[Ed. note: This article comes from a Tweet first posted here. We’ve partnered with Cameron Wolfe to present his insights a wider viewers, as we expect they supply perception into numerous matters round GenAI.]
Combination of specialists (MoE) has arisen as a brand new method to enhance LLM efficiency. With the discharge of Grok-1 and the continued recognition of Mistral’s MoE mannequin, it is a good time to check out what this method does.
When utilized to transformer fashions, MoE layers have two major parts:
- Sparse MoE Layer: replaces dense feed-forward layers within the transformer with a sparse layer of a number of, similarly-structured “specialists”.
- Router: determines which tokens within the MoE layer are despatched to which specialists.
Every professional within the sparse MoE layer is only a feed-forward neural community with its personal impartial set of parameters. The structure of every professional mimics the feed-forward sub-layer utilized in the usual transformer structure. The router takes every token as enter and produces a chance distribution over specialists that determines to which professional every token is distributed. On this method, we drastically improve the mannequin’s capability (or variety of parameters) however keep away from extreme computational prices by solely utilizing a portion of the specialists in every ahead go.
Decoder-only structure. Almost all autoregressive giant language fashions (LLMs) use a decoder-only transformer structure. This structure consists of transformer blocks that comprise masked self-attention and feed-forward sub-layers. MoEs modify the feed-forward sub-layer throughout the transformer block, which is only a feed-forward neural community by way of which each and every token throughout the layer’s enter is handed.
Creating an MoE layer. In an MoE-based LLM, every feed-forward sub-layer within the decoder-only transformer is changed with an MoE layer. This MoE layer is comprised of a number of specialists, the place every of those specialists is a feed-forward neural community—having an identical structure to the unique feed-forward sub-layer—with an impartial set of parameters. We will have anyplace for just a few specialists to 1000’s of specialists. Grok particularly has eight specialists in every MoE layer
Sparse activation. The MoE mannequin has a number of impartial neural networks (i.e., as an alternative of a single feed-forward neural community) inside every feed-forward sub-layer of the transformer. Nevertheless, we solely use a small portion of every MoE layer’s specialists within the ahead go! Given an inventory of tokens as enter, we use a routing mechanism to sparsely choose a set of specialists to which every token will likely be despatched. For that reason, the computational value of an MoE mannequin’s ahead go is far lower than that of a dense mannequin with the identical variety of parameters.
How does routing work? The routing mechanism utilized by most MoEs is an easy softmax gating perform. We go every token vector by way of a linear layer that produces an output of dimension N (i.e., the variety of specialists), then apply a softmax transformation to transform this output right into a chance distribution over specialists. From right here, we compute the output of the MoE layer:
- Deciding on the top-Ok specialists (i.e., ok=2 for Grok)
- Scaling the output of every professional by the chance assigned to it by the router
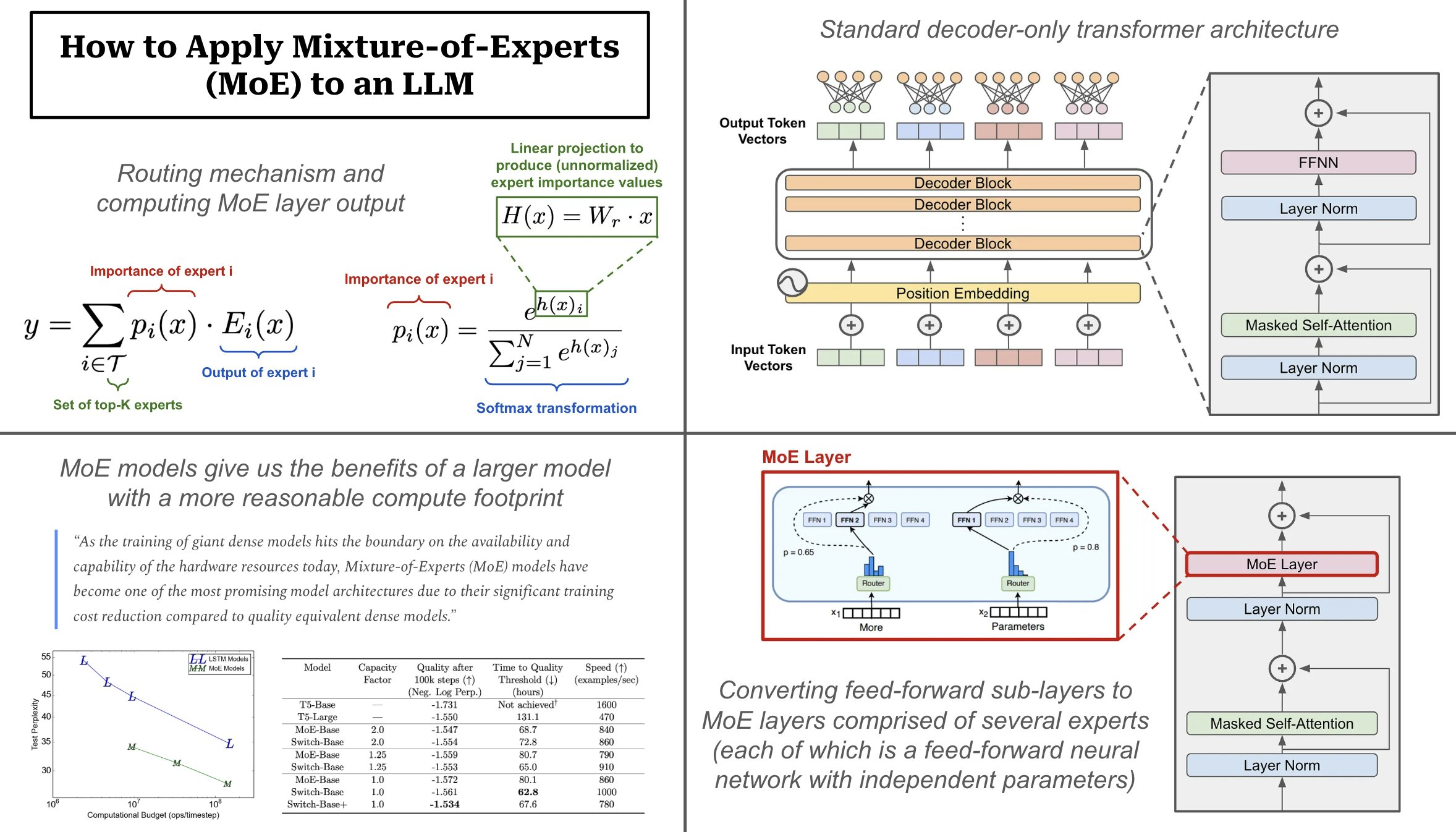
Why are MoEs standard for LLMs? Rising the dimensions and capability of a language mannequin is among the major avenues of enhancing efficiency, assuming that now we have entry to a sufficiently giant coaching dataset. Nevertheless, the price of coaching will increase with the dimensions of the underlying mannequin, which makes bigger fashions burdensome in observe. MoE fashions keep away from this expense by solely utilizing a subset of the mannequin’s parameters throughout inference. For instance, Grok-1 has 314B parameters in complete, however solely 25% of those parameters are energetic for a given token.
For those who’re fascinated by wanting extra into the sensible/implementation facet of MoEs, check out the OpenMoE project! It is one of the best assets on MoEs on the market by far (no less than for my part). OpenMoE is in JAX, however there’s additionally a PyTorch port as nicely.
Take a look at this paper the place we observe fascinating scaling legal guidelines for MoEs.

{kind=link}