
Synthetic intelligence (AI) is among the most necessary and long-lived areas of analysis in laptop science. It’s a broad space with crossover into philosophical questions concerning the nature of thoughts and consciousness. On the sensible facet, current day AI is essentially the sphere of machine studying (ML). Machine studying offers with software program techniques able to altering in response to coaching knowledge. A outstanding type of structure is called the neural community, a type of so-called deep studying. This text introduces you to neural networks and the way they work.
Neural networks and the human mind
Neural networks are impressed by the human mind construction, the essential thought being {that a} group of objects referred to as neurons are mixed right into a community. Every neuron receives a number of inputs and a single output primarily based on inner computation. Neural networks are due to this fact a specialised form of directed graph.
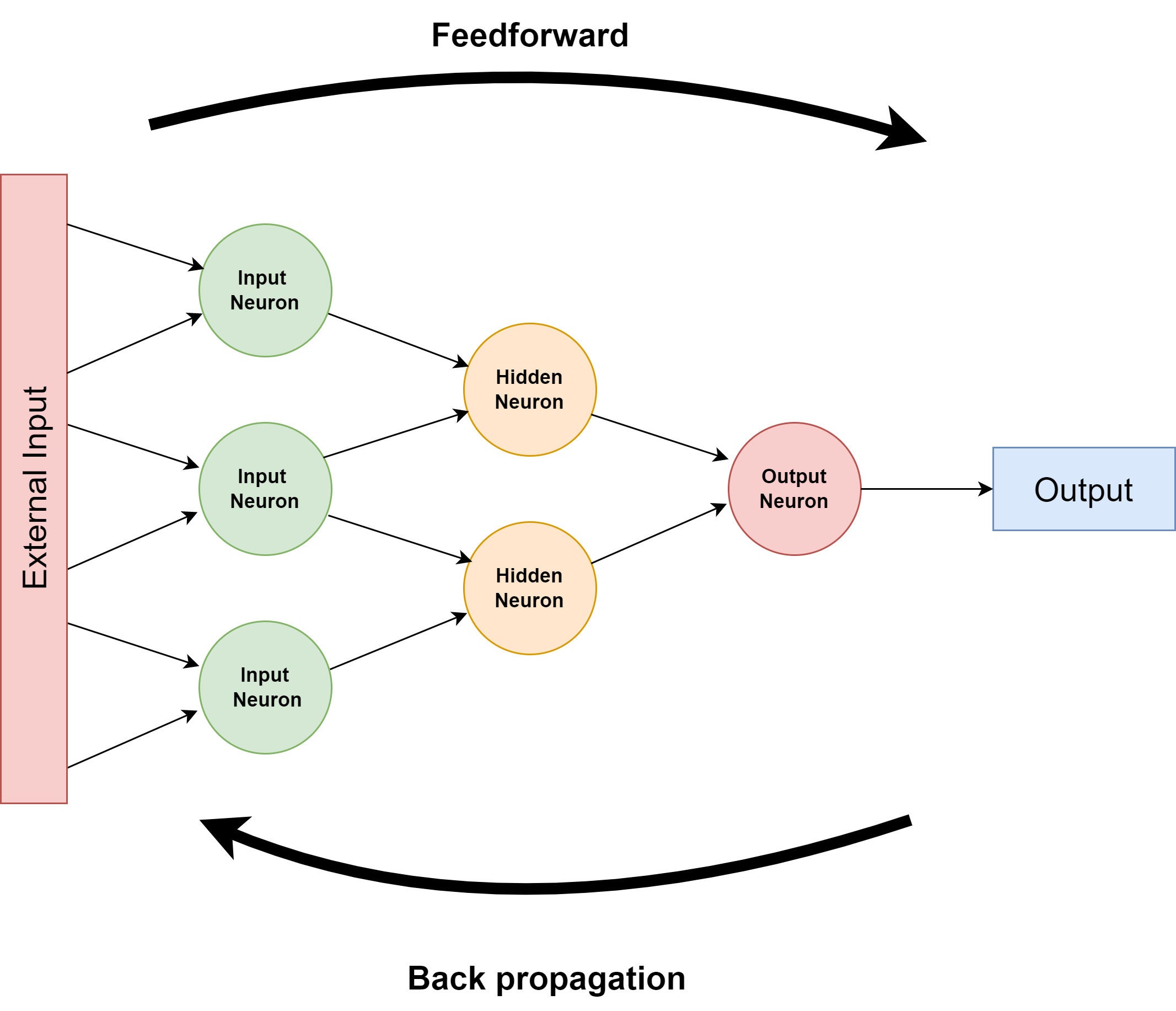
Many neural networks distinguish between three layers of nodes: enter, hidden, and output. The enter layer has neurons that settle for the uncooked enter; the hidden layers modify that enter; and the output layer produces the ultimate consequence. The method of shifting knowledge ahead by the community is named feedforward.
The community “learns” to carry out higher by consuming enter, passing it up by the ranks of neurons, after which evaluating its ultimate output towards identified outcomes, that are then fed backwards by the system to change how the nodes carry out their computations. This reversing course of is called backpropagation and is a essential function of machine studying usually.
An unlimited quantity of selection is encompassed throughout the fundamental construction of a neural community. Each side of those techniques is open to refinement inside particular drawback domains. Backpropagation algorithms, likewise, have any variety of implementations. A standard strategy is to make use of partial derivatives calculus (also referred to as gradient backpropagation) to find out the impact of particular steps within the total community efficiency. Neurons can have completely different numbers of inputs (1 – *) and alternative ways they’re related to type a community. Two inputs per neuron is frequent.
Determine 1 exhibits the general thought, with a community of two-input nodes.
 IDG
IDGDetermine 1. Excessive-level neural community construction
Let’s look nearer on the anatomy of a neuron in such a community, proven in Determine 2.
 IDG
IDGDetermine 2. A two-input neuron
Determine 2 appears on the particulars of a two-input neuron. Neurons all the time have a single output, however could have any variety of inputs, two being the most typical. As enter arrives, it’s multiplied by a weight property that’s particular to that enter. All of the weighted inputs are then added along with a single worth referred to as the bias. The results of these computations is then put by a operate referred to as the activation operate, which supplies the ultimate output of the neuron for the given enter.
The enter weights are the principle dynamic dials on a neuron. These are the values that change to present the neuron differing conduct, the flexibility to study or adapt to enhance its output. Bias is usually a relentless, unchanging property or typically a variable that can also be modified by studying.
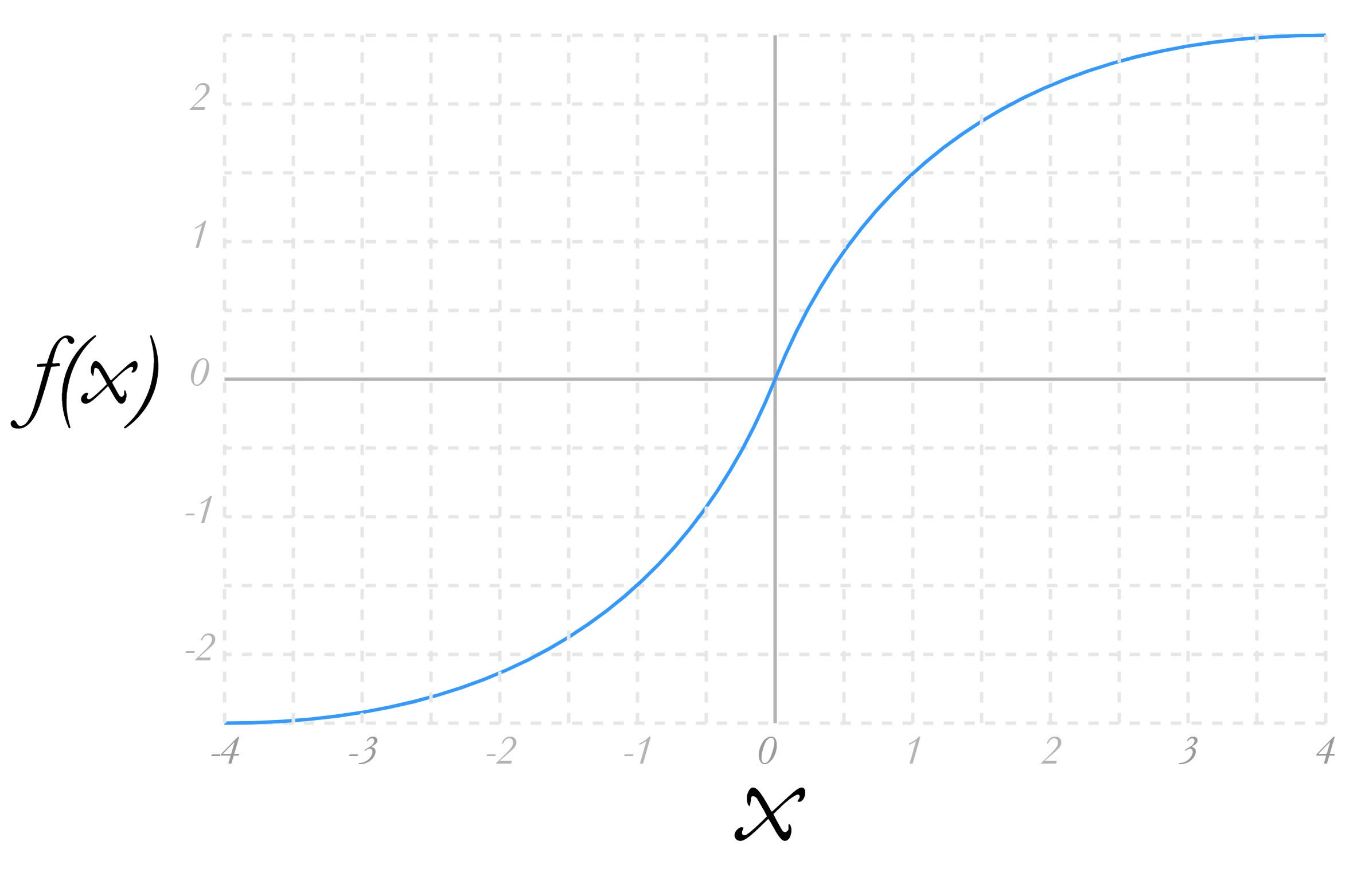
The activation operate is used to convey the output inside an anticipated vary. That is normally a form of proportional compression operate. The sigmoid operate is frequent.
What an activation operate like sigmoid does is convey the output worth inside -1 and 1, with massive and small values approaching however by no means reaching 0 and 1, respectively. This serves to present the output the type of a likelihood, with 1 being the more than likely out and 0 being the least. So this type of activation operate says the neuron offers n diploma of likelihood to the end result sure or no.
You’ll be able to see the output of a sigmoid operate within the graph in Determine 3. For a given x, the farther from 0, the extra dampened the output y will likely be.
 IDG
IDGDetermine 3. Output of a sigmoid operate
So the feedforward stage of neural community processing is to take the exterior knowledge into the enter neurons, which apply their weights, bias, and activation operate, producing the output that’s handed to the hidden layer neurons that carry out the identical course of, lastly arriving on the output neurons which then do the identical for the ultimate output.
Machine studying with backpropagation
What makes the neural community highly effective is its capability to study primarily based on enter. This occurs through the use of a coaching knowledge set with identified outcomes, evaluating the predictions towards it, then utilizing that comparability to regulate the weights and biases within the neurons.
Loss operate
To do that, the community wants a operate that compares its predictions towards the identified good solutions. This operate is called the error, or loss operate. A standard loss operate is the imply squared error operate.
The imply squared error operate assumes it’s consuming two equal-length units of numbers. The primary set is the identified true solutions (right output), represented by Y within the equation above. The second set (represented by y’) are the guesses of the community (proposed output).
The imply squared error operate says: for each merchandise i, subtract the guess from the proper reply, sq. it, and take the imply throughout the information units. This provides us a option to see how properly the community is doing, and to examine the impact of creating adjustments to the neuron’s weights and biases.
Gradient descent
Taking this efficiency metric and pushing it again by the community is the backpropagation section of the educational cycle, and it’s the most complicated a part of the method. A standard strategy is gradient descent, whereby every weight within the community is remoted through partial derivation. For instance, in keeping with a given weight, the equation is expanded through the chain rule and fine-tunings are made to every weight to maneuver total community loss decrease. Every neuron and its weights are thought-about as a portion of the equation, stepping from the final neuron(s) backwards (therefore the identify of the algorithm).
You’ll be able to consider gradient descent this manner: the error operate is the graph of the community’s output, which we are attempting to regulate so its total form (slope) lands in addition to potential in keeping with the information factors. In doing gradient backpropagation, you stand at every neuron’s operate (a degree within the total slope) and modify it barely to maneuver the entire graph a bit nearer to the best resolution.
The thought right here is that you just contemplate all the neural community and its loss operate as a multivariate (multidimensional) equation relying on the weights and biases. You start on the output neurons and decide their partial derivatives as a operate of their values. You then use the calculation to guage the identical for the following neurons again. Persevering with the method on, you identify the position every weight and bias performs within the ultimate error loss, and you may alter every barely to enhance the outcomes.
See Machine Studying for Newcomers: An Introduction to Neural Networks for a very good in-depth walkthrough with the mathematics concerned in gradient descent.
Backpropagation is just not restricted to operate derivatives. Any algorithm that successfully takes the loss operate and applies gradual, optimistic adjustments again by the community is legitimate.
Conclusion
This text has been a fast dive into the general construction and performance of a man-made neural community, one of the vital necessary types of machine studying. Search for future articles masking neural networks in Java and a better have a look at the backpropagation algorithm.
Copyright © 2023 IDG Communications, Inc.

{kind=link}