
Search is a rising necessity for all purposes. As knowledge accumulates at a excessive quantity and velocity, it is crucial that the remainder of our knowledge pipeline is able to extracting the appropriate info and insights from this knowledge. Search is likely one of the main instruments for that.
Regardless of the multimedia revolution, lots of knowledge we gather is within the type of textual content. This may be social media feeds, net crawler extracts, shopper evaluations, medical stories, streaming geo-location updates, and plenty of extra. Gone are the times of searches primarily based on a case-sensitive actual string match. We’d like a system that may handle textual content at scale to course of this knowledge. We have to run superfast fuzzy queries on the textual content.
RediSearch supplies a beautiful answer for that. We will course of streaming in addition to static knowledge. Apart from fuzzy textual content search, RediSearch allows advanced search on numeric and geolocation knowledge. And, after all, we will take the fundamental tag searches without any consideration.
This weblog covers the core ideas of RediSearch, together with code snippets to exhibit the idea.
Core ideas
Syntax alone shouldn’t be sufficient. To make the most effective use of any software, it helps if we perceive the way it works below the hood. For that, allow us to begin off with some core ideas.
Inverted Index
RediSearch relies on the idea of an inverted index. It maintains an inverted index for every thing that seems within the knowledge. Meaning for each listed entity we add to the RedisDB, RediSearch extracts all the person values and provides entries into the index construction. These entries include inverted mapping that maps the searchable worth to the unique key. Thus, we will map any entity within the knowledge to the important thing for that object within the Redis DB.
Environment friendly search has two steps. Step one is to determine the worth that the person is making an attempt to seek for. Having recognized the worth, the second step is to get the important thing that refers back to the object containing the worth we recognized. An inverted index helps us with the second step. As soon as we determine the worth that the person desires to seek for, we will leap to the important thing with none delay. Allow us to now examine step one.
Trie – Secret behind the pace
Trie (digital search tree/prefix tree) is a knowledge construction that may allow quick retrieval on massive knowledge units. The time period “trie” comes from the phrase ‘Data Re*trie*val’. In easy phrases, trie organizes textual content knowledge right into a tree constructed out of the prefixes. What does that imply?
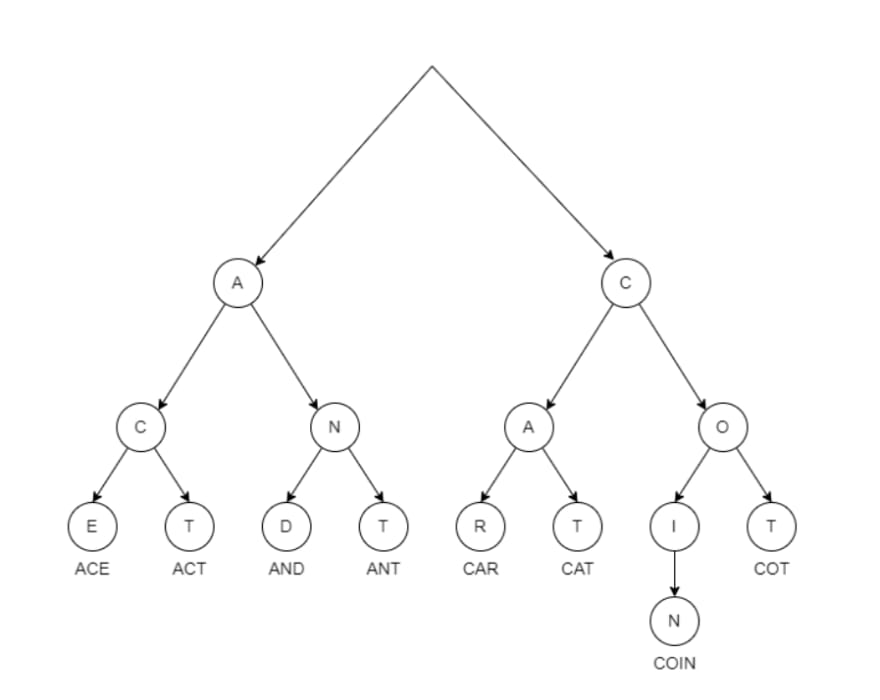
Because the identify suggests, a prefix tree builds a tree of prefixes. Now, what does that imply? Any string could be thought of a sequence of prefixes. If we index textual content corpus utilizing such a prefix tree, we will find any node utilizing direct traversal into the tree – not by counting or scanning. Due to this, the time complexity of finding any phrase is impartial of the amount of knowledge. On the identical time, the complexity of absorbing new knowledge is low as effectively.
That allows scalable and superfast searches on massive volumes of knowledge.
RediSearch takes this a step additional. The tree needn’t be carried out with single characters immediately extracted from the uncooked textual content. We could be smarter once we construct the prefix tree. It may be constructed utilizing a lemma extracted from the textual content. After we create such a wise index, we will implement superfast fuzzy search on an enormous quantity of knowledge. That’s the secret behind the effectivity of RediSearch textual content queries. For extra info on implementing fuzzy search, consult with this Wikipedia article.
Tag Index
The tag search is supposed to be sooner than a full-featured textual content search. We use tag index once we know the sector accommodates the particular textual content we question immediately. We apply it to fields the place we don’t require a fuzzy search. Tag search can afford an easier index.
Numeric Index
RediSearch defines a particular index construction for numeric knowledge. Numeric queries are sometimes primarily based on a computational vary. An index primarily based on distinct values can not assist such queries. We’d like one thing higher. As an alternative of treating every quantity as an impartial entity, we must always index them in a manner that acknowledges numbers in relation to their values.
RediSearch achieves this by making a Numeric index primarily based on binary vary bushes. Such index teams collectively numbers which are nearer to one another. Thus, within the numeric index tree, such teams are saved on “vary nodes” as a substitute of getting one quantity per node. That is simpler mentioned than performed. How can we determine the scale of a node? How can we outline the brink of closeness for numbers that may be packed into one node? RediSearch has an adaptive algorithm that implements such grouping and classification of numbers into teams.
Geo Index
Through the years, cellphones/IoT gadgets and their geo-location have turn into a major factor of knowledge flowing into our database. With an elevated load of geospatial knowledge, the efficiency of geospatial queries is a crucial part of database efficiency. Naturally, RediSearch does its finest to handle this area.
RediSearch has geo-indexing primarily based on the closeness between factors. This closeness is recognized primarily based on the gap calculated by the geospatial queries. The factors are then collected into vary bushes that allow quick search and grouping.
Scoring
A search question could return a number of outcomes. We don’t need to overwhelm the shopper with tons of knowledge. It is sensible to order the information primarily based on some rating in order that the shopper can select to take what’s extra related than the remainder of the end result set. Scoring is completely different from sorting. Sorting is solely primarily based on absolutely the worth of the content material of the sector. The rating is a measure of the relevance of every worth of the search end result.
Such scores could be calculated utilizing predefined capabilities in RediSearch or customized capabilities that increase the rating of a part of the end result.
Setup
Allow us to now work on establishing the database and instruments required for utilizing Redis.
Putting in Redis
Don’t set up!
Gone are the times once we developed and examined our code with databases put in on our laptops. Welcome to the cloud. All you want is a couple of clicks, and the free database occasion is prepared for you. Why muddle your laptop computer?
- Leap to the Redis cloud. If you happen to don’t have an account, create one in lower than a minute.
- Signup with Google/GitHub in the event you don’t need to bear in mind too many passwords.
- When you log in, click on on Create subscription. Then settle for all of the defaults to create a brand new free subscription primarily based on AWS, hosted within the us-east-1 area.
- Upon getting the subscription, click on “New database” to create a database occasion.
- Once more, settle for all of the defaults and click on on “Activate database”.
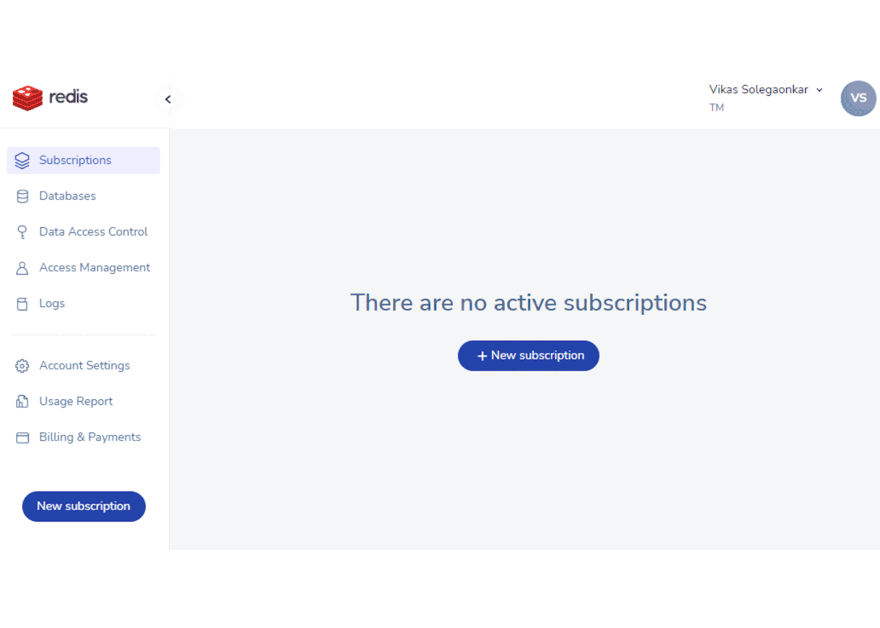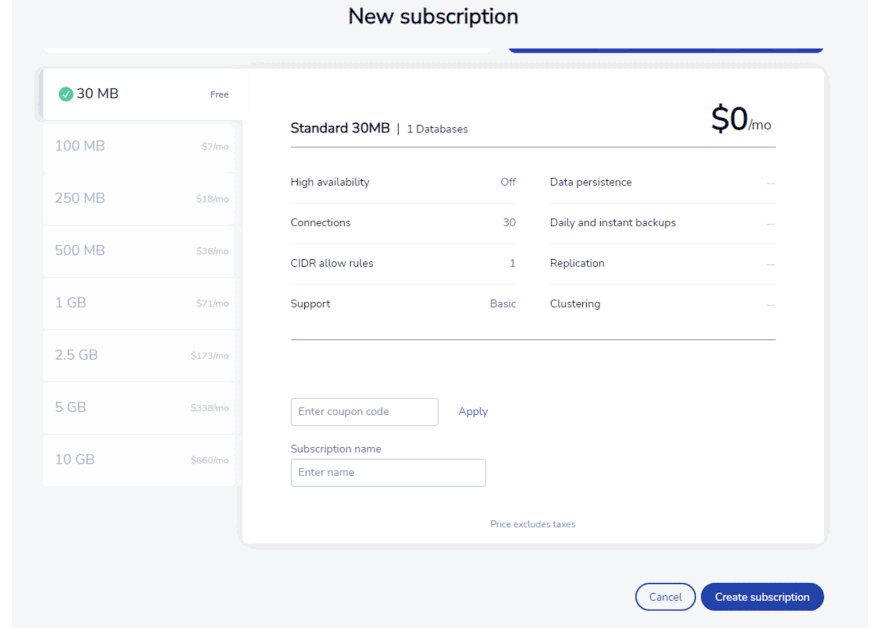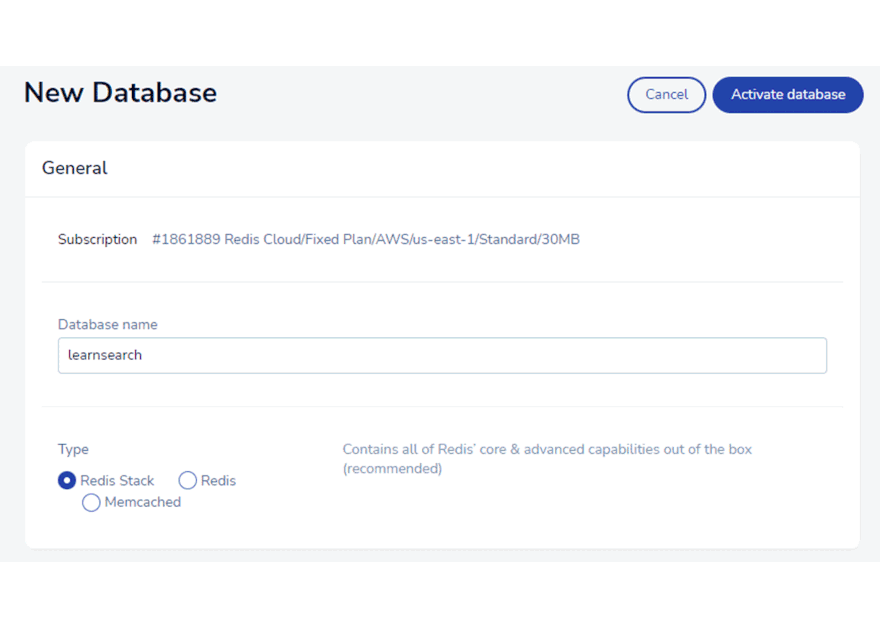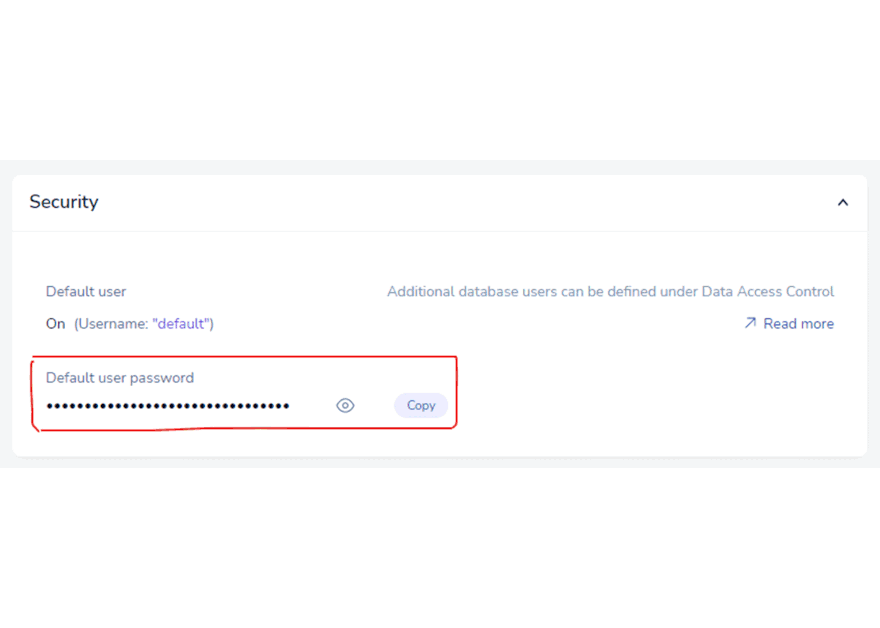
- Give it a couple of minutes to arrange. And there, the database is ready so that you can begin studying. Simply be aware the database URL.
- Additionally, be aware the database password. Copy to a notepad. Then sign off of the net console.
Redis Insights
It is a must-have software for working with Redis. You may obtain it from this hyperlink. The set up and setup are easy. Click on ADD REDIS DATABASE to configure a brand new connection and supply the database particulars you picked within the above steps.
Present me code
Did you will have an overdose of concept? Allow us to now style some code that may assist us apply some ideas. This instance focuses on the textual content search. Redis supplies us with a simple command line interface, together with helpful SDK modules in commonest languages.
Beneath is a JavaScript code that makes use of Node Redis module to speak with the Redis Server. Together with the JavaScript code, we will see the corresponding CLI instructions. We’d like a text-rich dataset to save lots of in our database and exhibit the search performance. For this, we are going to use a dump of poems obtained from Kaggle. The JSON chunk could be discovered on this hyperlink.
Code
With the database prepared, allow us to examine the code intimately. You could find the entire supply code on this GitHub repository. Clone that repository domestically. You will want NodeJS to run this code. As soon as the code is prepared, open the file config/default.json. Replace the file to incorporate the Redis URL and password we received whereas creating the database.
Now, a fast view of the JavaScript code. Try the app.js
Imports
Like another JavaScript code, we begin with the imports
const specific = require("specific");
const redis = require("redis");
const axios = require("axios");
const md5 = require("md5");
const config = require("config");
Redis Shopper
Instantiate the shopper to attach with the Redis database
const shopper = redis.createClient(config.redis);
shopper.on("error", (err) => console.log("Redis Shopper Error", err));
await shopper.join().then((e) => console.log("Linked"))
.catch((e) => console.log("Not related"));
Load Information
Subsequent, we pull the poem knowledge from the web and cargo it into the database
var promiseList = record.map((poem, i) =>
Promise.all(Object.keys(poem).map((key) => shopper.hSet(`poem:${md5(i)}`, key, poem[key])))
);
await Promise.all(promiseList);
Create Index
With the information in our database, we proceed to create the index. This completes the database setup. Be aware right here, that we’ve got some TEXT indexes and a few TAG indexes. The poetry age and sort have a TAG index, as a result of we don’t anticipate advanced queries round them.
await shopper.ft.create(
"idx:poems",
{
content material: redis.SchemaFieldTypes.TEXT,
writer: redis.SchemaFieldTypes.TEXT,
title: { sort: redis.SchemaFieldTypes.TEXT, sortable: true },
age: redis.SchemaFieldTypes.TAG,
sort: redis.SchemaFieldTypes.TAG,
},
{
ON: "HASH",
PREFIX: "poem:",
}
);
The identical could be performed in Redis CLI utilizing
FT.CREATE idx:poems ON HASH PREFIX 1 poem: SCHEMA content material TEXT writer TEXT title TEXT SORTABLE age TAG sort TAG
Writer API
With the database setup, we begin with the specific server. After instantiating the specific app, we create the primary API that may seek for poems primarily based on the writer. Be aware that it’s a common expression. So, it’ll fetch any writer identify that matches the expression. Furthermore, the search is case-insensitive.
app.get("/writer/:writer", operate (req, res) {
shopper.ft.search("idx:poems", `@writer: /${req.params.writer}/`)
.then((end result) => res.ship(end result.paperwork));
});
Attempt invoking the API with http://127.0.0.1:3000/writer/william
It would fetch all of the poems written by authors with William of their identify.
The identical could be achieved by the CLI
FT.SEARCH idx:poems "@writer:/william/"
Fuzzy Search API
The instance reveals one other search functionality, which is the fuzzy search. Be aware the % signal within the search expression. This signifies the fuzzy search. Now, the search will even match comparable phrases.
app.get("/fuzzy/:textual content", operate (req, res) {
shopper.ft.search("idx:poems", `%${req.params.textual content}%`)
.then((end result) => res.ship(end result.paperwork));
});
Attempt to invoke the API with http://127.0.0.1:3000/fuzzy/converse
It would fetch poems containing a phrase just like converse. The identical could be achieved by the CLI
FT.SEARCH idx:poems "%converse%"
Extra Data
This was only a glimpse of the potential of RediSearch. To grasp additional particulars, take a look at
- Enterprise Redis
- Redis for Builders
This submit is in collaboration with Redis

{kind=link}