
Get began with machine studying utilizing Snowpark Python

In case you are working as a Information Scientist in a enterprise setting you’ll extract a lot of your knowledge for machine studying from an information warehouse or knowledge lake. Nearly all of knowledge science tasks require large-scale computational energy and entry to the required python libraries to course of huge volumes of knowledge and prepare machine studying fashions.
Usually knowledge is moved to a different location, reminiscent of cloud storage buckets, the place it may be made obtainable to the usual knowledge science instrument equipment.
This example ends in a fragmentation within the machine studying workflow which is one thing many cloud suppliers are searching for to resolve. I’ve beforehand written about BigQueryML, a Google Cloud Platform (GCP) instrument which permits machine studying fashions to be developed and educated purely utilizing SQL inside GCP’s knowledge warehouse platform.
Snowflake, a cloud-based knowledge and analytics platform, just lately made obtainable one other instrument which seeks to streamline the information science workflow in the same approach.
The Snowpark Python API permits machine studying fashions to be developed, educated and deployed inside Snowflake utilizing the instruments that knowledge scientists are accustomed to. As with BigQueryML, fashions may be developed with out knowledge ever having to go away the placement the place it’s saved, nonetheless, with Snowpark fairly than writing code in SQL an information scientist can now use Python.
On this article, I’ve written a short information to getting began with machine studying utilizing Snowpark. This isn’t meant as an exhaustive information to machine studying itself so I’ll skip over just a few steps within the traditional workflow reminiscent of exploratory knowledge evaluation and have engineering. It’s supposed to provide a fundamental introduction to at least one software of the API.
A lot of the code on this tutorial was closely impressed by the examples put collectively by the staff at Snowflake which may be discovered on this Github repo.
Snowflake is somewhat totally different to different knowledge warehouse instruments you will have used and so it is perhaps helpful to first get an understanding of some widespread phrases within the Snowflake context.
Database: A Snowflake database consists of optimised knowledge storage. Usually a database accommodates quite a lot of schemas and every schema will include a number of tables. On this tutorial, we are going to utilise a database to retailer coaching knowledge and predictions.
Warehouse: Snowflake makes obtainable impartial compute clusters for large-scale question processing. Every compute cluster is named a digital warehouse. These warehouses may be sized relying in your processing wants. We are going to use the warehouse compute to carry out mannequin coaching and inference.
Stage: A stage is a storage location used to retailer knowledge and artifacts to be used inside Snowflake. On this tutorial, we shall be utilizing a stage to retailer our educated mannequin.
Saved process: A saved process is a set of features and operations which is saved in Snowflake for later reuse. Snowpark saved procedures present a mechanism to run python code both through Snowpark or different Python libraries reminiscent of sci-kit-learn utilizing the Snowflake compute. We are going to use saved procedures for performing mannequin coaching.
Person Outlined Operate (UDF): A UDF is one other technique for working Python features in Snowflake. These differ from saved procedures in quite a lot of methods. This article describes intimately the variations between the 2. We shall be utilizing a UDF on this tutorial to generate inferences utilizing the educated mannequin.
For those who don’t have already got entry to Snowflake you possibly can join a free trial right here. After getting signed up you will want to configure a database, warehouse, and schema. Snowflake has a terrific 20-minute information for this right here.
For the rest of this tutorial, I’ll assume you have already got configured Snowflake sources.
The setup a part of this text walks by means of a neighborhood set up of Snowpark. The setup is predicated on macOS.
Snowpark makes use of Anaconda environments inside Snowflake to handle Python packages. It’s due to this fact most optimum to duplicate this setting regionally, though virtualenv may also be used.
To put in Anaconda run the next command.
$ brew set up --cask anaconda
Subsequent add the next to your .zshrc file.
export PATH="/usr/native/anaconda3/bin:$PATH"
Now you possibly can create the conda setting by working the next. SnowPark at present solely works with Python 3.8.
$ conda create --name py38_env -c https://repo.anaconda.com/pkgs/snowflake python=3.8 numpy pandas sklearn
Run the next to initialise conda. You’ll solely have to run this as soon as.
$ conda init zsh
To activate the setting run.
$ conda activate my_env
As soon as contained in the setting set up snowpark and Jupyter notebooks.
$ conda set up snowflake-snowpark-python$ conda set up pocket book
To run the Jupyter Pocket book kind the next.
$ jupyter pocket book
Jupyter notebooks will launch with a Python 3 kernel obtainable. My kernel is proven within the picture beneath.

After getting arrange your native set up of Snowpark you can begin working code. All operations carried out utilizing the Snowpark API run on Snowflake warehouse compute.
To start out utilizing this compute it’s essential create a Snowpark session which lets you authenticate and create a connection along with your database and warehouse.
To start out a Snowflake session we kind and execute the next:
For the rest of this tutorial, we’re going to use Snowpark to arrange a dataset, prepare a machine studying mannequin after which use the mannequin to generate predictions.
We’re going to be utilizing the ‘credit-g’ dataset from openml.org. This consists of quite a lot of options for banking prospects with a label indicating if they’re good or very bad credit dangers. The dataset may be downloaded utilizing the sklearn API as proven beneath.
We subsequent wish to write the dataframe again to Snowflake to make use of for coaching the mannequin.
The next code transforms the pandas dataframe to a Snowpark dataframe, after which writes this as a desk into Snowflake. We additionally reserve a small dataset for later testing inference utilizing the educated mannequin. That is additionally saved as a desk inside Snowflake.
For mannequin coaching, we are going to create a saved process. Earlier than doing so we have to add the packages we intend to make use of to the session as proven beneath.
We will now create the saved process. The code right here splits the information into check and prepare units, and makes use of a scikit-learn pipeline to carry out preprocessing and coaching. The mannequin is educated, saved to a specified stage and a classification report is returned.
Now that we have now educated the mannequin we wish to check producing predictions on the inference dataset we reserved earlier.
Earlier than we do that we have to add the mannequin location to the session.
Subsequent, we create a UDF to generate predictions utilizing the mannequin.
The next code reads within the knowledge we reserved for inference and makes use of the UDF to generate the predictions.
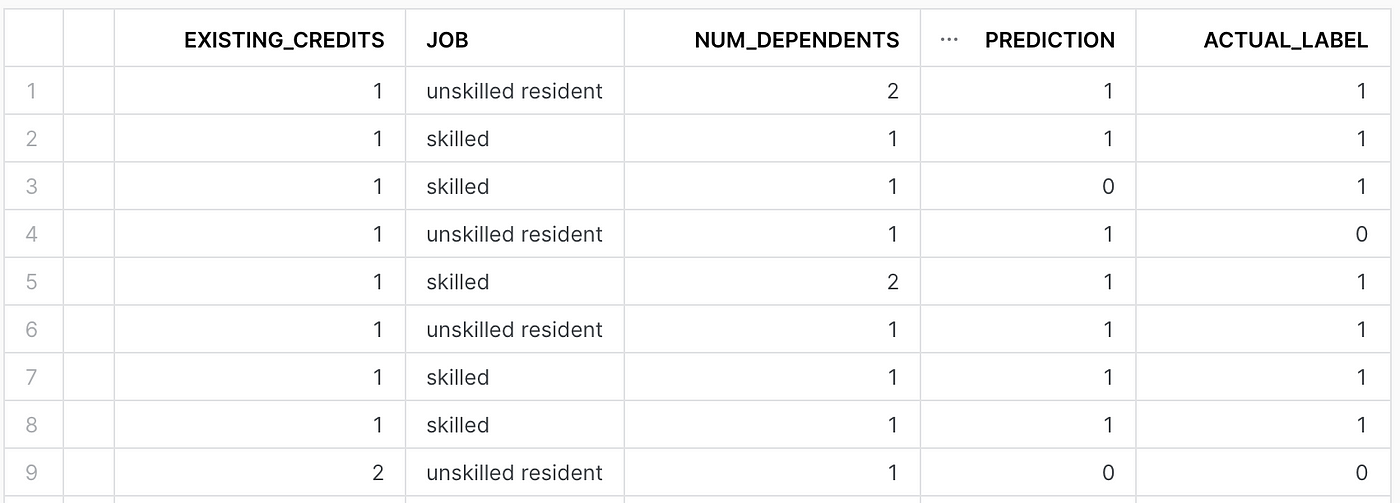
Let’s view the ensuing desk in Snowflake.
The Machine studying area remains to be closely fragmented. The machine studying workflow in a typical organisation is made up of many alternative instruments all performing varied roles within the course of. Information is without doubt one of the areas the place this fragmentation can severely impression the standard and success of machine studying fashions.
The necessity to transfer knowledge from one instrument to a different can lead to a number of copies of the identical knowledge being saved, knowledge high quality points being launched and potential safety breaches. Instruments, reminiscent of Snowpark and BigQueryML, search to minimise this knowledge motion and basically carry knowledge science to the information warehouse.
This tutorial has supplied a easy introduction to a machine studying workflow, together with coaching and deployment, with the Snowpark Python API. There’s way more to the instrument than I’ve shared right here and plenty of potential choices for attaining knowledge science workflows. For a extra complete information, I refer again to the Snowpark examples linked initially of the article.
Thanks for studying!

{kind=link}