
Learn to construct a whole deep studying pipeline in PyTorch
Introduction
It’s no secret that the worth of petrol has skyrocketed in the previous couple of months. Persons are filling up with gasoline the minimal crucial each due to a price issue and for causes associated to the atmosphere. However have you ever ever seen that if you lookup on the Web how a lot your automobile ought to spend on fuel to get from level A to level B, the numbers nearly by no means match actuality?
On this article, I wish to develop a easy mannequin that may predict the effectivity (or consumption) of a automobile measured as miles it travels with a single gallon (MPG).
The purpose is to deal with considerably all of the steps within the pipeline, equivalent to information processing, characteristic engineering, coaching and analysis.
All of this shall be achieved in Python utilizing PyTorch. Particularly, I shall be counting on a Colab Pocket book which I all the time discover very handy for these small tasks! 😄
Dataset
The dataset we are going to use on this venture is by now a milestone, Auto MPG dataset from the UCI repository. It consists of 9 options and comprises 398 data. Particularly, the variable names and their varieties are as follows:
1. mpg: steady
2. cylinders: multi-valued discrete
3. displacement: steady
4. horsepower: steady
5. weight: steady
6. acceleration: steady
7. mannequin yr: multi-valued discrete
8. origin: multi-valued discrete
9. automobile identify: string (distinctive for every occasion)
Let’s code!
First, we load the dataset and rename the columns appropriately. The na_values attribute is used to make pandas acknowledge that information of sort ‘?’ needs to be handled as null.
https://medium.com/media/adfcfae2215510d9d745624938078095/href
Now use df.head() to show the dataset.
https://medium.com/media/ad6ef56113e64fd44bbbe2bd9b4444b3/href
With the df.describe() perform we are able to show some fundamental statistics of the dataset to start to know what values we are going to discover.
https://medium.com/media/bcadc98cf60d8a768d14ef9210c6d446/href
In any other case, we are able to use df.data() to see if there are any null values and to search out out the kind of our variables.

We first see that the Horsepower characteristic comprises null values, so we are able to start to delete the data equivalent to these values from the dataset and reset the dataframe index as follows.
https://medium.com/media/f0c32ff9154b9325a603d5830abfe9a0/href
Now if we go to print len(df) → 392, as a result of now we have eradicated rows.
The following factor to do is to separate the dataset right into a practice set and a check set. We use a really helpful sklearn perform to do that. Let’s then save the df_train.describe().transpose() desk since we are going to want some statists to do preprocessing of some options.
https://medium.com/media/d8c022707ff8d619b6eafe2f719fc808/href
train_stats :
https://medium.com/media/6c05138455a37324bafcc712f6c272d9/href
Numerical Options
We at the moment are going to course of some options. We regularly deal with numeric variables in a different way from categorical variables. So first now we begin by defining solely the numerical variables that we’re going to normalize.
To normalize a characteristic all we have to do is subtract the imply of the characteristic and divide it by the usual deviation, for which we are going to want the statistics extracted earlier.
https://medium.com/media/b9f30e48ef460292b577e875c6585e38/href
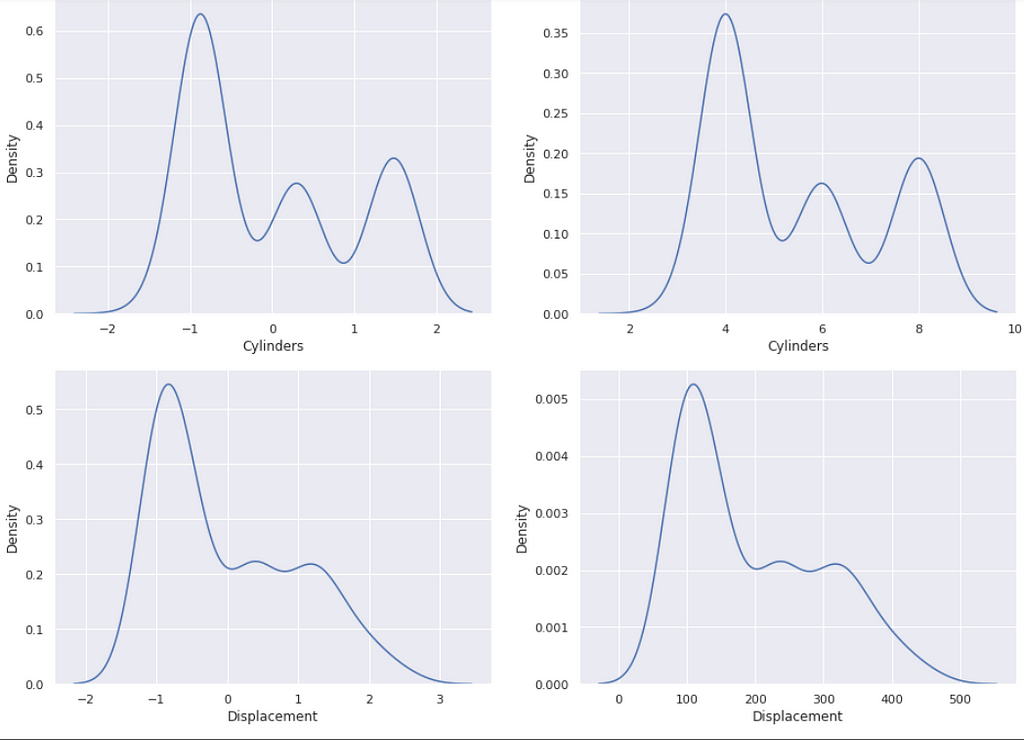
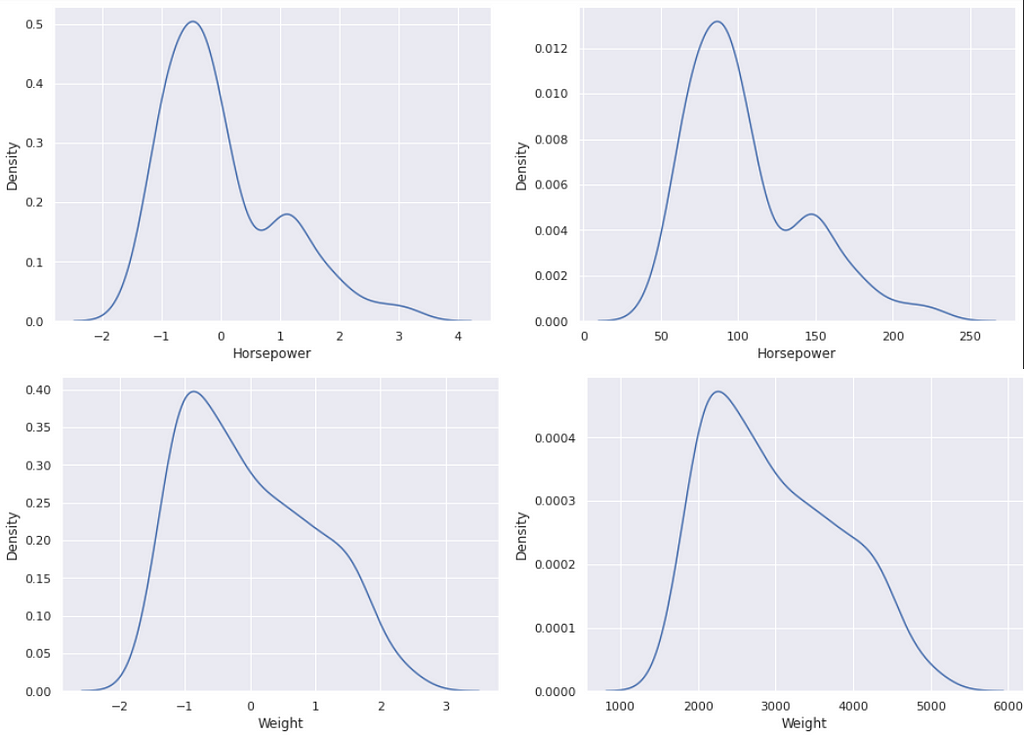
If we now go to plot the normalized options towards these within the unique dataset you’ll discover how the values have modified because of standardization. They’ll then have imply of zero and a regular deviation of one.
https://medium.com/media/38a1628e64f30c51ed28dd6ec505f30a/href
Now relating to the Model_Year characteristic, we’re not keen on realizing during which yr that specific automobile mannequin was made. However possibly we’re extra keen on intervals or bins. For instance, the automobile is sort 1 if the mannequin was made between 73' and 76'. These ranges are a bit arbitrary, you may strive extra of them to see which of them work greatest.
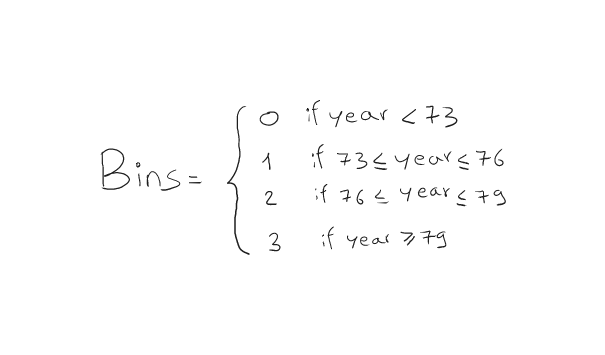
https://medium.com/media/f2585fe757e35c523c97676388312ca5/href
Categorical Options
So far as categorical options are involved, now we have mainly two primary approaches. The primary is to make use of one-hot vectors to rework classes (strings) into binary vectors containing just one 1. For instance, a zero class shall be encoded as [1,0,0,0], class 1 as [0,1,0,0], and so on.
In any other case, we are able to use an embedding layer that maps every class right into a ‘random’ vector that may be educated, in order that we get a vector illustration of the classes that manages to keep up a whole lot of info.
When the variety of classes is massive, utilizing embeds of restricted measurement can have nice benefits.
On this case we use the one-hot encoding.
https://medium.com/media/bb83cdf641363bbe6011b4127b51d03b/href
And let’s additionally extract the labels now we have to predict.
https://medium.com/media/94fc829b334e75956a1c8227761b8fd1/href
PyTorch Dataset & DataLoader
Now that our information are prepared, we create a dataset to raised handle our batches throughout coaching.
https://medium.com/media/dc86d3f036f7f2de530fb42ff4f5b828/href
Mannequin Creation
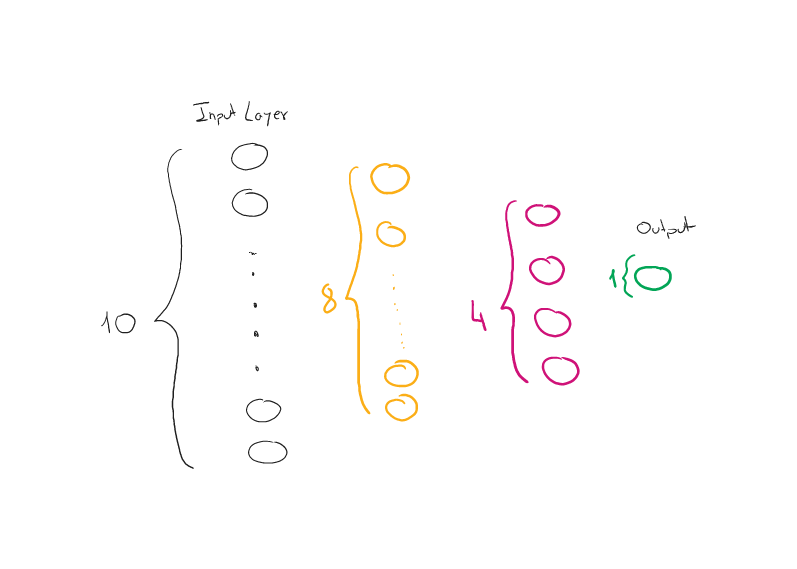
We assemble a small community with two hidden layers, one in every of 8 and one in every of 4 neurons.
https://medium.com/media/f3b8e0ea4e57bb846edbbbff861681be/href
Coaching
Now we outline the loss perform, we are going to use MSE and stochastic gradient descent because the optimizer.
https://medium.com/media/da3d72fa5f46ecbc7fbb008a9e1e1e74/href
To foretell the brand new information level, we are able to feed the check information to the mannequin.
https://medium.com/media/2765d59a31a43345d979cd211ef550e2/href
Last Ideas
On this brief article, we noticed how we might use PyTorch to sort out a real-life drawback. We began by performing some EDA to know what sort of dataset we had on our fingers. Then I confirmed you deal with numeric variables in a different way from categorical variables within the preprocessing section. The strategy of splitting column values into bins is extensively used. Then we noticed how PyTorch permits us to create with only a few steps a customized dataset that we are able to iterate batch by batch. The mannequin we created is a quite simple mannequin with few layers nevertheless utilizing the precise loss perform and a correct optimizer allowed us to do the coaching of our community rapidly. I hope you discovered this text helpful for locating (or reviewing) some PyTorch options.
The Finish
Marcello Politi
Vehicles Effectivity Predictions with PyTorch was initially revealed in In direction of Information Science on Medium, the place individuals are persevering with the dialog by highlighting and responding to this story.
