SQL Server database is a time period you’re in all probability already acquainted with. On the subject of storing massive quantities of information, databases are extraordinarily helpful. And as you’ve discovered, SQL Server’s default settings aren’t at all times one of the best. When working with new consumer databases, that is the case. We are able to outline a database as, In SQL Server, a database can be composed of a set of tables that retailer a specific set of structured knowledge.
Introduction
SQL Server will be put in on a pc in a number of situations. Every SQL Server occasion can have a number of databases.
Principally, a database desk is manufactured from rows, that are additionally known as data or tuples, and columns, that are additionally known as attributes. Each column in a desk is made to carry a selected kind of information, similar to names, dates, and numbers. Each SQL Server database ought to have not less than two working system information: an information file and a log file. The data mandatory to revive all transactions inside the database is saved in log information. For allocation and administration functions, knowledge information can certainly be clustered collectively in filegroups.
To enhance I/O efficiency, SQL Server helps to create supplemental filegroups to disperse knowledge and indexes throughout a number of discs. In the present day we’re going to focus on these filegroups and when to make use of the a number of filegroups. Discover SQL Server Tutorial for extra data.
What’s Filegroup?
In a database, a filegroup is a rational method for grouping objects. Filegroups shouldn’t be confused with precise information (.mdf, .ddf, .ndf, .ldf, and so forth.). Per database, you may even have a number of filegroups. All system tables might be saved in a single filegroup, which would be the major. Then you definately create extra filegroups. You’ll be able to set one filegroup because the default, and objects that aren’t assigned to a filegroup might be positioned in it. You’ll be able to simply have a number of information in a filegroup.
- The first knowledge file is on this filegroup, as are any secondary information that aren’t in different filegroups.
- For administrative, knowledge allocation, and placement functions, user-defined filegroups may very well be shaped to group knowledge information collectively.
If we discuss an example- On three totally different disc drives, Data1.ndf, Data2.ndf, and Data3.ndf may very well be created and allotted to the filegroup fgroup1. The filegroup fgroup1 might then be used to create a desk. The desk’s knowledge queries will even be scattered out throughout three discs, leading to improved efficiency. A single file shaped on a RAID (redundant array of unbiased discs) stripe set can obtain the identical efficiency enchancment. Recordsdata and filegroups, alternatively, make it easy so as to add new information to new discs.
The next desk lists the filegroups the place all knowledge information are saved.:
Major: The first file is contained on this filegroup. The first filegroup accommodates all system tables.
Reminiscence optimized knowledge: The filestream filegroup is the muse for a memory-optimized filegroup.
Consumer outlined: Any filegroup made by the consumer as soon as the database is first created or later modified.
When to Create Filegroup?
- SQL Server accesses knowledge utilizing threads; every thread is chargeable for retrieving or updating knowledge on particular pages at particular places on discs; when you have a number of filegroups and knowledge is unfold throughout the disc, SQL Server can reap the benefits of parallel threads, which improves database efficiency.
- In case you’ve had a be a part of operation that includes a number of tables in a database, placing them multi functional filegroup will maintain SQL Server working in parallel (for essentially the most half); nonetheless, placing the tables in numerous filegroups and putting them on totally different discs or luns will improve operational effectivity towards strongly accessed tables in numerous file teams as a result of SQL Server can use parallel threads.
- Whereas getting ready or updating the database, your database performs poorly. A number of threads can work collectively to retrieve knowledge from totally different file teams on the similar time.
- You may have fairly a desk with a number of years of information, however you might be solely utilizing a couple of latest years of information; that’s very useful when partitioning the desk and indexes. It additionally makes it simpler to archive knowledge and avoids pointless scanning of data that aren’t at the moment essential.
- You may have a big database, and full or disparity backup restoration instances are unacceptable; for those who uncover database corruption of objects associated to a selected filegroup, customers might actually restore simply that file group to revive information shortly.
Be taught extra about SQL from this SQL Server Coaching to get forward in your profession.
The right way to Create Filegroup?
Technique 1: Utilizing T-SQL (Transact-SQL)
|
APPLY grasp GO SQLAge ALTER DATABASE FILEGROUP SQLAgeFG1 ADD GO
|
Technique 2: Utilizing Studio for Administration
- Go to properties by right-clicking on the database you need to create a filegroup in.
- Choose Filegroups from the drop-down menu.
- Choose “Add” from the drop-down menu.
- Give the filegroup an appropriate title and click on OK.
Why Does one Have to Make A number of Filegroups?
Effectiveness and restoration are the 2 essential causes for creating filegroups.
Disk efficiency points will be alleviated through the use of filegroups that include information created on particular discs. For instance, your database might need one very massive desk with lots of learn and write actions, similar to an orders desk. You may make a filegroup, put a file in it, after which transfer a desk to it by transferring the clustered index. (I’ll present you tips on how to do it later on this article.) You’re going to get higher efficiency if the file is created on a separate disc from different information. That is just like the logic utilized in databases to separate knowledge and log information. When you unfold information throughout a number of discs, efficiency improves. As a result of as a substitute of 1 particular person doing all of the work, you’ve gotten quite a few heads studying and writing.
Filegroups can be backed up and restored independently. Within the occasion of a catastrophe, this might permit for sooner object restoration. It may possibly additionally assist within the administration of enormous databases.
The right way to Create A number of Filegroups?
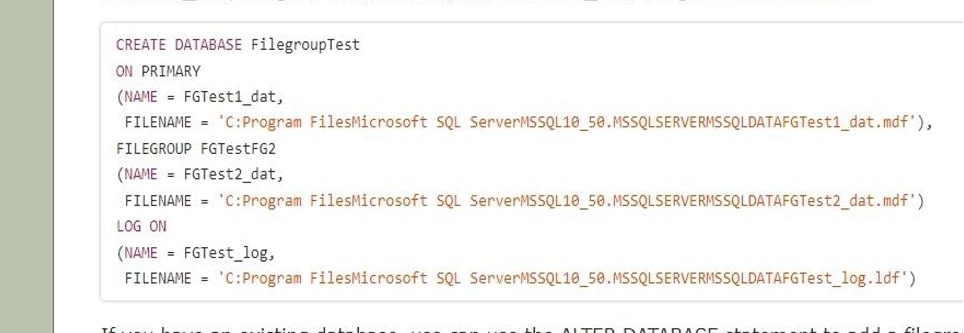
The filegroups will be specified within the CREATE DATABASE assertion when creating a brand new database.
We’re going to make a database known as FilegroupTest. PRIMARY and FGTestFG2 are the 2 filegroups. FGTest1 dat, which is assigned to PRIMARY, and FGTest2 dat, which is assigned to FGTestFG2.

If you have already got a database, you may add a filegroup with the ALTER DATABASE assertion. FGTestFG3 might be added to FilegroupTest.

Utilizing sys.filegroups, you can see the filegroups in a database.

you should use ALTER DATABASE to create a brand new file, FGTest3 dat, and assign it to FGTestFG3.

Advantages of Utilizing A number of Filegroups
- You’ll be able to take full benefit of the I/O bandwidth for each bodily gadget/path to see you’ve positioned filegroups onto by splitting a database throughout a number of filegroups. A number of filegroups on the identical bodily disc / LUN would supply no profit, however a number of discs / LUNs can give you a a number of of the bandwidth of a single disc / LUN.
- You’ll be able to go into nice element, storing elements of the database which can be accessed much less generally on slower “nearline” media and sustaining the higher-activity items (closely used indexes, tables, and so forth) on the costlier, sooner storage.
- An honest indexing tactic can allow the bottom states to develop whereas question instances stay comparatively fixed. In case you discover that the I/O that hosts your filegroups is changing into saturated, you may enhance efficiency by creating extra filegroups on extra discs / LUNs. Monitoring I/O efficiency is the important thing to figuring out if a number of filegroups will profit you. In case you’re CPU-bound or RAM-constrained, a number of filegroups gained’t show you how to. I/O utilization is just one axis of complete efficiency monitoring, and filegroups solely assist with that.
Conclusion
Filegroups are actually a good way to handle your knowledge whereas additionally bettering efficiency and including catastrophe restoration. It’s very best if you are able to do this in the course of the planning levels, however take into account that you too can add filegroups later. Piecemeal restore can be utilized to revive SQL Server databases with a number of filegroups in levels. The piecemeal restore really does work in the identical method as a normal restore, with three phases: knowledge copy, redo and undo. Whereas your database and different filegroups proceed to remain on-line, you may reinstate considered one of your filegroups. Please do not forget that your database should be offline when recovering the PRIMARY filegroup.
Writer Bio:
I’m Sai Priya Ravuri and I’m the content material creator at MindMajix Applied sciences. I maintain in-depth information of Programming, Applied sciences, Enterprise Intelligence, Analytics, Challenge Administration and Methodologies, Enterprise Course of Administration, Content material Administration techniques, Enterprise Useful resource Planning, and so forth.

{kind=link}