This submit was first revealed in NLP Information.
NeurIPS 2023, arguably this 12 months’s greatest AI convention takes place in two weeks from Dec 10–16 in New Orleans. 3586 papers have been accepted to the convention, that are accessible on-line.
On this submit, I’ll talk about a choice of 20 papers associated to pure language processing (NLP) that caught my eye, with a give attention to oral and highlight papers. Listed here are the principle developments I noticed:
- Most NLP work at NeurIPS is expounded to giant language fashions (LLMs). Whereas there are some papers that don’t make use of LLMs or use a unique setting (see Suhr & Artzi under, as an illustration), papers nonetheless offered their contributions within the context of LLMs.
- Artificial setups to research LLM properties have gotten extra widespread. It’s because it’s computationally prohibitive to run many various pre-training experiments. Investigated properties vary from the emergence of in-context studying and studying utilizing international statistics to chain-of-thought reasoning.
- Aligning fashions based mostly on human preferences acquired numerous consideration. Papers notably centered on enhancing RLHF and finding out alignment to particular character traits and beliefs.
- A complete understanding of in-context studying nonetheless stays elusive. Papers studied completely different elements of in-context studying equivalent to whether or not it persists throughout coaching and utilizing a Bayesian perspective.
- Reasoning continues to be difficult with present fashions. Papers centered on enhancing efficiency on numerous sorts of reasoning duties together with pragmatic, graph-based, algorithmic, compositional, and planning-based reasoning.
- Exterior instruments are more and more used to enhance LLMs’ reasoning talents. These vary from exterior verifiers to code execution modules.
Word that among the strategies proposed in these papers equivalent to DPO and QLoRA have already been efficiently utilized in LLM functions.
Rethinking LLMs
That is one among my favourite subjects as these papers encourage us to rethink our basic assumptions relating to LLMs and supply new insights and views on their internal workings.
Lexinvariant Language Fashions (Huang et al.). One of many basic traits of LMs that hasn’t modified for the reason that first neural LM paper is the one-to-one mapping between tokens and embeddings. This paper research whether or not language modeling may also be carried out with fashions which are ‘lexinvariant’, i.e., that would not have mounted token embeddings however assign the lexical permutation of every sequence the identical chance. This looks like a powerful limitation—however it could actually function a helpful inductive bias for recovering substitution cyphers (through an MLP probe) and in-context image manipulation. In observe, tokens are encoded utilizing random Gaussian vectors and sampled in order that the identical token has the identical illustration inside a sequence however completely different representations throughout sequences. Whereas this technique is especially of theoretical curiosity, utilizing it as regularization through the use of random embeddings just for a subset of tokens improves outcomes on some BIG-bench duties.
Studying from Human Suggestions
Given the proliferation of various pre-trained LLMs, researchers and practitioners are more and more trying to enhance the subsequent step within the LLM pipeline: studying from human suggestions, which is vital for maximizing efficiency on downstream duties but in addition for LLM alignment.
Direct Choice Optimization: Your Language Mannequin is Secretly a Reward Mannequin (Rafailov et al.). Reinforcement studying from human suggestions (RLHF) is the popular method to replace LLMs to align with goal preferences however is sort of advanced (it requires first coaching a reward mannequin after which updating the LLM with RL based mostly on the reward mannequin) and might be unstable. This paper proposes Direct Choice Optimization (DPO), which reveals that the identical goal might be optimized through a easy classification-based goal on the choice information—with none RL! An vital part of the target is a dynamic, per-example significance weight. DPO has the potential to make aligning LLMs with human preferences way more seamless—and can thus be vital for security analysis.
Nice-Grained Human Suggestions Offers Higher Rewards for Language Mannequin Coaching (Wu et al.). This paper addresses one other limitation of RLHF, which doesn’t enable the combination of extra fine-grained suggestions relating to which elements of the generated response are faulty. The paper proposes Nice-grained RLHF, which a) makes use of a dense reward mannequin (a reward for each output sentence moderately than for the whole output) and b) incorporates a number of reward fashions for numerous suggestions. They experiment on detoxing and long-form query answering the place they see improved outcomes in comparison with RLHF and supervised fine-tuning. Importantly, as offering human choice judgements for RLHF is a posh annotation activity, offering extra fine-grained suggestions is definitely not extra time-intensive. Count on to see extra approaches experimenting with numerous reward fashions at completely different granularities.
Continuous Studying for Instruction Following from Realtime Suggestions (Suhr & Artzi). This paper tackles continuous studying from human suggestions in a collaborative 3D world setting. They show a easy method utilizing a contextual bandit to replace the mannequin’s coverage utilizing binary rewards. Over 11 rounds of coaching and deployment, instruction execution accuracy improves from 66.7% to 82.1%. Empirically, on this setting, the suggestions information offers an analogous quantity of studying sign because the supervised information. Whereas their setting differs from the usual text-based situation, it offers a sketch for a way instruction-following brokers can regularly be taught from human suggestions. Sooner or later, we are going to possible see approaches that make the most of extra expressive suggestions equivalent to through pure language.
LLM Alignment
With a purpose to be certain that LLMs are most helpful, it’s essential to align them with the particular tips, security insurance policies, character traits and beliefs which are related for a given downstream setting. To do that, we first want to know what tendencies LLMs already encode—after which develop strategies to steer them appropriately.
Evaluating and Inducing Persona in Pre-trained Language Fashions (Jiang et al.). This paper proposes to evaluate the character of LLMs based mostly on the Large 5 character traits recognized from psychology. Constructing on current questionnaires, they create multiple-choice query answering examples the place the LLM should select how precisely statements equivalent to “You like to assist others” describe it. Every assertion is related to a character trait. Crucially, it’s much less vital whether or not a mannequin scores extremely on a particular trait however whether or not it displays a constant character, that’s, whether or not it responds equally to all questions related to the trait. Solely the biggest fashions exhibit constant character traits which are much like these of people. It will likely be attention-grabbing to higher perceive below what situations character traits emerge and the way constant personalities might be encoded in smaller fashions.
In-Context Impersonation Reveals Giant Language Fashions’ Strengths and Biases (Salewski et al.). There was numerous anecdotal proof that prompting LLMs to impersonate area consultants (e.g., “you’re an skilled programmer”, and many others) improved fashions’ capabilities. This paper research such in-context impersonation throughout completely different duties and finds certainly that LLMs impersonating area consultants carry out higher than LLMs impersonating non-domain consultants. Impersonation can also be helpful to detect implicit biases. For example, LLMs impersonating a person describe automobiles higher than ones prompted to be a lady (based mostly on CLIP’s means to match a picture to a class utilizing the generated description of the class). Total, impersonation is a great tool to research LLMs—however could reinforce biases when used for (system) prompts.
Evaluating the Ethical Beliefs Encoded in LLMs (Scherer et al.). This paper research how ethical beliefs are encoded in LLMs with regard to each high-ambiguity (“Ought to I inform a white lie?”) and low-ambiguity eventualities (“Ought to I cease for a pedestrian on the highway?”) eventualities. They consider 28 (!) completely different LLMs and discover that a) in unambiguous eventualities most fashions align with commonsense whereas in ambiguous instances, most fashions specific uncertainty; b) fashions are delicate to the wording of the query; and c) some fashions exhibit clear preferences in ambiguous eventualities—and closed-source fashions have related preferences. Whereas the analysis depends on a heuristic mapping of output sequences to actions, the info is beneficial for additional analysis of LLMs’ ethical beliefs.
LLM Pre-training
Pre-training is essentially the most compute-intensive a part of LLM pipelines and is thus more durable to check at scale. However, improvements equivalent to new scaling legal guidelines enhance our understanding of pre-training and inform future coaching runs.
Scaling Knowledge-Constrained Language Fashions (Muennighoff et al.). As the quantity of textual content on-line is proscribed, this paper investigates scaling legal guidelines in data-constrained regimes, in distinction to the scaling legal guidelines by Hoffmann et al. (2022), which centered on scaling with out repeating information. The authors observe that coaching for as much as 4 epochs on repeated information performs equally to coaching on distinctive information. With extra repetition, nevertheless, the worth of further coaching quickly diminishes. As well as, augmenting the pre-training information with code meaningfully will increase the pre-training information measurement. In sum, every time we don’t have infinite quantities of pre-training information, we must always practice smaller fashions for extra (as much as 4) epochs.
LLM Nice-tuning
Nice-tuning giant fashions with back-propagation is dear so these papers suggest strategies to make fine-tuning extra environment friendly, both utilizing parameter-efficient fine-tuning strategies or with out computing gradients (zeroth-order optimization).
QLoRA: Environment friendly Finetuning of Quantized LLMs (Dettmers et al.). This paper proposes QLoRA, a extra memory-efficient (however slower) model of LoRA that makes use of a number of optimization methods to save lots of reminiscence. They practice a brand new mannequin, Guanaco, that’s fine-tuned solely on a single GPU for 24h and outperforms earlier fashions on the Vicuna benchmark. Total, QLoRA permits utilizing a lot fewer GPU reminiscence for fine-tuning LLMs. Concurrently, different strategies equivalent to 4-bit LoRA quantization have been developed that obtain related outcomes.
Nice-Tuning Language Fashions with Simply Ahead Passes (Malladi et al.). This paper proposes a memory-efficient zeroth-order optimizer (MeZO) as a extra memory-efficient model of a traditional zeroth-order optimizer that makes use of variations of loss values to estimate gradients. In observe, the strategy achieves related efficiency to fine-tuning on a number of duties however requires 100x extra optimization steps (whereas being sooner at every iteration). However, it’s shocking that such zeroth-order optimization works with very giant fashions within the first place, demonstrating the robustness of such fashions, and is an attention-grabbing route for future work.
Emergent Talents and In-context Studying
Sure talents of LLMs equivalent to in-context studying and arithmetic reasoning have been proven to be current solely within the largest fashions. It’s nonetheless unclear how these talents are acquired throughout coaching and what particular properties result in their emergence, motivating many research on this space.
Are Emergent Talents of Giant Language Fashions a Mirage? (Schaeffer et al.). Emergent talents are talents which are current in large-scale fashions however not in smaller fashions and are onerous to foretell. Moderately than being a product of fashions’ scaling habits, this paper argues that emergent talents are primarily an artifact of the selection of metric used to guage them. Particularly, nonlinear and discontinuous metrics can result in sharp and unpredictable adjustments in mannequin efficiency. Certainly, the authors discover that when accuracy is modified to a steady metric for arithmetic duties the place emergent habits was beforehand noticed, efficiency improves easily as an alternative. So whereas emergent talents should still exist, they need to be correctly managed and researchers ought to take into account how the chosen metric interacts with the mannequin.
The Transient Nature of Emergent In-Context Studying in Transformers (Singh et al.). Chan et al. (2022) have beforehand proven that the distributional properties of language information (particularly, ‘burstiness’ and a extremely skewed distribution) play an vital position within the emergence of in-context studying (ICL) in LLMs. Prior work additionally usually assumes that after the ICL means has been acquired, it’s retained by the mannequin as studying progresses. This paper makes use of Omniglot, an artificial picture few-shot dataset to indicate instances the place ICL emerges—solely to be subsequently misplaced whereas the loss continues to lower. Alternatively, L2 regularization appears to assist the mannequin retain its ICL means. It’s nonetheless unclear, nevertheless, how ICL emerges and if transience might be noticed throughout LLM pre-training on real-world pure language information.
Why suppose step-by-step? Reasoning emerges from the locality of expertise (Prystawski et al.). This paper investigates why and the way chain-of-thought reasoning (Wei et al., 2022) is beneficial in LLMs utilizing a artificial setup. Just like Chan et al. (2022), they research distributional properties of the pretraining information. They discover that chain-of-thought reasoning is barely helpful when the coaching information is domestically structured. In different phrases, when examples are about carefully linked subjects as is widespread in pure language. They discover that chain-of-thought reasoning is useful as a result of it incrementally chains native statistical dependencies which are regularly noticed in coaching. It’s nonetheless unclear, nevertheless, when chain-of-thought reasoning emerges throughout coaching and what are the properties of downstream duties the place it’s most helpful.
Giant Language Fashions Are Latent Variable Fashions: Explaining and Discovering Good Demonstrations for In-Context Studying (Wang et al.). This paper frames in-context studying with LLMs as matter modeling the place the generated tokens are conditioned on a latent matter (idea) variable, which captures format and activity data. To make this computationally environment friendly, they use a smaller LM to be taught the latent ideas through immediate tuning on the complete demonstration information. They then choose the examples that obtain the best chance below the prompt-tuned mannequin as demonstrations for in-context studying, which improves over different choice baselines. This can be a additional information level that reveals that examples which are possible based mostly on a latent idea of a activity are helpful demonstrations. This possible isn’t the complete image, nevertheless, and it will likely be attention-grabbing to see how this formulation pertains to different information similarity and variety measures.
Delivery of a Transformer: A Reminiscence Viewpoint (Bietti et al.). This research investigates how LLMs be taught in-context studying in addition to the power to make use of extra basic data in an artificial setup. The setup consists of sequences generated by a bigram LM the place some bigrams require the native context to deduce them whereas others require international statistics. They discover that two-layer transformers (however not one-layer transformers) develop an induction head consisting of a “circuit” of two consideration heads to foretell in-context bigrams. They then freeze among the layers to check the mannequin’s coaching dynamics, discovering that international bigrams are realized first and that the induction head learns acceptable reminiscences in a top-down trend. Total, this paper sheds additional gentle on how in-context studying can emerge in LMs.
Reasoning
Reasoning duties that require the systematic chaining or composition of various items of data are some of the vital issues for present LLMs to unravel. Their difficult nature and the range of domains the place they’re related makes them a fruitful space for analysis.
On the Planning Talents of Giant Language Fashions – A Crucial Investigation (Valmeekam et al.). Planning and sequential resolution making are vital for a variety of functions. This paper research whether or not LLMs can generate easy plans for commonsense planning duties2. Used on their very own, solely 12% of the plans generated by one of the best LLM are immediately executable. Nonetheless, when mixed with an automatic planning algorithm that may determine and take away errors within the LLM-generated plan, LLMs do a lot better than utilizing a random or empty preliminary plan. LLMs plans may also be improved through prompting based mostly on suggestions from an exterior verifier. Alternatively, the advantages of LLMs disappear when motion names are unintelligible and can’t be simply inferred with widespread sense, which signifies an absence of summary reasoning means. Total, whereas preliminary plans of LLMs might be helpful as a place to begin, LLM-based planning at present works finest primarily together with exterior instruments.
Can Language Fashions Clear up Graph Issues in Pure Language? (Wang et al.) The authors create NLGraph, a benchmark of graph-based reasoning issues described in pure language and consider LLMs on it. They discover that LLMs show spectacular preliminary graph reasoning talents—37–58% above random baselines. Nonetheless, in-context studying and superior prompting methods (chain-of-thought prompting and others) are largely ineffective on extra advanced graph issues and LLMs are inclined to spurious correlations. Extra specialised graph prompting methods, nevertheless, enhance outcomes. Count on to see mixtures of ordinary graph-based strategies (equivalent to these utilized to FB15k) and LLMs and analysis on strategies scaling LLMs to bigger graphs.
The Goldilocks of Pragmatic Understanding: Nice-Tuning Technique Issues for Implicature Decision by LLMs (Ruis et al.). This paper research whether or not LLMs exhibit a specific sort of pragmatic inference, implicature3. The authors consider whether or not fashions can perceive implicature by measuring whether or not they assign a better chance to a press release that accommodates the proper inference in comparison with the inaccurate one. They discover that each instruction tuning and chain-of-thought prompting are vital for such pragmatic understanding and that the biggest mannequin, GPT-4 reaches human-level efficiency. We are going to possible see extra work on various kinds of pragmatic understanding as these are essential for seamless and human-like conversations.
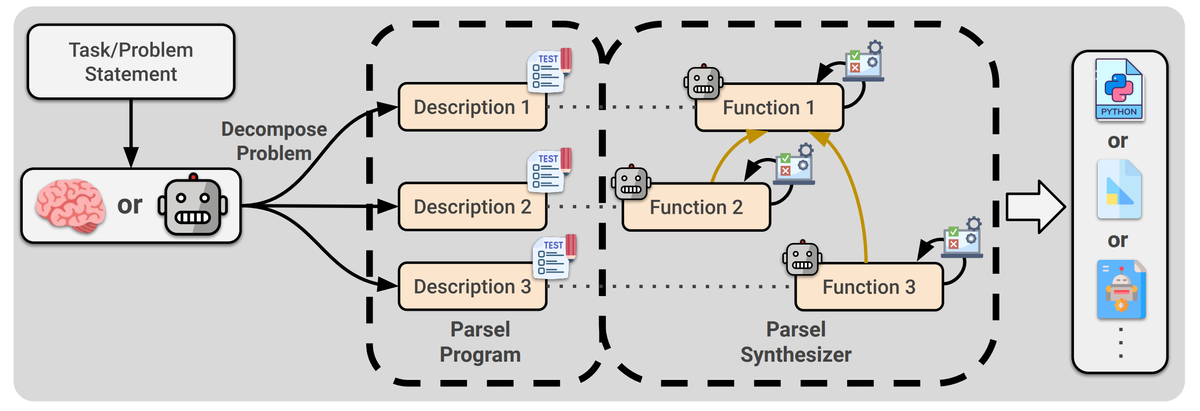
Parsel🐍: Algorithmic Reasoning with Language Fashions by Composing Decompositions (Zelikman et al.). This paper introduces Parsel, a framework to implement advanced applications with code LLMs. An LLM is first used to generate pure language operate descriptions in a easy intermediate language. For every operate description, the mannequin then generates implementation candidates. The operate candidates are then examined in opposition to input-output constraints and composed to kind the ultimate program. Utilizing GPT-4 as LLM, this framework elevated efficiency on HumanEval from 67% to 85%. This can be a nice instance of how LLMs can be utilized as a constructing block along with domain-specific data and instruments for a lot improved efficiency. As well as, count on to see extra work on breaking down advanced resolution issues into subproblems which are extra simply solvable utilizing LLMs.
Religion and Destiny: Limits of Transformers on Compositionality (Dziri et al.). This paper investigates the compositional reasoning talents of LLMs. They formulate compositional reasoning duties as computation graphs with the intention to quantify their complexity. They discover that full computation subgraphs seem considerably extra regularly within the coaching information for appropriately predicted take a look at examples than for incorrectly predicted ones, indicating that fashions be taught to match subgraphs moderately than creating systematic reasoning abilities. Utilizing a scratchpad and grokking (coaching past overfitting) equally don’t enhance efficiency on extra advanced issues. Total, present LLMs nonetheless battle with composing operations into right reasoning paths.

{kind=link}