Let’s design a Twitter like social media service, just like providers like Fb, Instagram, and so forth.
What’s Twitter?
Twitter is a social media service the place customers can learn or publish brief messages (as much as 280 characters) referred to as tweets. It’s accessible on the internet and cell platforms similar to Android and iOS.
Necessities
Our system ought to meet the next necessities:
Purposeful necessities
- Ought to have the ability to publish new tweets (might be textual content, picture, video, and so forth.).
- Ought to have the ability to observe different customers.
- Ought to have a newsfeed characteristic consisting of tweets from the folks the consumer is following.
- Ought to have the ability to search tweets.
Non-Purposeful necessities
- Excessive availability with minimal latency.
- The system ought to be scalable and environment friendly.
Prolonged necessities
- Metrics and analytics.
- Retweet performance.
- Favourite tweets.
Estimation and Constraints
Let’s begin with the estimation and constraints.
Word: Make certain to verify any scale or traffic-related assumptions together with your interviewer.
Visitors
This might be a read-heavy system, allow us to assume we’ve 1 billion whole customers with 200 million every day energetic customers (DAU), and on common every consumer tweets 5 instances a day. This offers us 1 billion tweets per day.
Tweets may include media similar to pictures, or movies. We are able to assume that 10 % of tweets are media recordsdata shared by the customers, which supplies us extra 100 million recordsdata we would want to retailer.
What can be Requests Per Second (RPS) for our system?
1 billion requests per day translate into 12K requests per second.
### Storage
If we assume every message on common is 100 bytes, we would require about 100 GB of database storage daily.
We additionally know that round 10 % of our every day messages (100 million) are media recordsdata per our necessities. If we assume every file is 50 KB on common, we would require 5 TB of storage daily.
And for 10 years, we would require about 19 PB of storage.
### Bandwidth
As our system is dealing with 5.1 TB of ingress daily, we’ll a require minimal bandwidth of round 60 MB per second.
### Excessive-level estimate
Right here is our high-level estimate:
| Kind | Estimate |
|---|---|
| Every day energetic customers (DAU) | 100 million |
| Requests per second (RPS) | 12K/s |
| Storage (per day) | ~5.1 TB |
| Storage (10 years) | ~19 PB |
| Bandwidth | ~60 MB/s |
Information mannequin design
That is the final knowledge mannequin which displays our necessities.
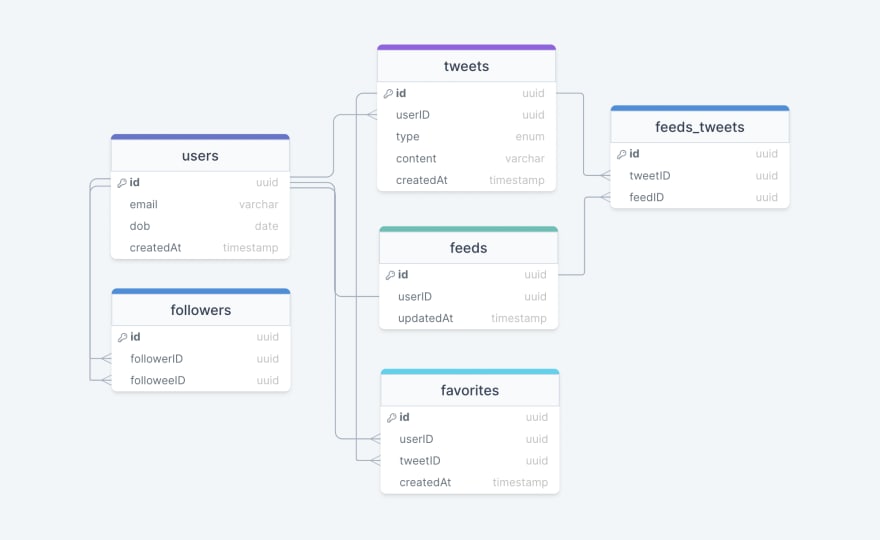
We now have the next tables:
customers
This desk will include a consumer’s info similar to identify, e-mail, dob, and different particulars.
tweets
Because the identify suggests, this desk will retailer tweets and their properties similar to kind (textual content, picture, video, and so forth.), content material, and so forth. We may even retailer the corresponding userID.
favorites
This desk maps tweets with customers for the favourite tweets performance in our software.
followers
This desk maps the followers and followees as customers can observe one another (N:M relationship).
feeds
This desk shops feed properties with the corresponding userID.
feeds_tweets
This desk maps tweets and feed (N:M relationship).
What sort of database ought to we use?
Whereas our knowledge mannequin appears fairly relational, we do not essentially must retailer every part in a single database, as this may restrict our scalability and rapidly grow to be a bottleneck.
We’ll cut up the info between completely different providers every having possession over a specific desk. Then we are able to use a relational database similar to PostgreSQL or a distributed NoSQL database similar to Apache Cassandra for our use case.
API design
Allow us to do a fundamental API design for our providers:
Put up a tweet
This API will enable the consumer to publish a tweet on the platform.
postTweet(userID: UUID, content material: string, mediaURL?: string): boolean
Parameters
Person ID (UUID): ID of the consumer.
Content material (string): Contents of the tweet.
Media URL (string): URL of the hooked up media (non-obligatory).
Returns
Consequence (boolean): Represents whether or not the operation was profitable or not.
Observe or unfollow a consumer
This API will enable the consumer to observe or unfollow one other consumer.
observe(followerID: UUID, followeeID: UUID): boolean
unfollow(followerID: UUID, followeeID: UUID): boolean
Parameters
Follower ID (UUID): ID of the present consumer.
Followee ID (UUID): ID of the consumer we wish to observe or unfollow.
Media URL (string): URL of the hooked up media (non-obligatory).
Returns
Consequence (boolean): Represents whether or not the operation was profitable or not.
Get newsfeed
This API will return all of the tweets to be proven inside a given newsfeed.
getNewsfeed(userID: UUID): Tweet[]
Parameters
Person ID (UUID): ID of the consumer.
Returns
Tweets (Tweet[]): All of the tweets to be proven inside a given newsfeed.
Excessive-level design
Now allow us to do a high-level design of our system.
Structure
We might be utilizing microservices structure since it’ll make it simpler to horizontally scale and decouple our providers. Every service could have possession of its personal knowledge mannequin. Let’s attempt to divide our system into some core providers.
Person Service
This service handles user-related considerations similar to authentication and consumer info.
Newsfeed Service
This service will deal with the era and publishing of consumer newsfeeds. Will probably be mentioned intimately individually.
Tweet Service
The tweet service will deal with tweet-related use circumstances similar to posting a tweet, favorites, and so forth.
Search Service
The service is accountable for dealing with search-related performance. Will probably be mentioned intimately individually.
Media service
This service will deal with the media (pictures, movies, recordsdata, and so forth.) uploads. Will probably be mentioned intimately individually.
Notification Service
This service will merely ship push notifications to the customers.
Analytics Service
This service might be used for metrics and analytics use circumstances.
What about inter-service communication and repair discovery?
Since our structure is microservices-based, providers might be speaking with one another as effectively. Typically, REST or HTTP performs effectively however we are able to additional enhance the efficiency utilizing gRPC which is extra light-weight and environment friendly.
Service discovery is one other factor we must consider. We are able to additionally use a service mesh that allows managed, observable, and safe communication between particular person providers.
Word: Study extra about REST, GraphQL, gRPC and the way they evaluate with one another.
Newsfeed
Relating to the newsfeed, it appears straightforward sufficient to implement, however there are plenty of issues that may make or break this characteristic. So, let’s divide our drawback into two elements:
Era
Let’s assume we wish to generate the feed for consumer A, we’ll carry out the next steps:
- Retrieve the IDs of all of the customers and entities (hashtags, subjects, and so forth.) consumer A follows.
- Fetch the related tweets for every of the retrieved IDs.
- Use a rating algorithm to rank the tweets based mostly on parameters similar to relevance, time, engagement, and so forth.
- Return the ranked tweets knowledge to the consumer in a paginated method.
Feed era is an intensive course of and may take numerous time, particularly for customers following lots of people. To enhance the efficiency, the feed might be pre-generated and saved within the cache, then we are able to have a mechanism to periodically replace the feed and apply our rating algorithm to the brand new tweets.
Publishing
Publishing is the step the place the feed knowledge is pushed based on every particular consumer. This generally is a fairly heavy operation, as a consumer might have hundreds of thousands of buddies or followers. To take care of this, we’ve three completely different approaches:
- Pull Mannequin (or Fan-out on load)
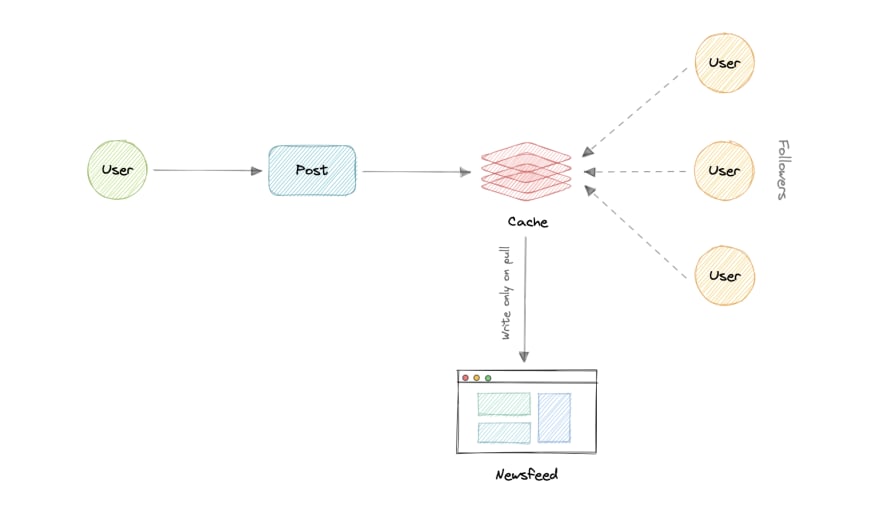
When a consumer creates a tweet, and a follower reloads their newsfeed, the feed is created and saved in reminiscence. The newest feed is simply loaded when the consumer requests it. This method reduces the variety of write operations on our database.
The draw back of this method is that the customers won’t be able to view current feeds until they “pull” the info from the server, which can enhance the variety of learn operations on the server.
- Push Mannequin (or Fan-out on write)
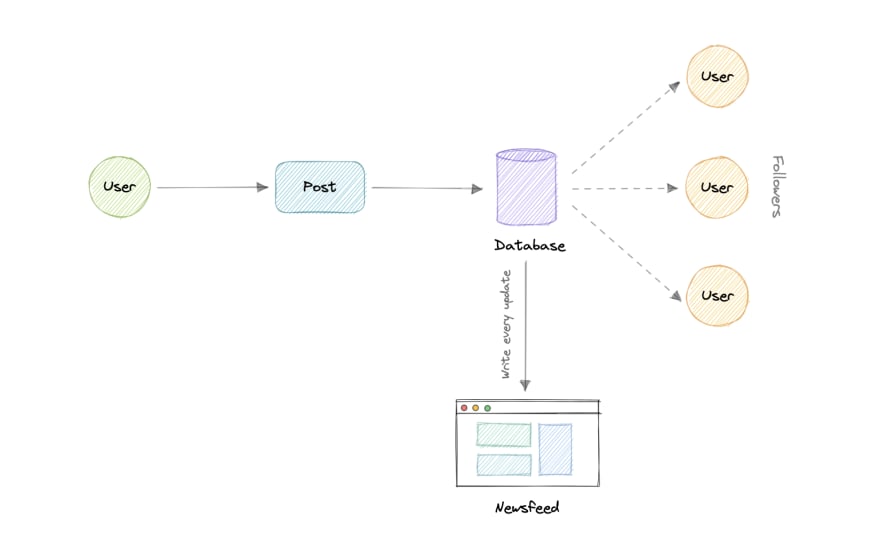
On this mannequin, as soon as a consumer creates a tweet, it’s “pushed” to all of the follower’s feeds instantly. This prevents the system from having to undergo a consumer’s total followers listing to verify for updates.
Nevertheless, the draw back of this method is that it could enhance the variety of write operations on the database.
A 3rd method is a hybrid mannequin between the pull and push mannequin. It combines the useful options of the above two fashions and tries to offer a balanced method between the 2.
The hybrid mannequin permits solely customers with a lesser variety of followers to make use of the push mannequin and for customers with a better variety of followers celebrities, the pull mannequin might be used.
Rating Algorithm
As we mentioned, we’ll want a rating algorithm to rank every tweet based on its relevance to every particular consumer.
For instance, Fb used to make the most of an EdgeRank algorithm, right here, the rank of every feed merchandise is described by:
The place,
Affinity: is the “closeness” of the consumer to the creator of the sting. If a consumer steadily likes, feedback, or messages the sting creator, then the worth of affinity might be larger, leading to a better rank for the publish.
Weight: is the worth assigned based on every edge. A remark can have a better weightage than likes, and thus a publish with extra feedback is extra more likely to get a better rank.
Decay: is the measure of the creation of the sting. The older the sting, the lesser would be the worth of decay and finally the rank.
These days, algorithms are way more complicated and rating is completed utilizing machine studying fashions which might take 1000’s of things into consideration.
Retweets
Retweets are one among our prolonged necessities. To implement this characteristic we are able to merely create a brand new tweet with the consumer id of the consumer retweeting the unique tweet after which modify the kind enum and content material property of the brand new tweet to hyperlink it with the unique tweet.
For instance, the kind enum property might be of kind tweet, just like textual content, video, and so forth and content material might be the id of the unique tweet. Right here the primary row signifies the unique tweet whereas the second row is how we are able to signify a retweet.
| id | userID | kind | content material | createdAt |
|---|---|---|---|---|
| ad34-291a-45f6-b36c | 7a2c-62c4-4dc8-b1bb | textual content | Hey, that is my first tweet… | 1658905644054 |
| f064-49ad-9aa2-84a6 | 6aa2-2bc9-4331-879f | tweet | ad34-291a-45f6-b36c | 1658906165427 |
This can be a very fundamental implementation, to enhance this we are able to create a separate desk itself to retailer retweets.
Search
Typically conventional DBMS usually are not performant sufficient, we’d like one thing which permits us to retailer, search, and analyze enormous volumes of information rapidly and in close to real-time and provides outcomes inside milliseconds. Elasticsearch will help us with this use case.
Elasticsearch is a distributed, free and open search and analytics engine for every type of information, together with textual, numerical, geospatial, structured, and unstructured. It’s constructed on high of Apache Lucene.
How will we establish trending subjects?
Trending performance might be based mostly on high of the search performance. We are able to cache probably the most steadily searched queries, hashtags, and subjects within the final N seconds and replace them each M seconds utilizing some kind of batch job mechanism. Our rating algorithm can be utilized to the trending subjects to offer them extra weight and personalize them for the consumer.
Notifications
Push notifications are an integral a part of any social media platform. We are able to use a message queue or a message dealer similar to Apache Kafka with the notification service to dispatch requests to Firebase Cloud Messaging (FCM) or Apple Push Notification Service (APNS) which can deal with the supply of the push notifications to consumer units.
For extra particulars, check with the Whatsapp system design the place we talk about push notifications.
Detailed design
It is time to talk about our design selections intimately.
Information Partitioning
To scale out our databases we might want to partition our knowledge. Horizontal partitioning (aka Sharding) generally is a good first step. We are able to use partitions schemes similar to:
- Hash-Based mostly Partitioning
- Listing-Based mostly Partitioning
- Vary Based mostly Partitioning
- Composite Partitioning
The above approaches can nonetheless trigger uneven knowledge and cargo distribution, we are able to remedy this utilizing Constant hashing.
For extra particulars, check with Sharding and Constant Hashing.
Mutual buddies
For mutual buddies, we are able to construct a social graph for each consumer. Every node within the graph will signify a consumer and a directional edge will signify followers and followees. After that, we are able to traverse the followers of a consumer to search out and recommend a mutual good friend. This might require a graph database similar to Neo4j and ArangoDB.
This can be a fairly easy algorithm, to enhance our suggestion accuracy, we might want to incorporate a suggestion mannequin which makes use of machine studying as a part of our algorithm.
Metrics and Analytics
Recording analytics and metrics is one among our prolonged necessities. As we might be utilizing Apache Kafka to publish all types of occasions, we are able to course of these occasions and run analytics on the info utilizing Apache Spark which is an open-source unified analytics engine for large-scale knowledge processing.
Caching
In a social media software, we’ve to watch out about utilizing cache as our customers count on the most recent knowledge. So, to forestall utilization spikes from our sources we are able to cache the highest 20% of the tweets.
To additional enhance effectivity we are able to add pagination to our system APIs. This resolution might be useful for customers with restricted community bandwidth as they will not need to retrieve previous messages until requested.
Which cache eviction coverage to make use of?
We are able to use options like Redis or Memcached and cache 20% of the every day visitors however what sort of cache eviction coverage would greatest match our wants?
Least Not too long ago Used (LRU) generally is a good coverage for our system. On this coverage, we discard the least not too long ago used key first.
The right way to deal with cache miss?
Each time there’s a cache miss, our servers can hit the database instantly and replace the cache with the brand new entries.
For extra particulars, check with Caching.
Media entry and storage
As we all know, most of our space for storing might be used for storing media recordsdata similar to pictures, movies, or different recordsdata. Our media service might be dealing with each entry and storage of the consumer media recordsdata.
However the place can we retailer recordsdata at scale? Effectively, object storage is what we’re searching for. Object shops break knowledge recordsdata up into items referred to as objects. It then shops these objects in a single repository, which might be unfold out throughout a number of networked methods. We are able to additionally use distributed file storage similar to HDFS or GlusterFS.
Content material Supply Community (CDN)
Content material Supply Community (CDN) will increase content material availability and redundancy whereas lowering bandwidth prices. Typically, static recordsdata similar to pictures, and movies are served from CDN. We are able to use providers like Amazon CloudFront or Cloudflare CDN for this use case.
Determine and resolve bottlenecks

Allow us to establish and resolve bottlenecks similar to single factors of failure in our design:
- “What if one among our providers crashes?”
- “How will we distribute our visitors between our elements?”
- “How can we cut back the load on our database?”
- “The right way to enhance the supply of our cache?”
- “How can we make our notification system extra sturdy?”
- “How can we cut back media storage prices”?
To make our system extra resilient we are able to do the next:
- Working a number of cases of every of our providers.
- Introducing load balancers between shoppers, servers, databases, and cache servers.
- Utilizing a number of learn replicas for our databases.
- A number of cases and replicas for our distributed cache.
- Precisely as soon as supply and message ordering is difficult in a distributed system, we are able to use a devoted message dealer similar to Apache Kafka or NATS to make our notification system extra sturdy.
- We are able to add media processing and compression capabilities to the media service to compress giant recordsdata which can save plenty of space for storing and cut back value.
This text is a part of my open supply System Design Course accessible on Github.
Discover ways to design methods at scale and put together for system design interviews
Hey, welcome to the course. I hope this course gives an awesome studying expertise.
This course can also be accessible on my web site. Please depart a
-
Getting Began
-
Chapter I
-
Chapter II
-
Chapter III
-
Chapter IV

{kind=link}