
With Intel’s annual Innovation occasion happening this week in San Jose, the corporate is seeking to recapture loads of technical momentum that has slowly been misplaced over the previous couple of years. Whereas Intel has remained arduous at work releasing new merchandise over the time, the mixture of schedule slips and an incapacity to point out off their wares to in-person audiences has taken a few of the luster off the corporate and its merchandise. So for his or her greatest in-person technical occasion since previous to the pandemic, the corporate is displaying off as a lot silicon as they will, to persuade press, companions, and clients alike that CEO Pat Gelsinger’s efforts have put the corporate again on monitor.
Of all of Intel’s struggles over the previous couple of years, there isn’t a higher poster baby than their Sapphire Rapids server/workstation CPU. A real next-generation product from Intel that brings all the things from PCIe 5 and DDR5 to CXL and a slew of {hardware} accelerators, there’s actually nothing to put in writing about Sapphire Rapids’ delays that hasn’t already been stated – it’s going to finish up over a 12 months late.
However Sapphire Rapids is coming. And Intel is lastly capable of see the sunshine on the finish of the tunnel on these growth efforts. With common availability slated for Q1 of 2023, simply over 1 / 4 from now, Intel is lastly ready to point out off Sapphire Rapids to a wider viewers – or no less than, members of the press. Or to take a extra pragmatic learn on issues, Intel now wants to begin significantly selling Sapphire Rapids forward of its launch, and that of its competitors.
For this 12 months’s present, Intel invited members of the press to see a dwell demo of pre-production Sapphire Rapids silicon in motion. The aim of the demos, in addition to to offer the press the power to say “we noticed it; it exists!” is to begin displaying off one of many extra distinctive options of Sapphire Rapids: its assortment of devoted accelerator blocks.
Together with delivering a much-needed replace to the CPU’s processor cores, Sapphire Rapids can be including/integration devoted accelerator blocks for a number of widespread CPU-critical server/workstation workloads. The thought, merely put, is that mounted perform silicon can do the duty as rapidly or higher than CPU cores for a fraction of the facility, and for under a fractional enhance in die measurement. And with hyperscalers and different server operators searching for large enhancements in compute density and vitality effectivity, area particular accelerators similar to these are a great way for Intel to ship that sort of edge to their clients. And it doesn’t damage both that rival AMD isn’t anticipated to have related accelerator blocks.
A Fast Look At Sapphire Rapids Silicon
Earlier than we get any additional, right here’s a really fast take a look at the Sapphire Rapids silicon.

For his or her demos (and eventual reviewer use), Intel has assembled some twin socket Sapphire Rapids techniques utilizing pre-production silicon. And for picture functions, they’ve popped open one system and popped out the CPU.

There’s not a lot we are able to say in regards to the silicon at this level past the truth that it really works. Because it’s nonetheless pre-production, Intel isn’t disclosing clockspeeds or mannequin numbers – or what errata has resulted in it being non-final silicon. However what we do know is that these chips have 60 CPU cores up and working, in addition to the accelerator blocks that had been the topic of at the moment’s demonstrations.
Sapphire Rapids’ Accelerators: AMX, DLB, DSA, IAA, and AMX
Not counting the AVX-512 items on the Sapphire Rapids CPU cores, the server CPUs might be transport with 4 devoted accelerators inside every CPU tile.
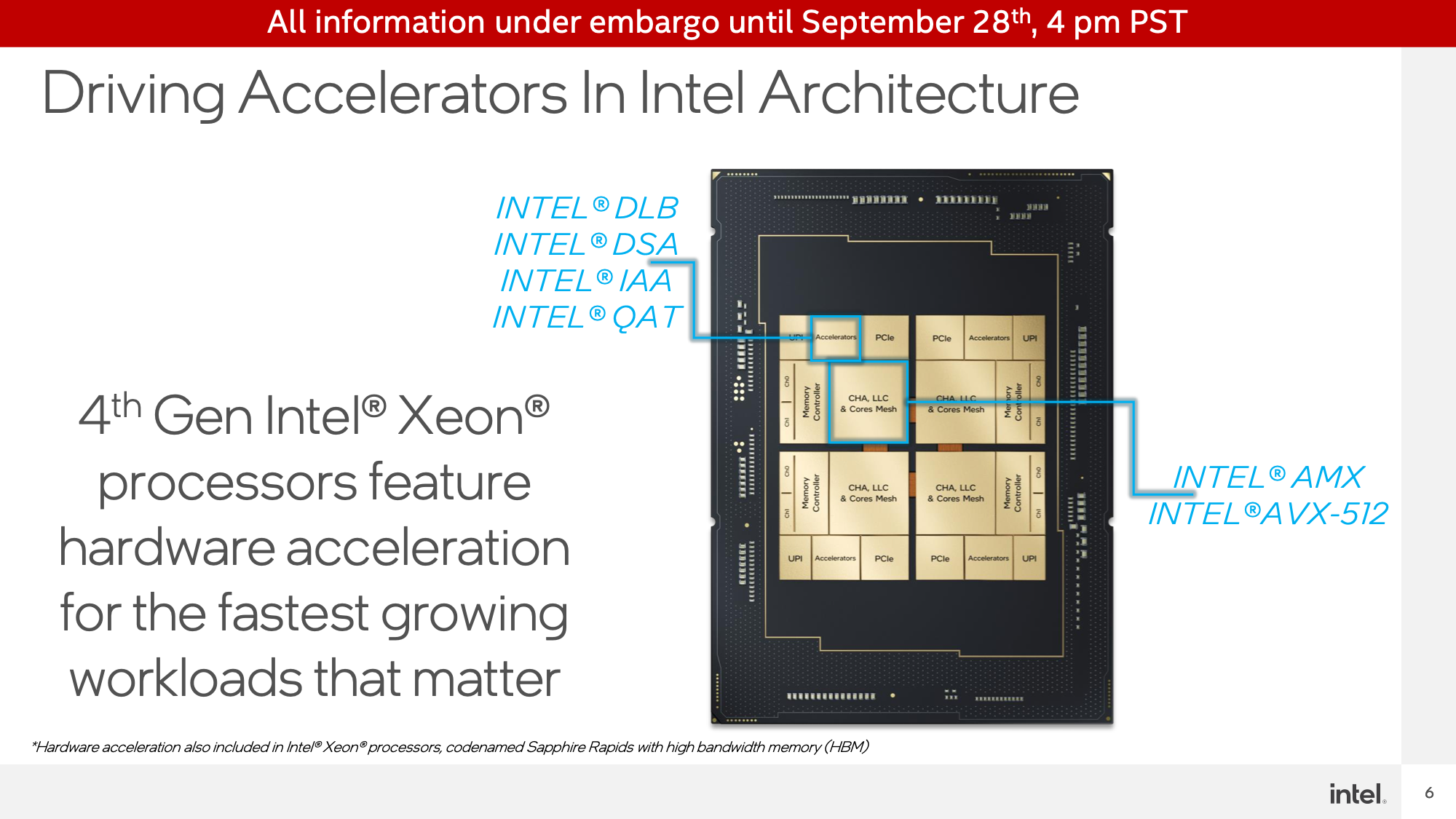
These are Intel Dynamic Load Balancer (DLB), Intel Information Streaming Accelerator (DSA), Intel In-Reminiscence Analytics Accelerator (IAA), and Intel QuickAssist Expertise (QAT). All of those grasp off of the chip mesh as devoted units, and primarily perform as PCIe accelerators which were built-in into the CPU silicon itself. This implies the accelerators don’t eat CPU core assets (reminiscence and I/O are one other matter), however it additionally means the variety of accelerator cores obtainable doesn’t straight scale up with the variety of CPU cores.
Of those, all the things however QAT is new to Intel. QAT is the exception because the earlier era of that know-how was applied within the PCH (chipset) used for 3rd era Xeon (Ice Lake-SP) processors, and as of Sapphire Rapids is being built-in into the CPU silicon itself. Consequently, whereas Intel implementing area particular accelerators will not be a brand new phenomena, the corporate goes all-out on the concept for Sapphire Rapids.

All of those devoted accelerator blocks are designed to dump a particular set of high-throughput workloads. DSA, for instance, accelerates information copies and easy computations similar to calculating CRC32s. In the meantime QAT is a crypto acceleration block in addition to a knowledge compression/decompression block. And IAA is analogous, offing on-the-fly information compression and decompression to permit for giant databases (i.e. Huge Information) to be held in reminiscence in a compressed type. Lastly, DLB, which Intel didn’t demo at the moment, is a block for accelerating load balancing between servers.
Lastly, there’s Superior Matrix Extension (AMX), Intel’s previously-announced matrix math execution block. Just like tensor cores and different kinds of matrix accelerators, these are ultra-high-density blocks for effectively executing matrix math. And in contrast to the opposite accelerator sorts, AMX isn’t a devoted accelerator, slightly it’s part of the CPU cores, with every core getting a block.
AMX is Intel’s play for the deep studying market, going above and past the throughput they will obtain at the moment with AVX-512 through the use of even denser information constructions. Whereas Intel can have GPUs that transcend even this, for Sapphire Rapids Intel is seeking to tackle the shopper phase that wants AI inference happening very near CPU cores, slightly than in a much less versatile, extra devoted accelerator.
The Demos
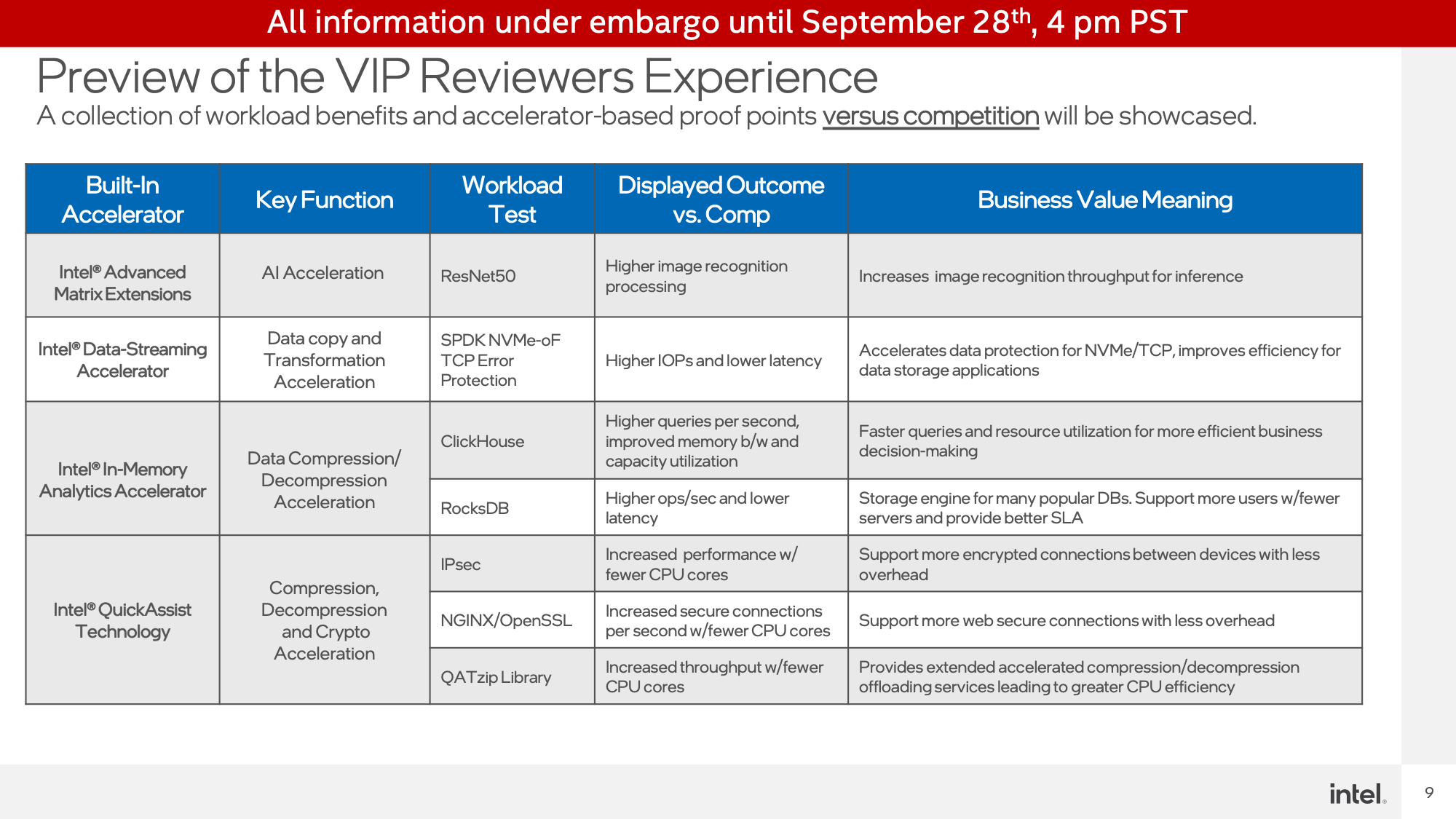
For at the moment’s press demo, Intel introduced out their take a look at crew to setup and showcase sequence of real-world demos that leverage the brand new accelerators and might be benchmarked to showcase their efficiency. For this Intel was seeking to exhibit the benefits over each unaccelerated (CPU) operation on their very own Sapphire Rapids {hardware} – i.e. why you must use their accelerators in these fashion of workloads – in addition to to showcase the efficiency benefit versus executing the identical workloads on arch rival AMD’s EPYC (Milan) CPUs.
Intel, in fact, has already run the information internally. So the aim of those demos was, in addition to revealing these efficiency numbers, to showcase that the numbers had been actual and the way they had been getting them. Make no mistake, that is Intel wanting to place its greatest foot ahead. However it’s doing so with actual silicon and actual servers, in workloads that (to me) look like cheap duties for the take a look at.

QuickAssist Expertise Demo
First up was a demo for the QuickAssist Expertise(QAT) accelerator. Intel began with a NGINX workload, measuring OpenSSL crypto efficiency.
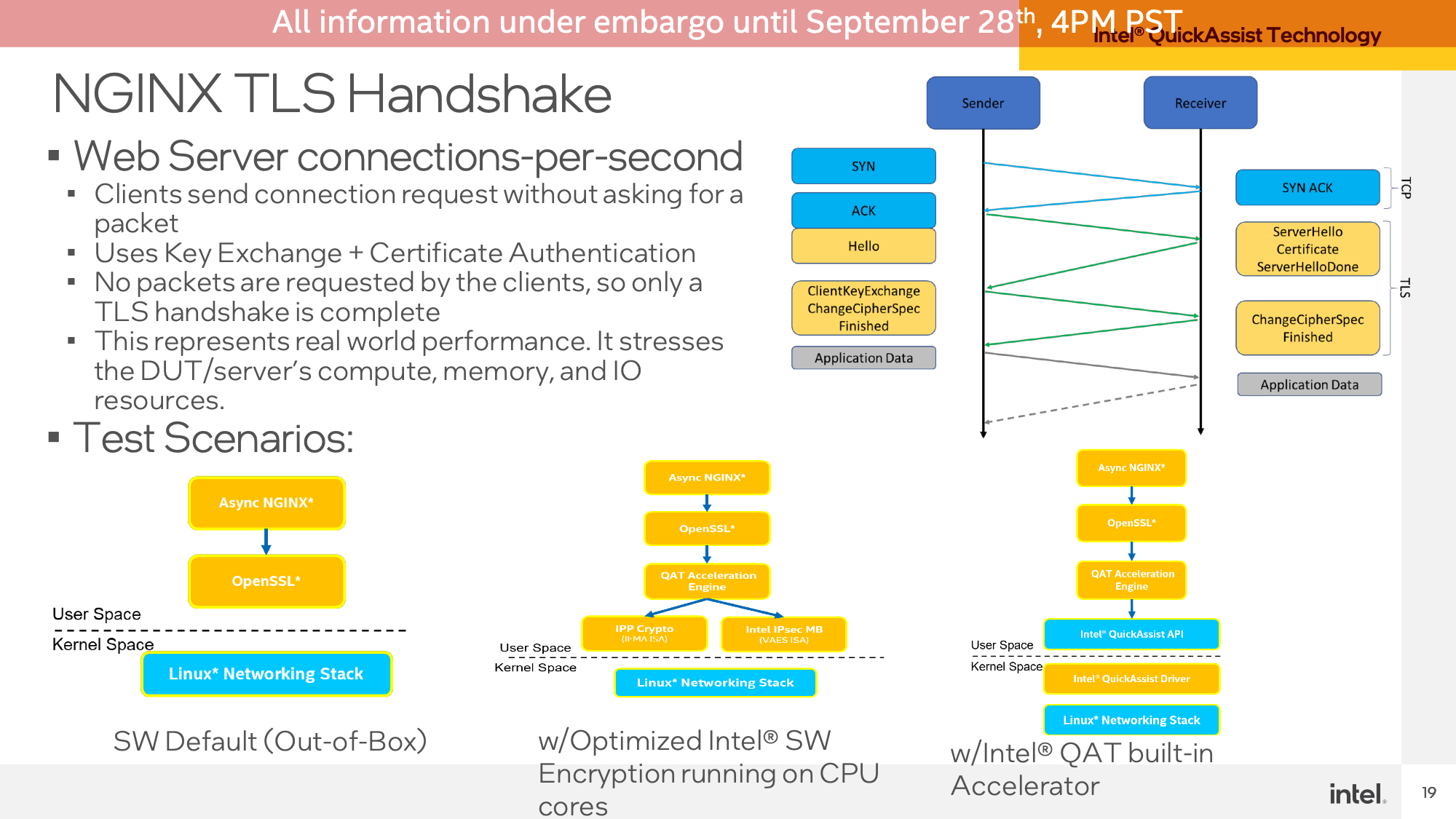
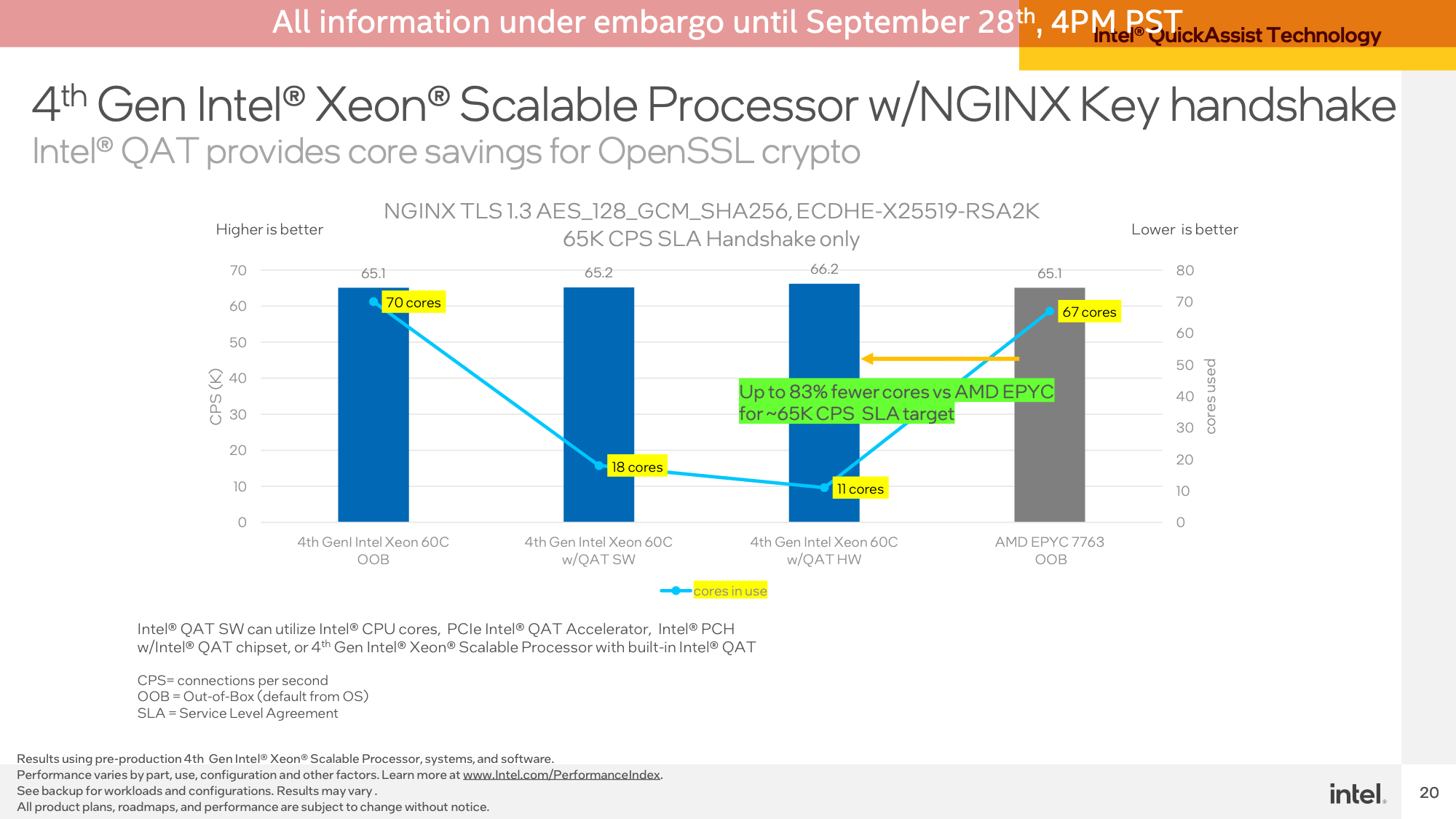
Aiming for roughly iso-performance, Intel was capable of obtain roughly 66K connections per second on their Sapphire Rapids server, utilizing simply the QAT accelerator and 11 of the 120 (2×60) CPU cores to deal with the non-accelerated bits of the demo. This compares to needing 67 cores to realize the identical throughput on Sapphire Rapids with none sort of QAT acceleration, and 67 cores on a twin socket EPYC 7763 server.

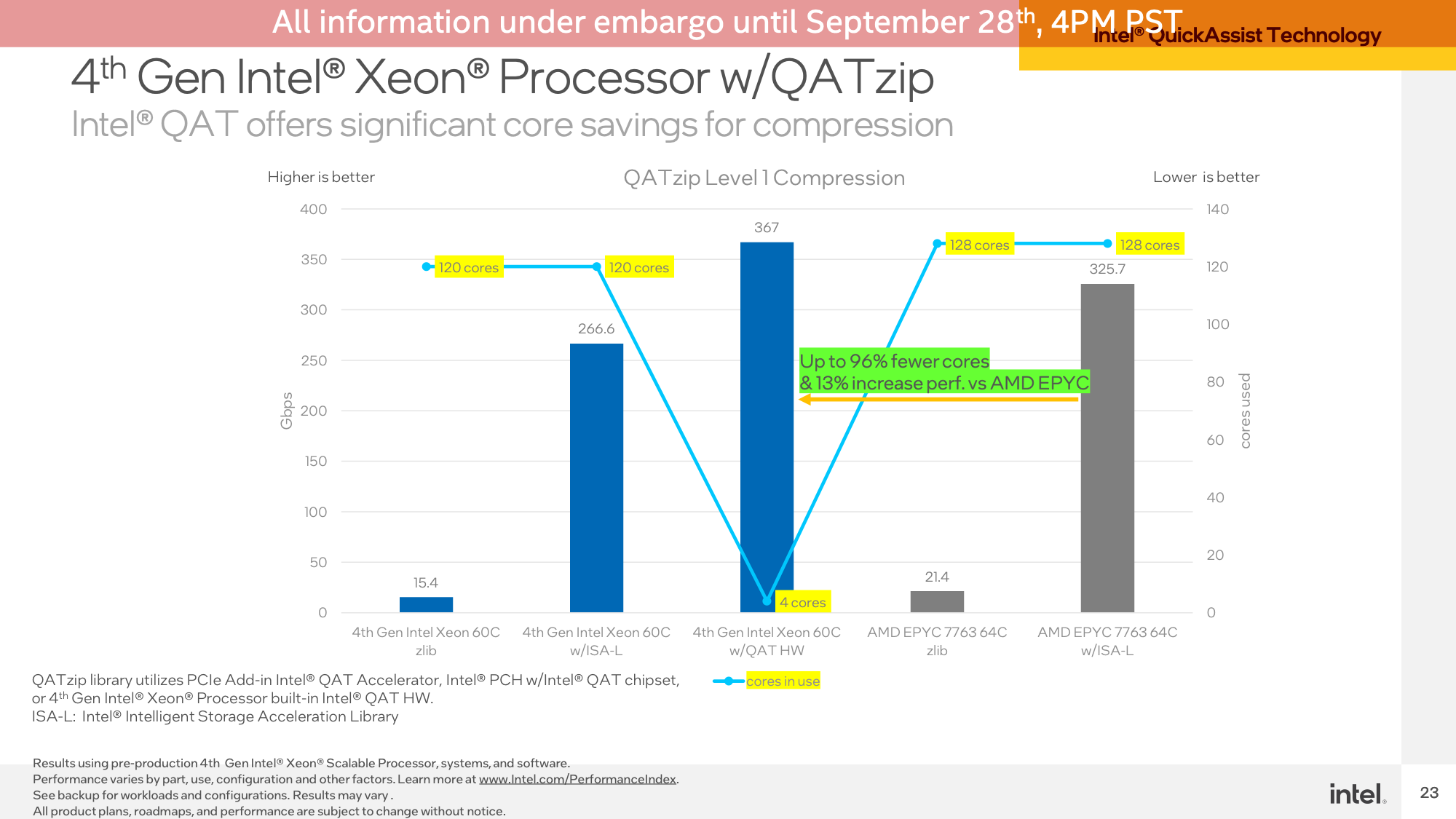
The second QAT demo was measuring compression/decompression efficiency on the identical {hardware}. As you’d count on for a devoted accelerator block, this benchmark was a blow-out. The QAT {hardware} accelerator blew previous the CPUs, even coming in forward of them once they used Intel’s extremely optimized ISA-L library. In the meantime this was an nearly entirely-offloaded job, so it was consuming 4 CPU cores’ time versus all 120/128 CPU cores within the software program workloads.

In-Reminiscence Analytics Accelerator Demo
The second demo was of the In-Reminiscence Analytics Accelerator. Which, regardless of the identify, doesn’t really speed up the precise analyzing portion of the duty. Somewhat it’s a compression/decompression accelerator primed to be used with databases in order that they are often operated on in reminiscence with out a huge CPU efficiency value.
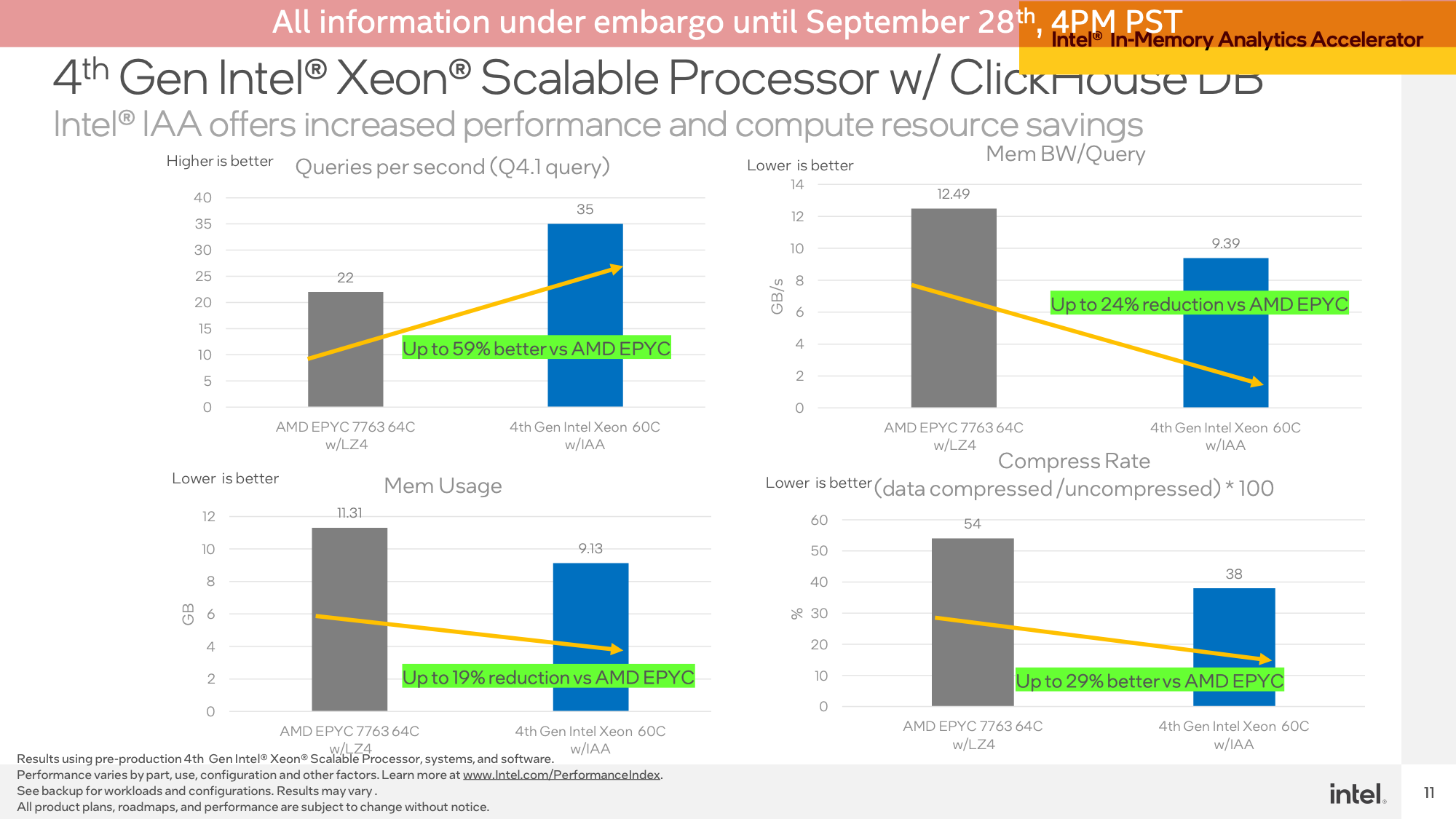
Operating the demo on a ClickHouse DB, this state of affairs demonstrated the Sapphire Rapids system seeing a 59% queries-per-second efficiency benefit versus an AMD EPYC system (Intel didn’t run a software-only Intel setup), in addition to lowered reminiscence bandwidth utilization and lowered reminiscence utilization total.
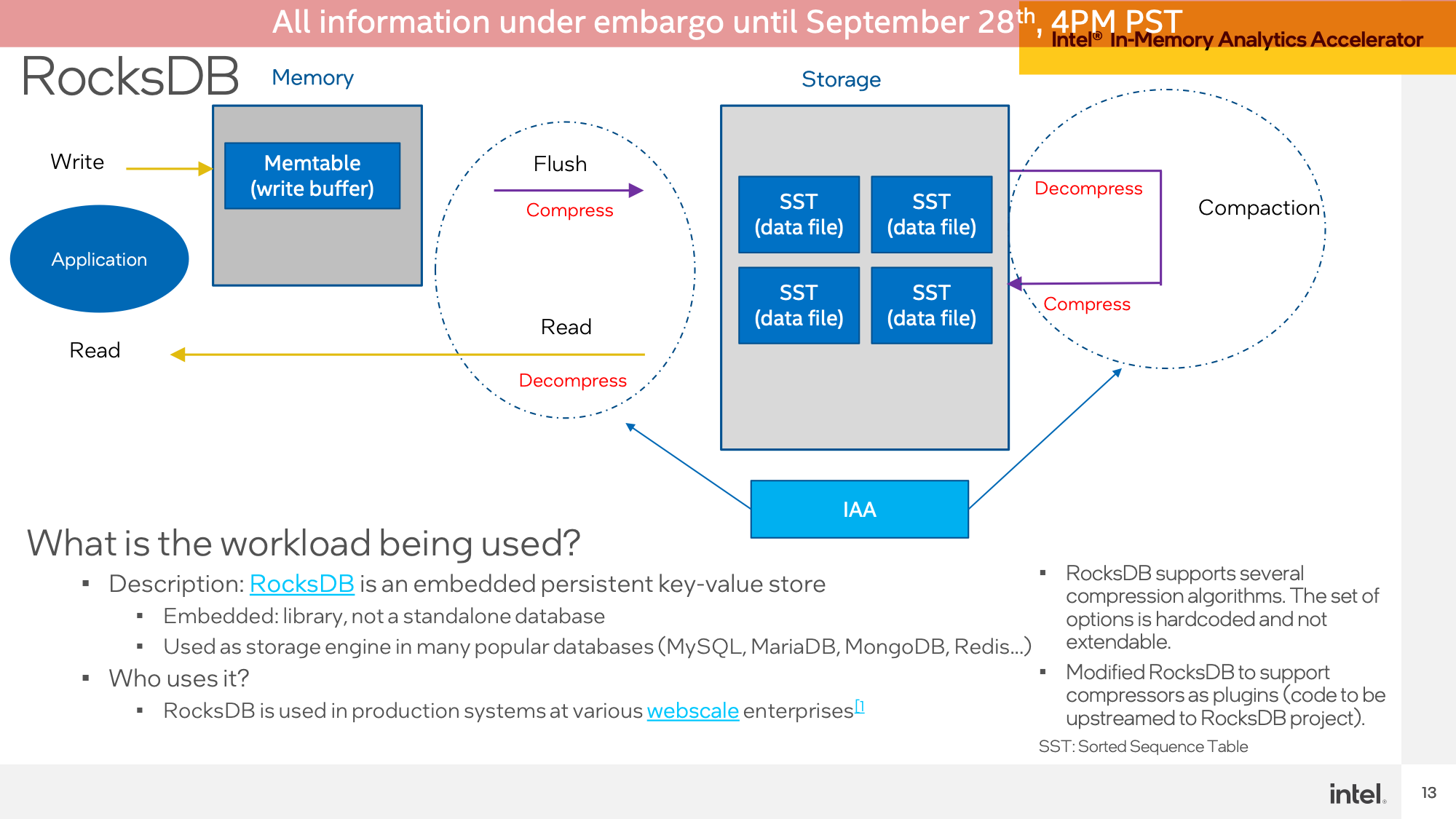
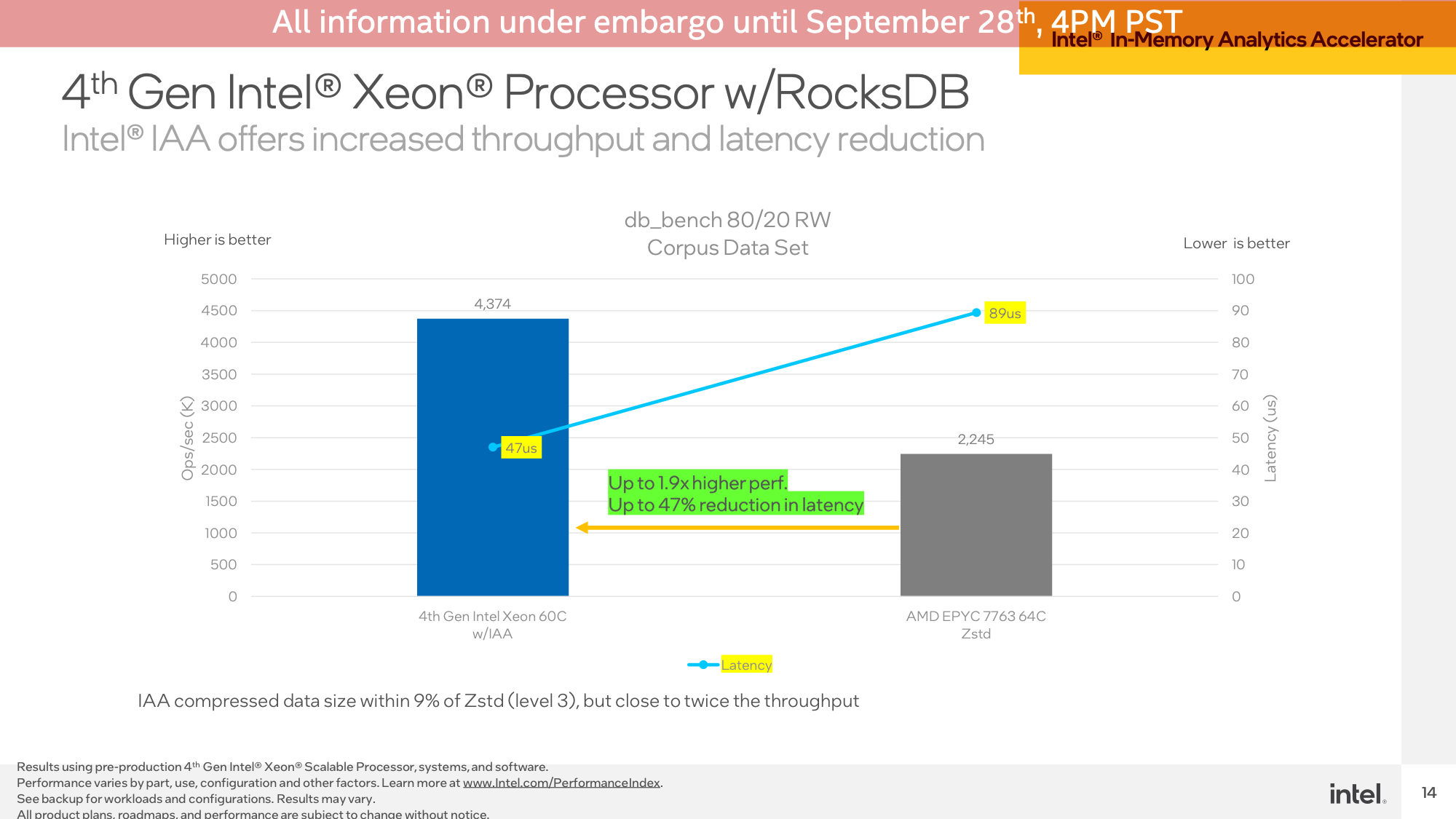
The second IAA demo was a set in opposition to RocksDB with the identical Intel and AMD techniques. As soon as once more Intel demonstrated the IAA-accelerated SPR system popping out effectively forward, with 1.9x greater efficiency and practically half-lower latency.

Superior Matrix Extensions Demo
The ultimate demo station Intel had setup was configured for showcasing Superior Matrix Extensions (AMX) and the Information Streaming Accelerator (DSA).
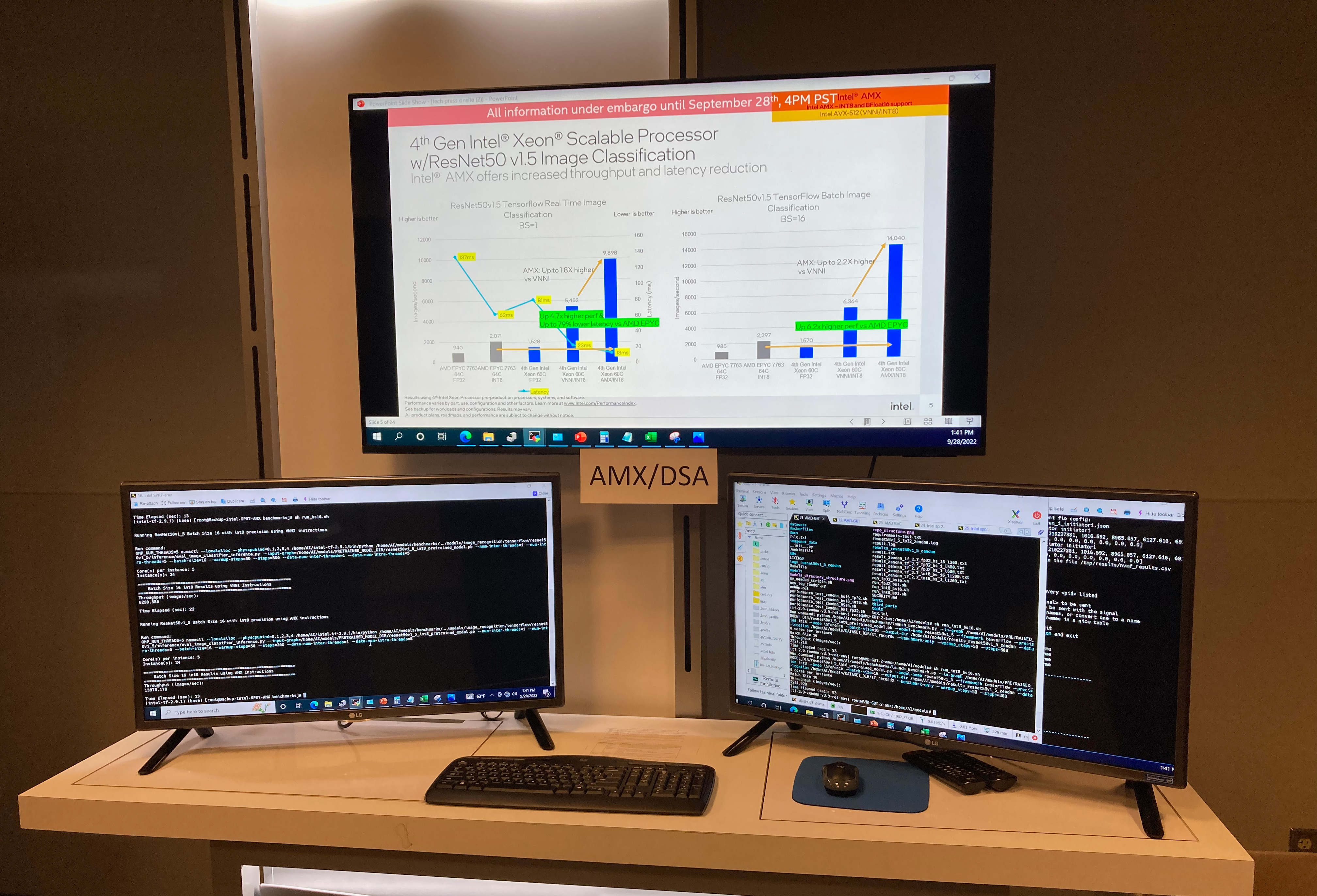
Beginning with AMX, Intel ran a picture classification benchmark utilizing TensorFlow and the ResNet50 neural community. This take a look at used unaccelerated FP32 operations on the CPUs, AVX-512 accelerated INT8 on Sapphire Rapids, and at last AMX-accelerated INT8 additionally on Sapphire Rapids.


This was one other blow-out for the accelerators. Because of the AMX blocks on the CPU cores, the Sapphire Rapids system delivered slightly below a 2x efficiency enhance over AVX-512 VNNI mode with a batch measurement of 1, and over 2x with a batch measurement of 16. And, in fact, the state of affairs appears much more favorable for Intel in comparison with the EPYC CPUs for the reason that present Milan processors don’t supply AVX-512 VNNI. The general efficiency good points right here aren’t as nice as going from pure CPU to AVX-512, however then AVX-512 was already part-way to being a matrix acceleration block by itself (amongst different issues).
Information Streaming Accelerator Demo
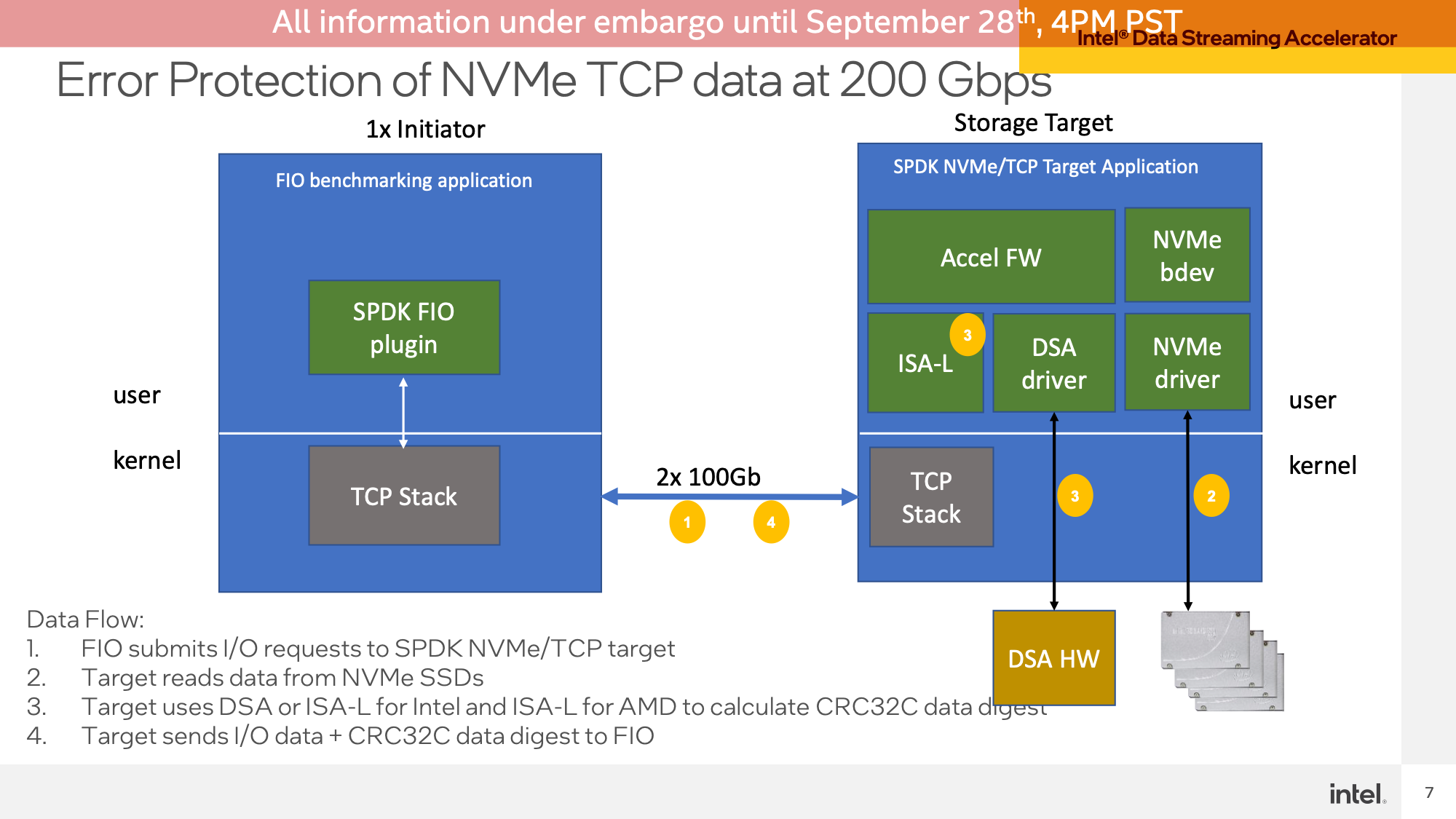
Lastly, Intel demoed the Information Streaming Accelerator (DSA) block, which is again to showcasing devoted accelerator blocks on Sapphire Rapids. On this take a look at, Intel setup a community switch demo utilizing FIO to have a shopper learn information from a Sapphire Rapids server. DSA is used right here to dump the CRC32 calculations used for the TCP packets, an operation that provides up rapidly by way of CPU necessities on the very excessive information charges Intel was testing – a 2x100GbE connection.
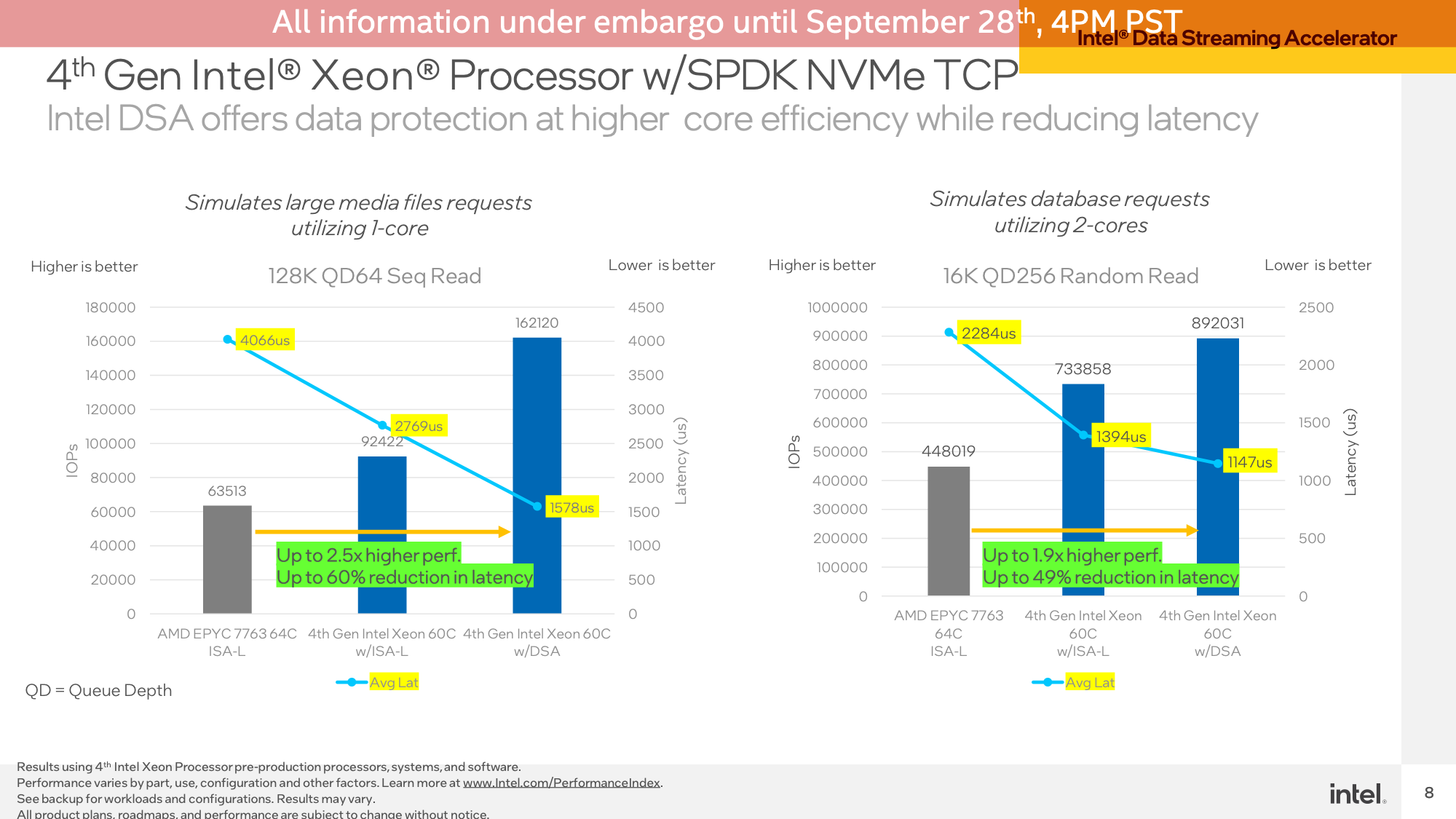
Utilizing a single CPU core right here to showcase effectivity (and since just a few CPU cores can be sufficient to saturate the hyperlink), the DSA block allowed Sapphire Rapids to ship 76% extra IOPS on a 128K QD64 sequential learn as in comparison with simply utilizing Intel’s optimized ISA-L library on the identical workload. The lead over the EPYC system was even better, and the latency with DSA was introduced effectively underneath 2000us.
An identical take a look at was additionally performed with a smaller 16K QD256 random learn, working in opposition to 2 CPU cores. The efficiency benefit for DSA was not as nice right here – simply 22% versus optimized software program on Sapphire Rapids – however once more the benefit over EPYC was better, and latencies had been decrease.
First Ideas
And there you’ve gotten it: the primary press demo of the devoted accelerator blocks (and AMX) on Intel’s 4th Technology Xeon (Sapphire Rapids) CPU. We noticed it, it exists, and it is the tip of the iceberg for all the things that Sapphire Rapids is slated to convey to clients beginning subsequent 12 months.
Given the character of and the aim for area particular accelerators, there’s nothing right here that I really feel ought to come as a terrific shock to common technical readers. DSAs exist exactly to speed up specialised workloads, notably those who would in any other case be CPU and/or vitality intensive, and that’s what Intel has performed right here. And with the competitors within the server market anticipated to be a sizzling one for common CPU efficiency, these accelerator blocks are a method for Intel so as to add additional worth to their Xeon processors, in addition to stand out from AMD and different rivals which can be pushing even bigger numbers of CPU cores.
Anticipate to see extra on Sapphire Rapids over the approaching months, as Intel will get nearer to lastly transport their next-generation server CPU.

{kind=link}