
Hashing refers back to the means of producing a fixed-size output from an enter of variable measurement utilizing the mathematical formulation often known as hash features. This system determines an index or location for the storage of an merchandise in a knowledge construction.

Want for Hash information construction
Daily, the info on the web is rising multifold and it’s all the time a wrestle to retailer this information effectively. In day-to-day programming, this quantity of information won’t be that massive, however nonetheless, it must be saved, accessed, and processed simply and effectively. A quite common information construction that’s used for such a goal is the Array information construction.
Now the query arises if Array was already there, what was the necessity for a brand new information construction! The reply to that is within the phrase “effectivity“. Although storing in Array takes O(1) time, looking out in it takes at the very least O(log n) time. This time seems to be small, however for a big information set, it might probably trigger loads of issues and this, in flip, makes the Array information construction inefficient.
So now we’re on the lookout for a knowledge construction that may retailer the info and search in it in fixed time, i.e. in O(1) time. That is how Hashing information construction got here into play. With the introduction of the Hash information construction, it’s now attainable to simply retailer information in fixed time and retrieve them in fixed time as effectively.
Parts of Hashing
There are majorly three parts of hashing:
- Key: A Key may be something string or integer which is fed as enter within the hash operate the method that determines an index or location for storage of an merchandise in a knowledge construction.
- Hash Perform: The hash operate receives the enter key and returns the index of a component in an array referred to as a hash desk. The index is named the hash index.
- Hash Desk: Hash desk is a knowledge construction that maps keys to values utilizing a particular operate referred to as a hash operate. Hash shops the info in an associative method in an array the place every information worth has its personal distinctive index.
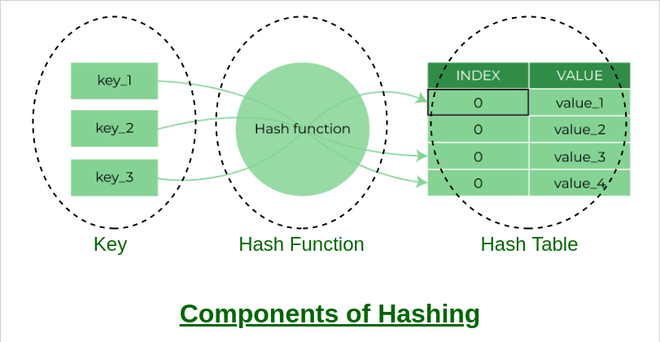
Parts of Hashing
How does Hashing work?
Suppose we’ve got a set of strings {“ab”, “cd”, “efg”} and we wish to retailer it in a desk.
Our important goal right here is to go looking or replace the values saved within the desk shortly in O(1) time and we’re not involved concerning the ordering of strings within the desk. So the given set of strings can act as a key and the string itself will act as the worth of the string however tips on how to retailer the worth comparable to the important thing?
- Step 1: We all know that hash features (which is a few mathematical method) are used to calculate the hash worth which acts because the index of the info construction the place the worth will probably be saved.
- Step 2: So, let’s assign
- “a” = 1,
- “b”=2, .. and many others, to all alphabetical characters.
- Step 3: Due to this fact, the numerical worth by summation of all characters of the string:
- “ab” = 1 + 2 = 3,
- “cd” = 3 + 4 = 7 ,
- “efg” = 5 + 6 + 7 = 18
- Step 4: Now, assume that we’ve got a desk of measurement 7 to retailer these strings. The hash operate that’s used right here is the sum of the characters in key mod Desk measurement. We are able to compute the placement of the string within the array by taking the sum(string) mod 7.
- Step 5: So we’ll then retailer
- “ab” in 3 mod 7 = 3,
- “cd” in 7 mod 7 = 0, and
- “efg” in 18 mod 7 = 4.

Mapping key with indices of array
The above method allows us to calculate the placement of a given string through the use of a easy hash operate and quickly discover the worth that’s saved in that location. Due to this fact the thought of hashing looks like an effective way to retailer (key, worth) pairs of the info in a desk.
What’s a Hash operate?
The hash operate creates a mapping between key and worth, that is carried out by way of the usage of mathematical formulation often known as hash features. The results of the hash operate is known as a hash worth or hash. The hash worth is a illustration of the unique string of characters however often smaller than the unique.
For instance: Contemplate an array as a Map the place the hot button is the index and the worth is the worth at that index. So for an array A if we’ve got index i which will probably be handled as the important thing then we are able to discover the worth by merely wanting on the worth at A[i].
merely wanting up A[i].
Sorts of Hash features:
There are numerous hash features that use numeric or alphanumeric keys. This text focuses on discussing totally different hash features:
Properties of a Good hash operate
A hash operate that maps each merchandise into its personal distinctive slot is named an ideal hash operate. We are able to assemble an ideal hash operate if we all know the gadgets and the gathering won’t ever change however the issue is that there isn’t a systematic strategy to assemble an ideal hash operate given an arbitrary assortment of things. Thankfully, we’ll nonetheless achieve efficiency effectivity even when the hash operate isn’t good. We are able to obtain an ideal hash operate by rising the scale of the hash desk so that each attainable worth may be accommodated. In consequence, every merchandise could have a singular slot. Though this strategy is possible for a small variety of gadgets, it’s not sensible when the variety of prospects is massive.
So, We are able to assemble our hash operate to do the identical however the issues that we have to be cautious about whereas setting up our personal hash operate.
A good hash operate ought to have the next properties:
- Effectively computable.
- Ought to uniformly distribute the keys (Every desk place is equally seemingly for every.
- Ought to decrease collisions.
- Ought to have a low load issue(variety of gadgets within the desk divided by the scale of the desk).
Complexity of calculating hash worth utilizing the hash operate
- Time complexity: O(n)
- Area complexity: O(1)
Downside with Hashing
If we contemplate the above instance, the hash operate we used is the sum of the letters, but when we examined the hash operate intently then the issue may be simply visualized that for various strings similar hash worth is start generated by the hash operate.
For instance: {“ab”, “ba”} each have the identical hash worth, and string {“cd”,”be”} additionally generate the identical hash worth, and many others. This is named collision and it creates drawback in looking out, insertion, deletion, and updating of worth.
What’s collision?
The hashing course of generates a small quantity for an enormous key, so there’s a risk that two keys might produce the identical worth. The scenario the place the newly inserted key maps to an already occupied, and it have to be dealt with utilizing some collision dealing with expertise.
How you can deal with Collisions?
There are primarily two strategies to deal with collision:
- Separate Chaining:
- Open Addressing:
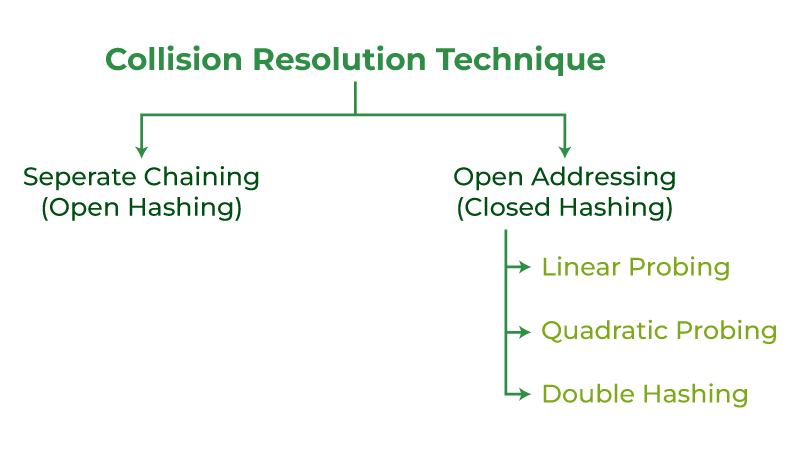
Collision decision method
1) Separate Chaining
The concept is to make every cell of the hash desk level to a linked checklist of data which have the identical hash operate worth. Chaining is easy however requires further reminiscence outdoors the desk.
Instance: We now have given a hash operate and we’ve got to insert some components within the hash desk utilizing a separate chaining methodology for collision decision method.
Hash operate = key % 5, Components = 12, 15, 22, 25 and 37.
Let’s see step-by-step strategy to tips on how to remedy the above drawback:
- Step 1: First draw the empty hash desk which could have a attainable vary of hash values from 0 to 4 in accordance with the hash operate offered.
Hash desk
- Step 2: Now insert all of the keys within the hash desk one after the other. The primary key to be inserted is 12 which is mapped to bucket quantity 2 which is calculated through the use of the hash operate 12percent5=2.
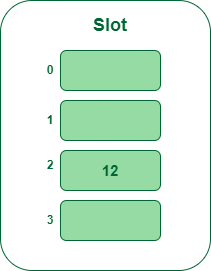
Insert key 12 within the hash desk
- Step 3: The following key’s 15. It’ll map to fit quantity 0 as a result of 15percent5=0. So insert it into bucket quantity 5.
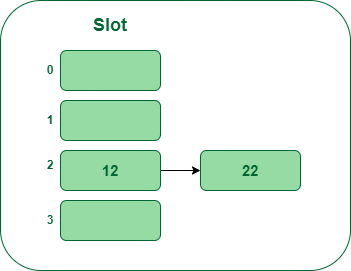
Insert key 15 within the hash desk
- Step 4: Now the subsequent key’s 22. It’ll map to bucket quantity 2 as a result of 22percent5=2. However bucket 2 is already occupied by key 12. So separate chaining methodology will deal with this collision by making a linked checklist to bucket 2.
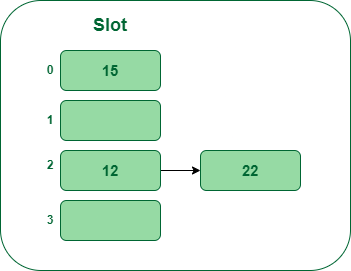
Insert key 22 within the hash desk
- Step 5: Now the subsequent key’s 25. Its bucket quantity will probably be 25percent5=0. However bucket 0 is already occupied by key 25. So separate chaining methodology will once more deal with the collision by making a linked checklist to bucket 0.
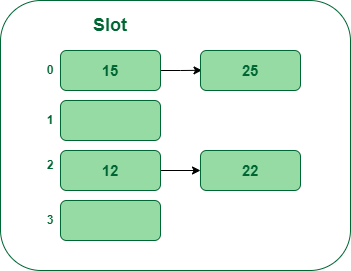
Insert key 25 within the hash desk
Therefore On this method, the separate chaining methodology is used because the collision decision method.
2) Open Addressing
In open addressing, all components are saved within the hash desk itself. Every desk entry incorporates both a report or NIL. When trying to find a component, we study the desk slots one after the other till the specified component is discovered or it’s clear that the component is just not within the desk.
2.a) Linear Probing
In linear probing, the hash desk is searched sequentially that begins from the unique location of the hash. If in case the placement that we get is already occupied, then we examine for the subsequent location.
Algorithm:
- Calculate the hash key. i.e. key = information % measurement
- Verify, if hashTable[key] is empty
- retailer the worth straight by hashTable[key] = information
- If the hash index already has some worth then
- examine for subsequent index utilizing key = (key+1) % measurement
- Verify, if the subsequent index is accessible hashTable[key] then retailer the worth. In any other case strive for subsequent index.
- Do the above course of until we discover the area.
Instance: Allow us to contemplate a easy hash operate as “key mod 5” and a sequence of keys which can be to be inserted are 50, 70, 76, 85, 93.
- Step1: First draw the empty hash desk which could have a attainable vary of hash values from 0 to 4 in accordance with the hash operate offered.
Hash desk
- Step 2: Now insert all of the keys within the hash desk one after the other. The primary key’s 50. It’ll map to fit quantity 0 as a result of 50percent5=0. So insert it into slot quantity 0.
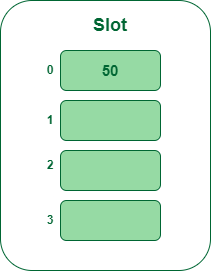
Insert key 50 within the hash desk
- Step 3: The following key’s 70. It’ll map to fit quantity 0 as a result of 70percent5=0 however 50 is already at slot quantity 0 so, seek for the subsequent empty slot and insert it.
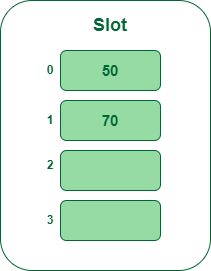
Insert key 70 within the hash desk
- Step 4: The following key’s 76. It’ll map to fit #1 as a result of 76percent5=1 however 70 is already at slot #1 so, seek for the subsequent empty slot and insert it.
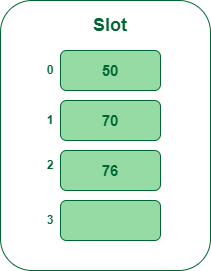
Insert key 76 within the hash desk
- Step 5: The following key’s 93 It’ll map to fit quantity 3 as a result of 93percent5=3, So insert it into slot quantity 3.
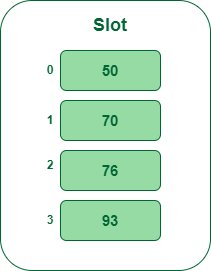
Insert key 93 within the hash desk
2.b) Quadratic Probing
Quadratic probing is an open addressing scheme in pc programming for resolving hash collisions in hash tables. Quadratic probing operates by taking the unique hash index and including successive values of an arbitrary quadratic polynomial till an open slot is discovered.
An instance sequence utilizing quadratic probing is:
H + 12, H + 22, H + 32, H + 42…………………. H + ok2
This methodology is also referred to as the mid-square methodology as a result of on this methodology we search for i2‘th probe (slot) in i’th iteration and the worth of i = 0, 1, . . . n – 1. We all the time begin from the unique hash location. If solely the placement is occupied then we examine the opposite slots.
Let hash(x) be the slot index computed utilizing the hash operate and n be the scale of the hash desk.
If the slot hash(x) % n is full, then we strive (hash(x) + 12) % n.
If (hash(x) + 12) % n can be full, then we strive (hash(x) + 22) % n.
If (hash(x) + 22) % n can be full, then we strive (hash(x) + 32) % n.
This course of will probably be repeated for all of the values of i till an empty slot is discovered
Instance: Allow us to contemplate desk Dimension = 7, hash operate as Hash(x) = x % 7 and collision decision technique to be f(i) = i2 . Insert = 25, 33, and 105
- Step 1: Create a desk of measurement 7.
Hash desk
- Step 2 – Insert 22 and 30
- Hash(25) = 22 % 7 = 1, Because the cell at index 1 is empty, we are able to simply insert 22 at slot 1.
- Hash(30) = 30 % 7 = 2, Because the cell at index 2 is empty, we are able to simply insert 30 at slot 2.
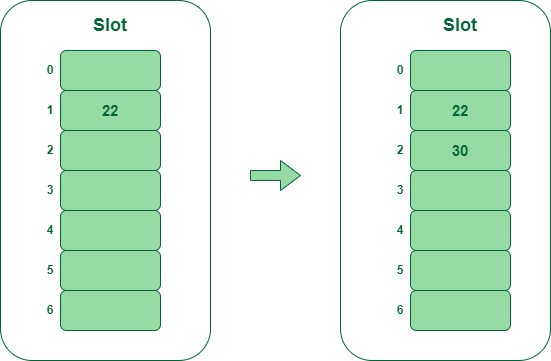
Insert key 22 and 30 within the hash desk
- Step 3: Inserting 50
- Hash(25) = 50 % 7 = 1
- In our hash desk slot 1 is already occupied. So, we’ll seek for slot 1+12, i.e. 1+1 = 2,
- Once more slot 2 is discovered occupied, so we’ll seek for cell 1+22, i.e.1+4 = 5,
- Now, cell 5 is just not occupied so we’ll place 50 in slot 5.
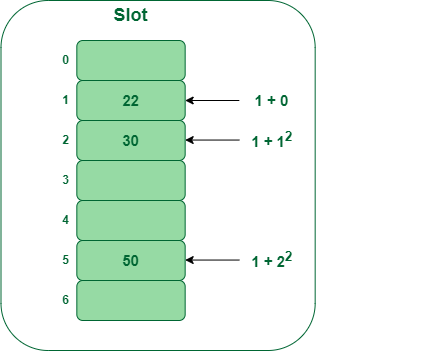
Insert key 50 within the hash desk
2.c) Double Hashing
Double hashing is a collision resolving method in Open Addressed Hash tables. Double hashing make use of two hash operate,
- The primary hash operate is h1(ok) which takes the important thing and offers out a location on the hash desk. But when the brand new location is just not occupied or empty then we are able to simply place our key.
- However in case the placement is occupied (collision) we’ll use secondary hash-function h2(ok) together with the primary hash-function h1(ok) to seek out the brand new location on the hash desk.
This mixture of hash features is of the shape
h(ok, i) = h1(ok) + i * h2(ok)) % n
the place
- i is a non-negative integer that signifies a collision quantity,
- ok = component/key which is being hashed
- n = hash desk measurement.
Complexity of the Double hashing algorithm:
Time complexity: O(n)
Instance: Insert the keys 27, 43, 98, 72 into the Hash Desk of measurement 7. the place first hash-function is h1(ok) = ok mod 7 and second hash-function is h2(ok) = 1 + (ok mod 5)
- Step 1: Insert 27
- 27 % 7 = 6, location 6 is empty so insert 27 into 6 slot.
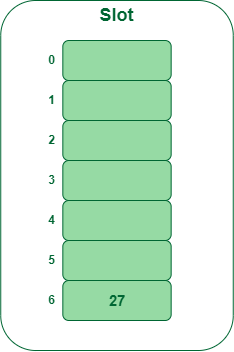
Insert key 27 within the hash desk
- Step 2: Insert 43
- 43 % 7 = 1, location 1 is empty so insert 43 into 1 slot.
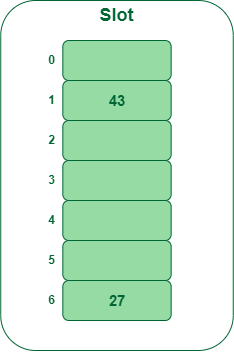
Insert key 43 within the hash desk
- Step 3: Insert 92
- 92 % 7 = 6, however location 6 is already being occupied and this can be a collision
- So we have to resolve this collision utilizing double hashing.
hnew = [h1(92) + i * (h2(92)] % 7 = [6 + 1 * (1 + 92 % 5)] % 7 = 9 % 7 = 2 Now, as 2 is an empty slot, so we are able to insert 92 into 2nd slot.
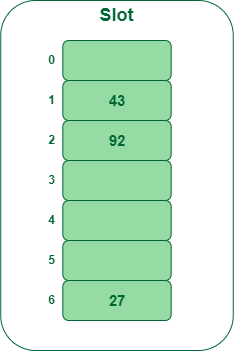
Insert key 92 within the hash desk
- Step 4: Insert 72
- 72 % 7 = 2, however location 2 is already being occupied and this can be a collision.
- So we have to resolve this collision utilizing double hashing.
hnew = [h1(72) + i * (h2(72)] % 7 = [2 + 1 * (1 + 72 % 5)] % 7 = 5 % 7 = 5, Now, as 5 is an empty slot, so we are able to insert 72 into fifth slot.

Insert key 72 within the hash desk
What is supposed by Load Think about Hashing?
The load issue of the hash desk may be outlined because the variety of gadgets the hash desk incorporates divided by the scale of the hash desk. Load issue is the decisive parameter that’s used once we wish to rehash the earlier hash operate or wish to add extra components to the prevailing hash desk.
It helps us in figuring out the effectivity of the hash operate i.e. it tells whether or not the hash operate which we’re utilizing is distributing the keys uniformly or not within the hash desk.
Load Issue = Complete components in hash desk/ Dimension of hash desk
What’s Rehashing?
Because the title suggests, rehashing means hashing once more. Mainly, when the load issue will increase to greater than its predefined worth (the default worth of the load issue is 0.75), the complexity will increase. So to beat this, the scale of the array is elevated (doubled) and all of the values are hashed once more and saved within the new double-sized array to take care of a low load issue and low complexity.
Functions of Hash Information construction
- Hash is utilized in databases for indexing.
- Hash is utilized in disk-based information buildings.
- In some programming languages like Python, JavaScript hash is used to implement objects.
Actual-Time Functions of Hash Information construction
- Hash is used for cache mapping for quick entry to the info.
- Hash can be utilized for password verification.
- Hash is utilized in cryptography as a message digest.
Benefits of Hash Information construction
- Hash gives higher synchronization than different information buildings.
- Hash tables are extra environment friendly than search bushes or different information buildings
- Hash gives fixed time for looking out, insertion, and deletion operations on common.
Disadvantages of Hash Information construction
- Hash is inefficient when there are various collisions.
- Hash collisions are virtually not averted for a big set of attainable keys.
- Hash doesn’t enable null values.
Conclusion
From the above dialogue, we conclude that the purpose of hashing is to resolve the problem of discovering an merchandise shortly in a group. For instance, if we’ve got an inventory of hundreds of thousands of English phrases and we want to discover a explicit time period then we might use hashing to find and discover it extra effectively. It will be inefficient to examine every merchandise on the hundreds of thousands of lists till we discover a match. Hashing reduces search time by limiting the search to a smaller set of phrases originally.


{kind=link}