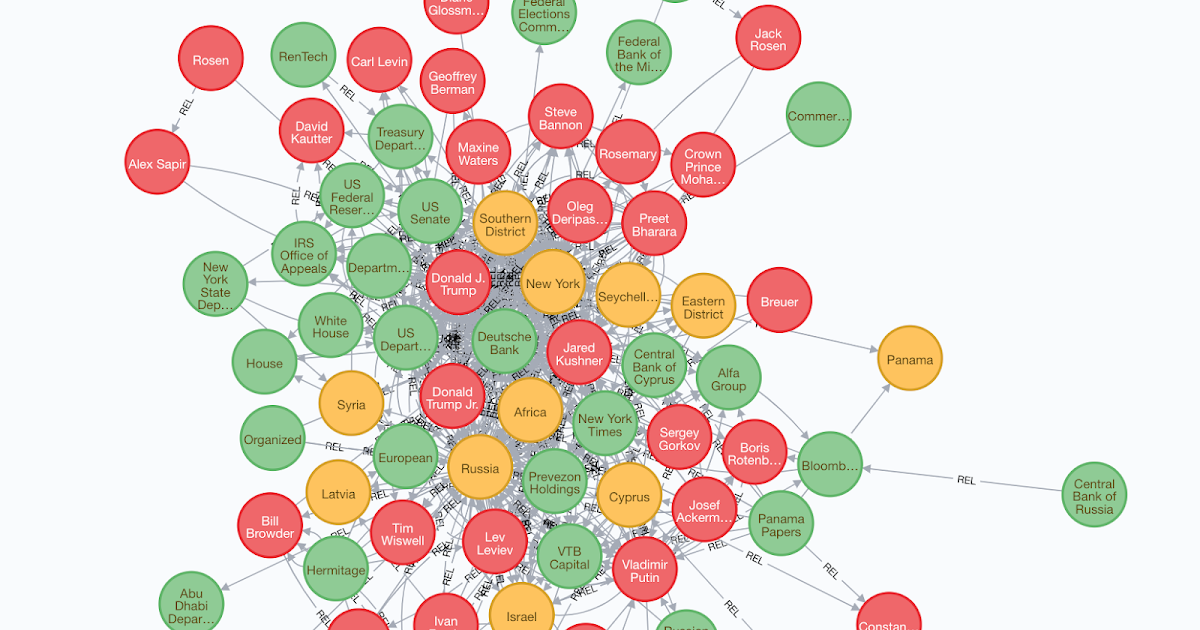
Skipping to the top, right here is the entity graph I ended up constructing, it is a screenshot from the Neo4j internet console. Crimson nodes characterize individuals, inexperienced nodes characterize organizations, and yellow nodes characterize geo-political entities. The perimeters are proven as directed, however after all co-occurrence relationships are bidirectional (or equivalently undirected).
The essential concept is to seek out Named Entities within the textual content utilizing off the shelf Named Entity Recognizers (NERs), and join a pair of entities in the event that they co-occur in the identical sentence. The transformation from unstructured textual content to entity graph is generally automated, apart from one step within the center the place we manually refine the entities and their synonyms. The graph information was ingested right into a Neo4j graph database, and I used Cypher and Neo4j graph algorithms to generate insights from the graph. On this publish I describe the steps to transform from unstructured article textual content to entity graph. The code is supplied on GitHub, and so is the the info for this instance, so you need to use them to glean different attention-grabbing insights from this information, in addition to rerun the pipeline to create entity graphs on your personal textual content.
I structured the code as a sequence of Python scripts and Jupyter notebooks which might be utilized to the info. Every script or pocket book reads the info recordsdata already out there and writes new information recordsdata for the subsequent stage. Scripts are numbered to point the sequence through which they need to be run. I describe these steps beneath.
As talked about earlier, the enter is the textual content from the three articles listed above. I display screen scraped the textual content into a neighborhood textual content file (choose the article textual content after which copy the textual content, then paste it into a neighborhood textual content editor, and eventually saved it into the file db-article.txt. The textual content is organized into paragraphs, with an empty line delimiting every paragraph. The primary article additionally supplied a set of acronyms and their expansions, which I captured equally into the file db-acronyms.txt.
- 01-preprocess-data.py — this script reads the paragraphs and converts it to an inventory of sentences. For every sentence, it checks to see if any token is an acronym, and if that’s the case, it replaces the token with the enlargement. The script makes use of the SpaCy sentence segmentation mannequin to section the paragraph textual content into sentences, and the English tokenizer to tokenize sentences into tokens. Output of this step is an inventory of 585 sentences within the sentences.txt file.
- 02-find-entities.py — this script makes use of the SpaCy pre-trained NER to seek out cases of Particular person (PER), Group (ORG), GeoPolitical (GPE), Nationalities (NORP), and different varieties of entities. Output is written to the entities.tsv file, one entity per line.
- 03-cluster-entity-mentions.ipynb — on this Jupyter pocket book, we do easy rule-based entity disambiguation, in order that related entity spans discovered within the final step are clustered underneath the identical entity — for instance, “Donald Trump”, “Trump”, and “Donald J. Trump”, are all clustered underneath the identical PER entity for “Donald J. Trump”. The disambiguation finds related spans of textual content (Jaccard token similarity) and considers these above a sure threshold to discuss with the identical entity. Probably the most frequent entity varieties discovered are ORG, PERSON, GPE, DATE, and NORP. This step writes out every cluster as a key-value pair, with the important thing being the longest span within the cluster, and the worth as a pipe-separated record of the opposite spans. Output from this stage are the recordsdata person_syns.csv, org_syns.csv, and gpe_syns.csv.
- 04-generate-entity-sets.py — That is a part of the guide step talked about above. The *_syns.csv recordsdata include clusters which might be principally appropriate, however as a result of the clusters are based mostly solely on lexical similarity, they nonetheless want some guide modifying. For instance, I discovered the “US Justice Division” and “US Treasury Division” in the identical cluster, however “Treasury” in a distinct cluster. Equally, “Donald J. Trump” and “Donald Trump, Jr.” appeared in the identical cluster. This script re-adjusts the clusters, eradicating duplicate synonyms for clusters, and assigning the longest span as the principle entity identify. It’s designed to be run with arguments so you’ll be able to model the *_syn.csv recordsdata. The repository comprises my ultimate manually up to date recordsdata as gpe_syns-updated.csv, org_syns-updated.csv, and person_syns-updated.csv.
- 05-find-corefs.py — As is typical in most writing, folks and locations are launched within the article, and are henceforth known as “he/she/it”, no less than whereas the context is offered. This script makes use of the SpaCy neuralcoref to resolve pronoun coreferences. We limit the coreference context to the paragraph through which the pronoun happens. Enter is the unique textual content file db-articles.txt and the output is a file of coreference mentions corefs.tsv. Notice that we do not but try and replace the sentences in place like we did with the acronyms as a result of the ensuing sentences are too bizarre for the SpaCy sentence segmenter to section precisely.
- 06-find-matches.py — On this script, we use the *_syns.csv recordsdata to assemble a Aho-Corasick Automaton object (from the PyAhoCorasick module), mainly a Trie construction in opposition to which the sentences will be streamed. As soon as the Automaton is created, we stream the sentences in opposition to it, permitting it to establish spans of textual content that match entries in its dictionary. As a result of we need to match any pronouns as nicely, we first substitute any coreferences discovered within the sentence with the suitable entity, then run the up to date sentence in opposition to the Automaton. Output at this stage is the matched_entities.tsv, a structured file of 998 entities containing the paragraph ID, sentence ID, entity ID, entity show identify, entity span begin and finish positions.
- 07-create-graphs.py — We use the keys of the Aho-Corasick Automaton dictionary that we created within the earlier step to write down out a CSV file of graph nodes, and the matched_entities.tsv to assemble entity pairs inside the identical sentence to write down out a CSV file of graph edges. The CSV recordsdata are within the format required by the neo4j-admin command, which is used to import the graph right into a Neo4j 5.3 neighborhood version database.
- 08-explore-graph.ipynb — We’ve three sorts of nodes within the graph, PERson, ORGanization, and LOCation nodes. On this pocket book, we compute PageRank on every kind of node to seek out the highest folks, organizations, and places we must always take a look at. From there, we choose just a few prime folks and discover their neighbors. One different characteristic we constructed was a search like performance, the place as soon as two nodes are chosen, we present an inventory of sentences the place these two entities cooccur. And eventually, compute the shortest path between a pair of nodes. The pocket book reveals the completely different queries, the related Cypher queries (together with calls to Neo4j Graph algorithms), in addition to the outputs of those queries, its most likely simpler so that you can click on by means of and have a look your self than for me to explain it.
There are clearly many different issues that may be accomplished with the graph, restricted solely by your creativeness (and presumably by your area experience on the topic at hand). For me, the train was enjoyable as a result of I used to be ready to make use of off the shelf NLP elements (versus having to coach my very own compoenent for my area) to resolve an issue I used to be going through. Utilizing the facility of NERs and graphs permits us to achieve insights that might usually not be doable solely from the textual content.

{kind=link}