
Utilizing Recurrent Neural Networks in a Sentiment Evaluation process

That is the second article in a sequence devoted to Deep Studying, a gaggle of Machine Studying strategies that has its roots courting again to the 1940’s. Deep Studying gained consideration within the final a long time for its groundbreaking purposes in areas like picture classification, speech recognition, and machine translation.
The primary article targeted on the MultiLayer Perceptron. Keep tuned should you’d wish to see completely different Deep Studying algorithms defined with real-life examples and a few Python code.
The event of the MultiLayer Perceptron was an vital landmark for Synthetic Neural Networks. For the primary time we might stack collectively many perceptrons and arrange them in layers, to create fashions that greatest characterize complicated issues.
MultiLayer Perceptron works in an atemporal, discrete means. It takes one enter vector, performs a feedforward computational step, back-propagates the errors, and stops as soon as the loss perform can’t be minimized any additional, producing the output.
However plenty of real-world issues contain a time dimension. What about when the issue at hand comes within the type of a sequence?
Within the earlier article you used the MultiLayer Perceptron for the duty of Sentiment Evaluation. You took the critiques in your mother and father’ cozy mattress and breakfast within the countryside, educated a MultiLayer Perceptron and predicted the general sentiment of the evaluate.

The MultiLayer perceptron used the tokenized phrase vector of every evaluate as enter, nevertheless it checked out every evaluate a single, an atomic unit.
A extra exact means of analyzing these critiques would take into consideration the place of every phrase the evaluate, as a result of the construction of a sentence performs a job in giving it which means.
A a lot highly effective mannequin than the MultiLayer Perceptron would analyze critiques in response to how every sentence is constructed. As an example, with sentences like This time across the service was nice and The service was nice this time round, it will be intelligent sufficient to find out these sentences have similar sentiment[1]. Though the phrases had been shuffled round.
To go one step additional in that sentiment evaluation process, you want a special mannequin.
You want a mannequin that seems at every evaluate as an ordered sequence of phrases, not an atomic unit. Every sequence of phrases may also have and an arbitrary size, since every sentence could be made up of a special variety of phrases.
You might want to construct a Recurrent Neural Community.
Recurrent Neural Networks are utilized in a number of domains. As an example, in Pure Language Processing (NLP), they’ve been used to generate handwritten textual content, carry out machine translation and speech recognition. However their purposes will not be restricted to processing language. In Laptop Imaginative and prescient, Recurrent Neural Networks have been utilized in duties like picture captioning and picture question-answer.
What distinguishes a Recurrent Neural Community from the MultiLayer Perceptron is {that a} Recurrent Neural Community is constructed to deal with inputs that characterize a sequence, just like the sequence of phrases in a evaluate out of your mother and father’ mattress and breakfast. But it surely additionally handles an output sequence, like once you’re translating a sentence from one language to a different.
Recurrent Neural Networks act like a sequence. The computation carried out at every time step, depends upon the earlier computation.
The magic of Deep Studying coaching is within the hidden layers.
In the beginning of coaching the structure of the community is outlined, on this case, a Recurrent Neural Community. However we solely know which inputs match with which outputs. The algorithm will discover ways to use the hidden layers to make the perfect approximation of every enter to output knowledge level[1].
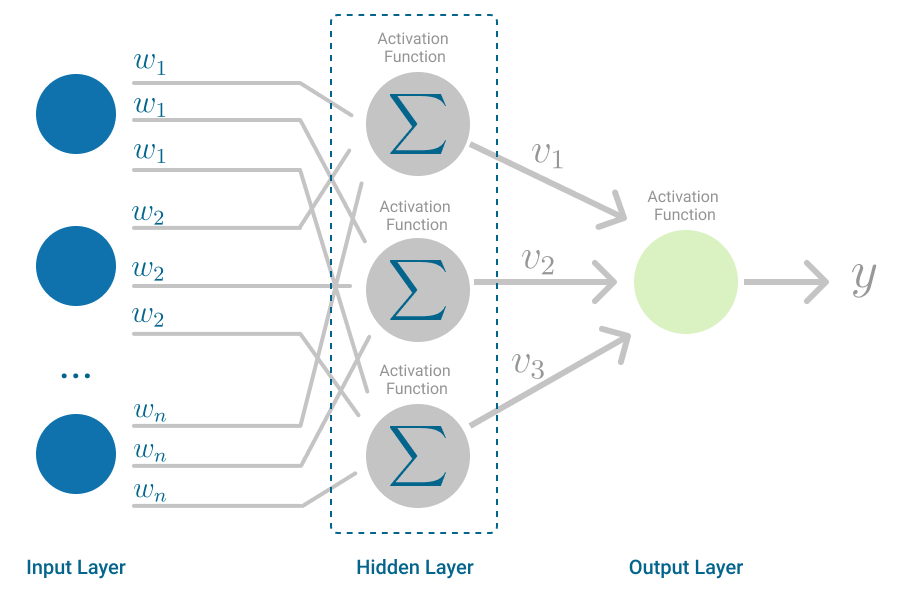
Top-of-the-line methods to visualise a Recurrent Neural Community is as a cyclic computational graph[1]. On this illustration the Recurrent Neural Community has three main states:
- Enter state, which captures the enter knowledge for the mannequin.
- Output state, which captures the outcomes of the mannequin.
- Recurrent state, which is in reality a sequence of hidden states, and captures all of the computations between the enter and output states.
Equally to different Supervised Machine Studying Fashions, Recurrent Neural Networks use a loss perform to check the output of the mannequin to the bottom reality. That loss is later back-propagated and mannequin weights are replace, like within the MultiLayer Perceptron.
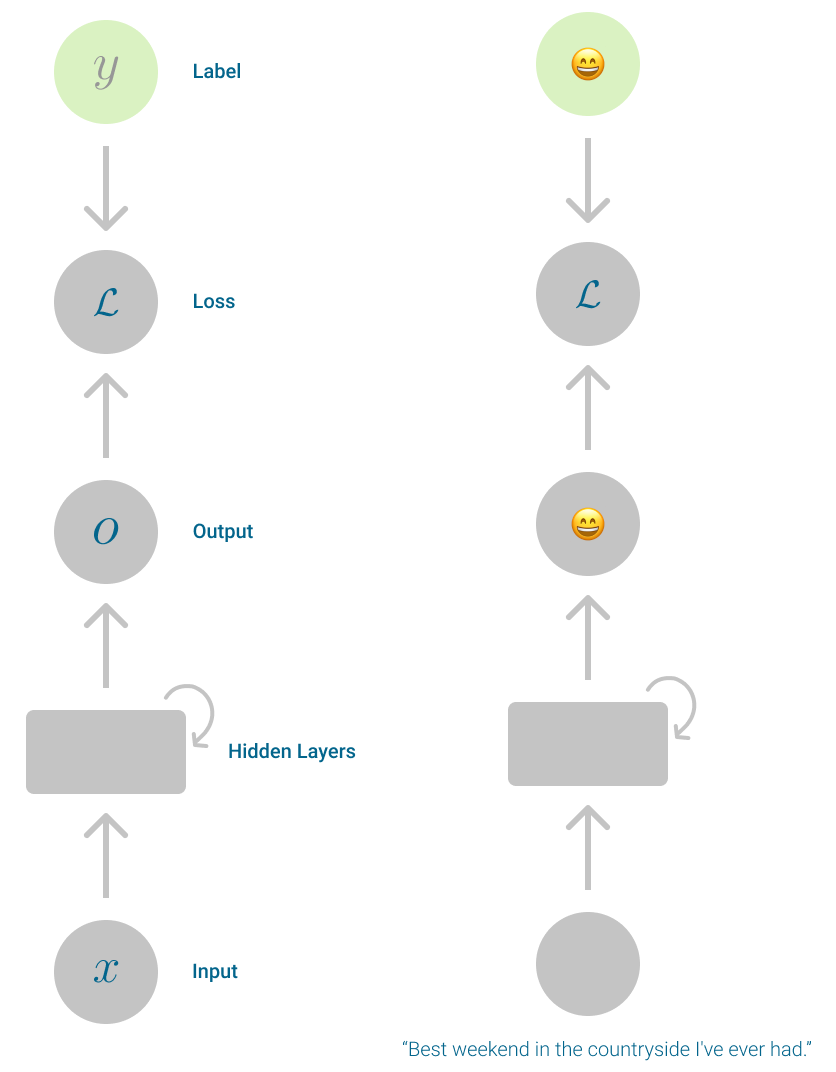
It is a compressed view, extra like a abstract of the mechanics of Recurrent Neural Networks. In observe, it’s simpler to visualise the recurrence once you unfold this graph. Particularly when working with textual content sequences.
On this unfolded view of a Recurrent Neural Community every computation corresponds to 1 step, additionally known as inside state. And every step depends upon the computation from the earlier step.

As every inside state depends on the earlier one, you might have data that’s propagated onto every layer of neurons within the community for the reason that starting of the sequence. Like an previous reminiscence that’s handed on to future generations.
If MultiLayer Perceptron meant stacking a number of neurons in layers, Recurrent Neural Networks means chaining MultiLayer Perceptrons, to create a sequence of dependent computations.
Within the case of a Recurrent Neural Community, recollections are details about the computations utilized to the sequence thus far.
A single weight vector is shared throughout all time steps within the community.
A key attribute of Recurrent Neural Networks is parameter sharing. There’s just one set of parameters that’s used, and optimized, throughout all elements of the community. If these parameters weren’t shared, the mannequin must study the parameters for every a part of the enter sequence and would have a a lot more durable time generalizing examples it had not seen but[1].
Sharing parameters provides Recurrent Neural Networks the flexibility to deal with inputs with completely different lengths, and nonetheless carry out predictions in a an appropriate timeframe.
Shared parameters are notably vital to generalize sequences that share inputs, though in several positions. Within the case of your dad or mum’s mattress and breakfast critiques, with out shared parameters, the community would have a a lot arduous time, and would do repeated work studying the identical language guidelines a number of occasions, to determine sentences like This time across the service was nice and The service was nice this time round, have the identical output sentiment.
It is a main benefit of RNNs as a result of, with out parameter sharing, you’d must study a special mannequin for every time step in your sequence, and also you’d want a big coaching set to accommodate the completely different mannequin coaching steps.
In observe, parameter sharing means the output perform is a results of the output from earlier time steps, every step up to date with the identical rule. The latter being one other vital side of Recurrent Neural Networks, the replace rule is similar, which suggests, at every time step, the community applies the identical activation perform.
The community can have as many hidden states as you’d wish to, however there’s one vital fixed. In every hidden state you’re at all times computing the identical activation perform. The output of every layer is calculated utilizing the identical perform[3].

The activation perform could be so simple as a linear perform or the sigmoid perform. However the hyperbolic tangent can also be generally utilized in Deep Studying, as a result of it tends to have fewer occurrences of vanishing gradients when in comparison with the sigmoid.
Coaching a deep neural community with hyperbolic tangent is so simple as coaching a linear mannequin, so long as computations are small [1].
The hyperbolic tangent, represented as tanh(x), is a stable alternative for activation perform. It behaves just like the id perform close to zero, such that tanh(0) = 0.
So, so long as the computations for this activation perform are small, coaching a deep neural community with hyperbolic tangent is so simple as coaching a linear mannequin[1].
Proper now you is likely to be pondering Didn’t you say that each layer makes use of the identical activation perform?
Sure however, in classification duties, the output layer is particular.
Particularly for Neural Networks that deal with classification issues, there’s additionally one other activation perform, utilized solely to output layer, nearly like a post-processing step. Meet the Softmax perform.
The output of a binary classification drawback is both a 0 or a 1. However generally you’re tackling a multi-class drawback, as an example, if the critiques in your mother and father’ mattress and breakfast had been categorized as Optimistic, Impartial or Detrimental.
On this case, with 3 attainable output courses, it’s extra helpful to know the way probably the statement is to belong to the constructive class. That is why, together with the activation perform you select for the community, the Softmax perform is utilized within the output layer.

Vector z is the results of all of the computations for the reason that first layer, it’s the vector that reaches the output layer.
As an example, in case your neural community solely has one linear layer, vector z could be appear like:
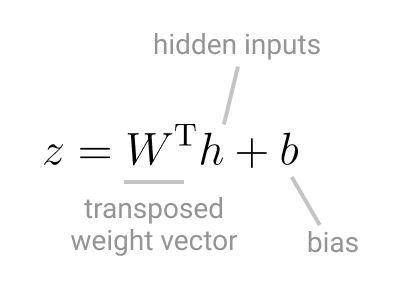
With Softmax, this vector is exponentiated and, since this can be a classification process, normalized throughout all attainable Ok courses, turning the vector right into a likelihood distribution. That’s why Softmax can also be referred to as the Normalized exponential perform.
After making use of Softmax, the sum of all values of vector z at all times provides as much as one. Its values characterize the likelihood that the statement given to community within the enter layer belongs to every class.
For those who don’t apply Softmax to the output layer, the output of your Recurrent Neural Community is a quantity for
every of the attainable courses. The output with the best worth is the successful class for that statement[3].
Thus far you’ve regarded into the broader structure and parts of a Recurrent Neural, i.e., the activation and loss features. Let’s concentrate on the educational.
Because the computations circulate from every hidden in a layer to the following, it strikes ahead, in the direction of the output layer. Reaching the output layer you compute the loss perform, which means you evaluate the output generated to the anticipated true worth for that coaching statement.
If the method stopped right here, the community wouldn’t have the ability to study. It might be a feedfoward community, since data strikes ahead within the community construction. However studying wants some type of loop. Similar to once you study one thing at school or by yourself: data will get to your mind, that is the feedfoward half, then you definitely course of it and as you do that, you sanity-check and, generally re-learn sure issues, that is the half I name the loop.
Neural networks are impressed by the mind, principally impressed by how neurons work. However these neural community architectures, even have this a loop half. The half the place they study how you can map the enter knowledge to one of many attainable outcomes.
Again to Recurrent Neural Networks!
Inputs undergo all of the layers and, when it reaches the output layer it computes the loss perform. Now, realizing how completely different, or distant, from the anticipated end result that chain of computations was, it takes the worth of the loss perform and computes its gradient with respect to the parameters.
Then, with the assistance of one other algorithm, like Stochastic Gradient Descent, that gradient is distributed again in the wrong way. All the way in which again to the enter layer.
This fashion you’re back-propagating the loss perform.
The precise computation of the gradient is what known as back-propagation [1]. However is often confused with the precise studying half, completed by algorithms like Stochastic Gradient Descent.
Reaching the enter layer Stochastic Gradient Descent, or different gradient-based optimizer algorithm, adjusts the community weights and the activation perform is computed once more by way of each hidden layer.
Every weight within the community is up to date by subtracting the worth of the gradient with respect to the loss perform (J), from the present weight vector (theta). That is additionally referred to as the weight change quantity (vt).

The method goes on till the loss perform can’t be minimized anymore, so there’s no level in adjusting weights as soon as once more, and the efficiency of the neural community is improved to the utmost given the present coaching set and structure.
Extra complicated algorithms and Neural Community Architectures could enhance efficiency, nevertheless it additionally provides complexity to all computations, resulting in longer coaching time.
In Machine Studying, you’re at all times coping with trade-offs. With extra complicated fashions among the trade-offs are (a) growing efficiency, however lowering mannequin interpretability or (b) growing efficiency, however growing coaching time.
As a substitute of constructing a Recurrent Neural Community from scratch, you’ve determined to make use of TensorFlow’s sturdy library to assist with classify the sentiment from critiques of your mother and father mattress and breakfast.
Very first thing you want is to set up TensorFlow in your machine through pip, because you’re going to make use of the native Python surroundings.
Following the TensorFlow docs:
# Requires the most recent pip
> pip set up --upgrade pip# Present steady launch for CPU and GPU
> pip set up tensorflow
Then you definitely observed there’s a strong instance of Textual content Classification utilizing RNNs on the TensorFlow sources[6]. That’s a very good foundation for what you need to do, you simply have to adapt it to your individual process.
At a look, establishing a Recurrent Neural Community to categorise the sentiment of all critiques out of your mother and father’ mattress and breakfast includes:
- Organizing Coaching and Testing Information
- Loading Coaching and Testing Datasets
- Dimensionality Drawback: Compressing your Dataset (Vectorization)
- Constructing the Recurrent Neural Community
- Mannequin Becoming and Analysis
- Accuracy and Loss Visualized
Step one is taking the critiques your cousins have helped classify and organizing them into the corresponding directories. There can be prepare and take a look at directories, each with sub-directories that include constructive and detrimental critiques.
After this group, should you run the command tree in your mission listing, you’ll have one thing like this:
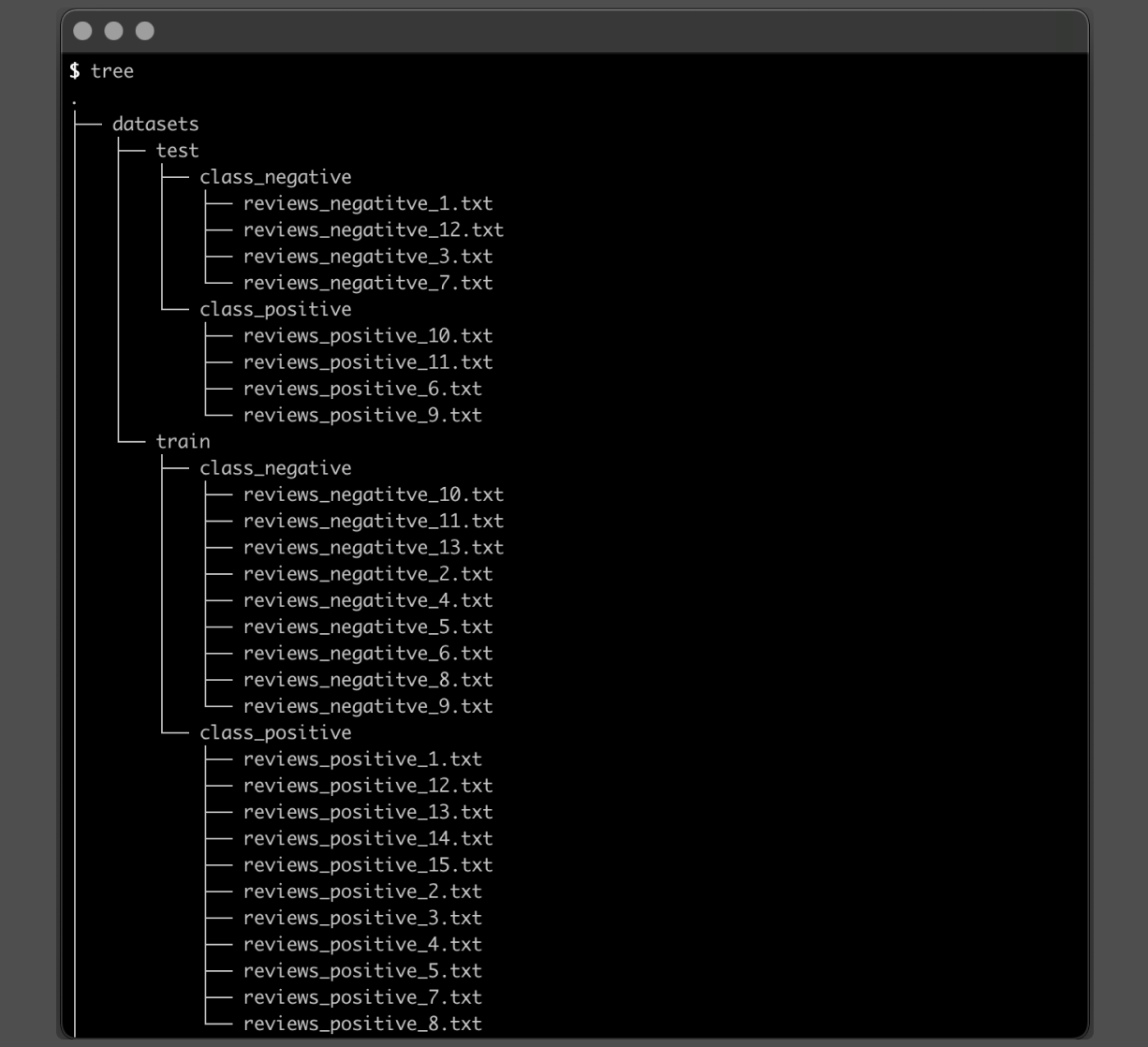
What’s vital on this step is there is just one evaluate per file, so it may be correctly loaded and processed within the following steps.
To load the prepare and take a look at datasets you’ll be able to leverage Keras utility methodology text_dataset_from_directory, which particularly requires the listing dataset construction you set collectively on the earlier step.
Your mother and father’ mattress and breakfast critiques will not be that prolonged. There can be extra enthusiastic clients, who write a brief essay about their expertise however, from an information perspective, the result’s a vector of comparatively low dimensionality.
However what in case your mother and father enterprise was so standard that Journey and Leisure magazines begin writing articles, basically critiques, about them? On this case we’re speaking about a lot bigger dataset, and every evaluate is {a magazine} article of no less than 800 phrases.
On this situation, you’re coping with a dimensionality drawback. You have got very giant and sparce vectors, which makes all matrix calculations computationally difficult.
To deal with this case you need to do one thing much like what you do with Principal Part Evaluation. You need to compress your dataset, whereas preserving all of its expressiveness, all its core traits.
“These are constructed from a really giant corpus of paperwork by a variant of principal parts evaluation. The concept is that the positions of phrases within the embedding area protect semantic which means; e.g. synonyms ought to seem close to one another.” [5]
A typical preprocessing step is to scale back the dimensionality with wor2vec[4]. In TensorFlow the Keras TextVectorization layer does one thing related. It takes a string and both maps it to a 1-dimensional tensor of indices or a 1-dimensional tensor of floats that characterize the information within the string.
On the finish of this step, the coaching dataset is vectorized and the information preparation section is full.
Now you’re able to construct the Recurrent Neural Community.
Your Recurrent Neural Community mannequin is, in observe, a gaggle of Sequential layers.
The primary one is the vocabulary encoder, created on the earlier step. It’s used within the Embedding layer, which converts the values within the encoded vectors into a particular vary.
As an example, the vocabulary in your critiques consists of 151 phrases, obtained by operating:
len(encoder.get_vocabulary())
So the mannequin takes the vocabulary measurement as enter, through input_dim, and returns an output of measurement 64, outlined utilizing output_dim. And since you specified a vocabulary measurement of 151, the most important integer within the mapping can be 150.

The subsequent layer, Bidirectional, signifies you need to create a bidirectional Recurrent Neural Community. This implies the enter of the community is propagates forwards and backwards by way of the NRR layers. The recollections the community creates over time, as it’s processing the enter, will not be solely handed ahead to the next cells, however are additionally handed to earlier cells. Now, every cell within the community has details about the previous and what lies forward within the enter sequence.
The benefit of utilizing a Bidirectional Recurrent Neural Community is that’s not simply the earlier data within the community that contributes to the output prediction. Figuring out what’s developing forward within the sequence can have a major affect on how the mannequin learns.
This benefit is a double-edged sword. As data is now propagated backwards and forwards, these networks are usually a lot slower, as a result of gradients now have a for much longer dependency chain.
Nonetheless, your mother and father’ mattress and breakfast critiques is a small dataset. So that you’ve determined it’s price a strive!
The final two layers within the mannequin are Dense Layers. The second to final is used to course of the mannequin loss, with the hyperbolic tangent as activation. The final one reshapes the output to be of measurement 1, given that you really want the output of the mode to be the constructive or detrimental class index.
On this case, the RNN is created utilizing 30 GRUCells. These Gated Recurrent Items (GRU) use the hyperbolic tangent because the activation perform for recurrent step.
Now that you just’ve constructed and compiled the Recurrent Neural Community, it’s time to match it to the coaching dataset and make some predictions.
Just a few parameters you’ll be able to tune are:
- epochs what number of occasions you’d just like the algorithm to undergo your entire coaching set
- shuffle in case you’d wish to shuffle the coaching knowledge earlier than every epoch iteration. True by default
- validation_steps the variety of batches of samples to attract earlier than the validation step is concluded, and the algorithm begins the brand new epoch

As a remaining step, it’s at all times attention-grabbing to visualise the loss and accuracy of the mannequin. Particularly if it’s operating by way of a number of iterations.

Right here you’re additionally leveraging code from the useful instance from TensorFlow’s documentation web page to plot the loss and accuracy for the coaching and validation datasets.

After making predictions on the take a look at dataset, the accuracy is much from good. It hovers round 0.5 which suggests your mannequin is, technically, not a lot better than a random guess.
The accuracy stays very a lot steady at 50% all through all analysis epochs, and the loss begins steadily growing after the third epoch.
However these outcomes shouldn’t discourage you. Your dataset could be very small and the RNN structure used could be very simplistic, and will undoubtedly be refined. That is only a first run on understanding RNNs.
There are a number of alternative ways to construct a recurrent neural community, relying on the duty at hand.
It will probably have a one-to-many construction, like when the mannequin has to create a caption for a given picture. However should you’re translating English to French or vice-versa, you’ll be constructing a Recurrent neural community with a many-to-many construction.
For the Sentiment Evaluation process or classifying all critiques out of your mother and father’ cozy mattress and breakfast, the community had a many-to-one construction, a number of phrases in a evaluate contributing to a single output, the sentiment class. Both constructive or detrimental.
The community you’ve created was comparatively easy, and had an unimpressive 50% accuracy.
However I hope you bought a greater sense of what’s a Recurrent Neural Community, why it’s such game-changer Deep Studying community structure, and the sorts of real-life issues it may be utilized to.
Thanks for studying!
- Goodfellow, Ian J., Bengio, Yoshua and Courville, Aaron. Deep Studying, MIT Press, 2016
- The Unreasonable Effectiveness of Recurrent Neural Networks
- Heaton, Jeff. Functions of Deep Neural Networks
- Tomas Mikolov Kai Chen Greg S. Corrado Jeffrey Dean. Environment friendly Estimation of Phrase Representations in Vector House. (2013)
- Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani. (2021). An introduction to statistical studying : with purposes in R. (2nd Version) Springer
- Textual content classification with an RNN, TensorFlow Documentation

{kind=link}