
An entire information — from knowledge preprocessing to utilization

On-line libraries like HuggingFace present us with state-of-the-art pre-trained A.I. fashions that can be utilized for a lot of completely different purposes in Knowledge Science. On this publish, we’ll present you learn how to use a pre-trained mannequin for a regression drawback. The pre-trained mannequin that we’re going to use is DistilBERT which is a lighter and sooner model of the well-known BERT with 95% of its efficiency.
Suppose that we’ve got the textual content from on-line adverts and its response price normalized by the advert set. Our objective is to create a Machine Studying mannequin that may predict the efficiency of an advert.
Let’s begin coding by importing the required libraries and import our knowledge:
import numpy as np
import pandas as pdimport transformers
from datasets import Dataset,load_dataset, load_from_disk
from transformers import AutoTokenizer, AutoModelForSequenceClassificationX=pd.read_csv('ad_data.csv')
X.head(3)

The textual content represents the advert textual content and the label is the normalized response price.
In an effort to use our knowledge for coaching, we have to convert the Pandas Dataframe into ‘Dataset‘ format. Additionally, we need to break up the info into prepare and take a look at so we are able to consider the mannequin. These will be performed simply by working the next:
dataset = Dataset.from_pandas(X,preserve_index=False)
dataset = dataset.train_test_split(test_size=0.3) dataset

As you may see, the dataset object incorporates each prepare and take a look at units. You may nonetheless entry the info as proven under:
dataset['train']['text'][:5]

We’ll use a pre-trained mannequin so we have to import its tokenizer and tokenize our knowledge.
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
Let’s tokenize a sentence and see what we obtained:
tokenizer('🚨 JUNE DROP LIVE 🚨')['input_ids']

We will decode these ids and see the precise token:
[tokenizer.decode(i) for i in tokenizer('🚨 JUNE DROP LIVE 🚨')['input_ids']]
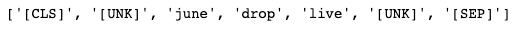
The [CLS] and [SEP] are particular tokens that may all the time be at the start and on the finish of a sentence. As you may see, as a substitute of the emoji ‘🚨’ is the [UNK] token which implies that the token is unknown. It’s because the pre-trained mannequin distilbert doesn’t have emojis in its bag of phrases. Nevertheless, we are able to add extra tokens to the tokenizer to allow them to be educated after we will fine-tune the mannequin to our knowledge. Let’s add some emojis to our tokenizer.
for i in ['🚨', '🙂', '😍', '✌️' , '🤩 ']:
tokenizer.add_tokens(i)
Now, if you happen to tokenize the sentence you will note that the emoji stays as emoji and never the [UNK] token.
[tokenizer.decode(i) for i in tokenizer('🚨 JUNE DROP LIVE 🚨')['input_ids']]
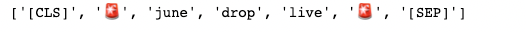
The subsequent step is to tokenize the info.
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)tokenized_datasets = dataset.map(tokenize_function, batched=True)
It’s time to import the pre-trained mannequin.
mannequin = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=1)
In keeping with the documentation, for regression issues, we’ve got to move num_labels=1.
Now, we have to resize the token embeddings as a result of we added extra tokens to our tokenizer.
mannequin.resize_token_embeddings(len(tokenizer))
In a regression drawback, you are attempting to foretell a steady worth. So, you want metrics that measure the gap between the anticipated worth and the true worth. The most typical metrics are MSE (Imply Squared Error) and RMSE (Root Imply Squared Error). For this utility, we’ll use RMSE and we have to create a operate to make use of it when coaching the info.
from datasets import load_metric
def compute_metrics(eval_pred):
predictions, labels = eval_pred
rmse = mean_squared_error(labels, predictions, squared=False)
return {"rmse": rmse}
from transformers import TrainingArguments, Coachtraining_args = TrainingArguments(output_dir="test_trainer",
logging_strategy="epoch",
evaluation_strategy="epoch",
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
save_total_limit = 2,
save_strategy = 'no',
load_best_model_at_end=False
)
coach = Coach(
mannequin=mannequin,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
compute_metrics=compute_metrics
)
coach.prepare()
To save lots of and cargo the mannequin, run the next:
# save the mannequin/tokenizermannequin.save_pretrained("mannequin")
tokenizer.save_pretrained("tokenizer")# load the mannequin/tokenizerfrom transformers import AutoModelForTokenClassification
mannequin = AutoModelForSequenceClassification.from_pretrained("mannequin")
tokenizer = AutoTokenizer.from_pretrained("tokenizer")
As soon as we’ve got loaded the tokenizer and the mannequin we are able to use Transformer’s TextClassificationPipeline to get straightforward predictions from textual content enter.
from transformers import TextClassificationPipelinepipe = TextClassificationPipeline(mannequin=mannequin, tokenizer=tokenizer)
pipe("🚨 Get 50% now!")
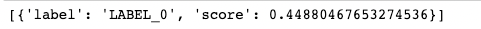
Our remaining output would be the rating as a result of this can be a regression mannequin.
On this publish, we confirmed you learn how to use pre-trained fashions for regression issues. We used the Huggingface’s transformers library to load the pre-trained mannequin DistilBERT and fine-tune it to our knowledge. I feel that the transformer fashions are very highly effective and if used proper can result in approach higher outcomes than the extra traditional approaches of phrase embeddings like word2vec and TF-IDF.

{kind=link}