
Since the rise of ChatGPT, the general public has realized that generative artificial intelligence (GenAI) could potentially transform our lives. The availability of large language models (LLMs) has also changed how developers build AI-powered applications and has led to the emergence of various new developer tools. Although vector databases have been around long before ChatGPT, they have become an integral part of the GenAI technology stack, as vector databases can address some of LLMs’ key limitations, such as hallucinations and lack of long-term memory
This article first introduces vector databases and their use cases. Next, you will learn more about how vector databases are designed to help developers get started with building GenAI applications quickly. As a developer advocate at Weaviate, an open-source vector database, I will use Weaviate to demonstrate relevant concepts as we go along. In the final discussion, you will learn how they can address the challenges enterprises face when moving these prototypes to production.
What are vector databases?
Vector databases retailer and supply entry to structured and unstructured knowledge, corresponding to textual content or photographs, alongside their vector embeddings. Vector embeddings are the info’s numerical illustration as a protracted checklist of numbers that captures the unique knowledge object’s semantic which means. Normally, machine studying fashions are used to generate the vector embeddings.
As a result of related objects are shut collectively in vector area, the similarity of information objects will be calculated based mostly on the distance between the info object’s vector embeddings. This opens the door to a brand new sort of search method referred to as vector search that retrieves objects based mostly on similarity. In distinction to conventional keyword-based search, semantic search gives a extra versatile technique to seek for objects.
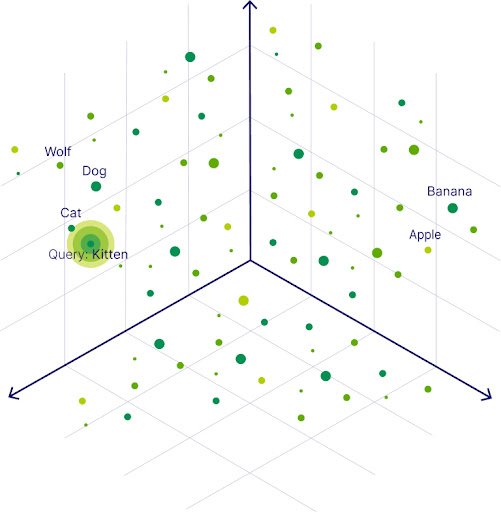
Whereas many conventional databases help storing vector embeddings to allow vector search, vector databases are AI-native, which implies they’re optimized to conduct lightning-fast vector searches at scale. As a result of vector search requires the calculation of the distances between the search question and each knowledge object, a classical Ok-Nearest-Neighbor algorithm is computationally costly. Vector databases use vector indexing to pre-calculate the distances to allow quicker retrieval at question time. Thus, vector databases permit customers to search out and retrieve related objects rapidly at scale in manufacturing.
Use cases of vector databases
Historically, vector databases have been utilized in numerous functions within the search area. Nonetheless, with the rise of ChatGPT, it has develop into extra obvious that vector databases can improve LLMs’ capabilities.
Natural-language search
Historically, vector databases are used to unlock natural-language searches. They permit semantic searches which might be sturdy to totally different terminologies and even typos. Vector searches will be carried out on and throughout any modalities, corresponding to photographs, video, audio, and even their mixtures. This, in flip, permits diversified and highly effective use instances for vector databases, even the place conventional databases couldn’t be used in any respect.
For instance, vector databases are utilized in suggestion programs as a particular use case of search. Additionally, Stack Overflow not too long ago showcased how they used Weaviate to enhance buyer experiences with higher search outcomes.
Enhancing LLM capabilities
With the rise of LLMs, vector databases have proven that they will improve LLM capabilities by performing as an exterior reminiscence. For instance, enterprises use custom-made chatbots as a primary line of buyer help or as technical or monetary assistants to enhance buyer experiences. However for a conversational AI to achieve success, it wants to satisfy three standards:
- It must generate human language/reasoning.
- It wants to have the ability to bear in mind what was mentioned earlier to carry a correct dialog.
- It wants to have the ability to question factual info exterior of the final data.
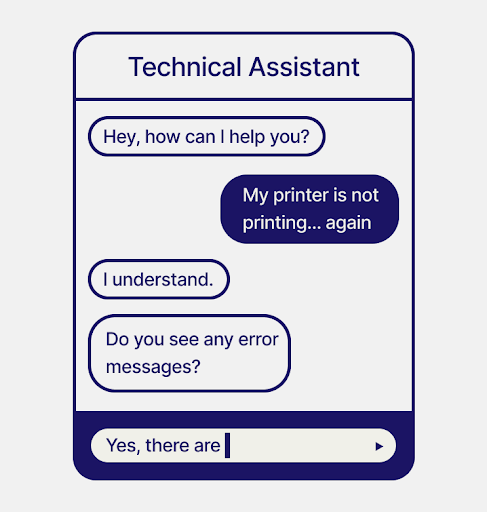
Whereas general-purpose LLMs can cowl the primary criterion, they want help for the opposite two. That is the place vector databases can come into play:
- Give LLMs state: LLMs are stateless. That implies that as soon as an LLM is skilled, its data is frozen. Though you may fine-tune LLMs to increase their data with additional info, as soon as the fine-tuning is completed, the LLM is in a frozen state once more. Vector databases can successfully give LLMs state as a result of you may simply create and replace the knowledge in a vector database.
- Act as an exterior data database: LLMs, like GPT-3, generate confident-sounding solutions independently of their factual accuracy. Particularly when you transfer exterior of the final data into domain-specific areas the place the related information might not have been part of the coaching knowledge, they will begin to “hallucinate” (a phenomenon the place LLMs generate factually incorrect solutions). To fight hallucinations, you should use a vector search engine to retrieve the related factual data and pipe it into the LLM’s context window. This observe is named retrieval-augmented era (RAG) and helps LLMs generate factually correct outcomes.
Prototyping with vector databases
With the ability to quickly prototype is essential not solely in a hackathon setting however to check out new concepts and derive quicker choices in any fast-paced surroundings. As an integral a part of the know-how stack, vector databases ought to assist speed up the event of GenAI functions. This part covers how vector databases allow builders to do speedy prototyping by addressing setup, vectorization, search, and outcomes.
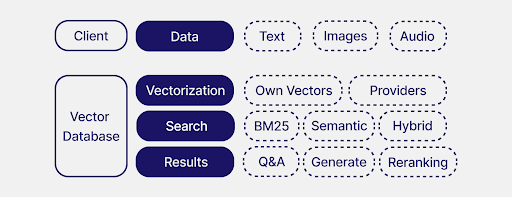
In our instance, we use Weaviate as it’s easy to get began with and solely requires just a few traces of code (to not point out that we’re very acquainted with it).
Easy setup
To allow speedy prototyping, vector databases are often straightforward to arrange in just a few traces of code. On this instance, the setup consists of connecting your Weaviate shopper to your vector database occasion. When you use embedding fashions or LLMs from suppliers, corresponding to OpenAI, Cohere, or Hugging Face, you’ll present your API key on this step to allow their integrations.
import weaviate
shopper = weaviate.Consumer(
url = "<https://your-weaviate-endpoint>",
additional_headers = {
"X-OpenAI-Api-Key": "YOUR-OPENAI-API-KEY"
}
)
Automatic vectorization
Vector databases retailer and question vector embeddings which might be generated from embedding fashions. Which means knowledge should be (manually or routinely) vectorized at import and question time. Whereas you should use vector databases stand-alone (a.ok.a. convey your individual vectors), a vector database that permits speedy prototyping will deal with vectorization routinely so that you simply don’t have to jot down boilerplate code to vectorize your knowledge and queries.
On this instance, you outline a knowledge assortment referred to as MyCollection that gives the construction in your knowledge inside your vector database after the preliminary setup. On this step, you may configure additional modules, corresponding to a vectorizer that routinely vectorizes all knowledge objects throughout import and question time (on this case, text2vec-openai). You possibly can omit this line of code if you wish to use the vector database standalone and supply your individual vectors.
class_obj = {
"class": "MyCollection",
"vectorizer": "text2vec-openai",
}
shopper.schema.create_class(class_obj)
To populate the info assortment MyCollection, import knowledge objects in batches, as proven under. The information objects are vectorized routinely with the outlined vectorizer.
shopper.batch.configure(batch_size=100) *# Configure batch
# Initialize batch course of*
with shopper.batch as batch:
batch.add_data_object(
class_name="MyCollection",
data_object={ "some_text_property": "foo", "some_number_property": 1 }
)The outline vectorizer additionally vectorizes the question at search time, as proven within the subsequent part.
Enable better search
The important thing use of vector databases is to allow semantic similarity search. On this instance, as soon as the vector database is ready up and populated, you may retrieve knowledge from it based mostly on the similarity to the search question (“My question right here”). When you outlined a vectorizer within the earlier step, it would additionally vectorize the question and retrieve knowledge closest to it within the vector area.
response = (
shopper.question
.get("MyCollection", ["some_text"])
.with_near_text({"ideas": ["My query here"]})
.do()
)Nonetheless, lexical and semantic search aren’t mutually unique ideas. Vector databases additionally retailer the unique knowledge objects alongside their vector embeddings. This not solely eliminates the necessity for a secondary database to host your authentic knowledge objects but additionally permits keyword-based searches (BM25). The mixture of keyword-based search and vector search as a hybrid search can enhance search outcomes. For instance, Stack Overflow has carried out hybrid search with Weaviate to realize higher search outcomes.
Integration with the technology stack
As a result of vector databases have develop into an integral a part of the GenAI know-how stack, they should be tightly built-in with the opposite parts. For instance, an integration between a vector database and an LLM will relieve builders from having to jot down separate items of boilerplate code to retrieve info from the vector database after which to feed it to the LLM. As an alternative, it would allow builders to do that in only a few traces of code.
For instance, Weaviate’s modular ecosystem lets you combine state-of-the-art generative fashions from suppliers, corresponding to OpenAI,Cohere, or Hugging Face, by defining a generative module (on this case, generative-openai). This lets you prolong the semantic search question (with the .with_generate() methodology) to a retrieval-augmented generative question. The .with_near_text() methodology first retrieves the related context for the property some_text, which is then used within the immediate “Summarize {some_text} in a tweet”.
class_obj = {
"class": "MyCollection",
"vectorizer": "text2vec-openai",
"moduleConfig": {
"text2vec-openai": {},
"generative-openai": {}
}
}
# ...
response = (
shopper.question
.get("MyCollection", ["some_text"])
.with_near_text({"ideas": ["My query here"]})
.with_generate(
single_prompt="Summarize {some_text} in a tweet."
)
.do()
)
Considerations for vector databases in production
Though it’s straightforward to construct spectacular prototypes for GenAI functions, shifting them to manufacturing comes with its personal challenges concerning deployment and entry administration. This part discusses ideas that you want to consider when shifting GenAI options from prototype to manufacturing efficiently.
Horizontal scalability
Whereas the quantity of information in a prototype might not even require the search capabilities of a full-blown vector database, the quantity of dealt with knowledge will be drastically totally different in manufacturing. To anticipate the quantity of information in manufacturing, vector databases should have the ability to scale into billions of information objects in line with numerous wants, corresponding to most ingestion, largest doable dataset measurement, most of queries per second, and so forth.
To allow lightning-fast vector searches at scale, vector databases use vector indexing. Vector indexing is what units vector databases other than different vector-capable databases that help vector search however aren’t optimized for it. For instance, Weaviate makes use of hierarchical navigable small world (HNSW) algorithms for vector indexing together with product quantization on compressed vectors to unlock decreased reminiscence utilization and lightning-fast vector search even with filters. It usually performs nearest-neighbor searches of hundreds of thousands of objects in lower than 100ms.
Deployment
A vector database ought to have the ability to tackle totally different deployment necessities of assorted manufacturing environments. For instance, Stack Overflow required a vector database that needed to be open-source and never hosted in order that it may very well be run on their present Azure infrastructure.
To deal with such necessities, totally different vector databases include totally different deployment choices:
- Managed providers: Most vector databases supply totally managed knowledge infrastructure. Moreover, some vector databases supply hybrid SaaS choices to handle the info airplane inside your individual cloud surroundings.
- Carry Your Personal Cloud: Some vector databases are additionally out there on totally different cloud marketplaces, permitting you to deploy the vector database cluster inside your individual cloud surroundings.
- Self-hosted: Many vector databases are additionally out there as an open-source obtain, which runs on and scales by way of Kubernetes or Docker Compose.
Data protection
Whereas choosing the proper deployment infrastructure is a necessary a part of making certain knowledge safety, entry administration, and useful resource isolation are as essential to satisfy compliance laws and guarantee knowledge safety. E.g., if person A uploads a doc, solely person A ought to have the ability to work together with it. Weaviate makes use of a multi-tenancy idea means that you can adjust to regulatory knowledge dealing with necessities (e.g., GDPR).
Summary
This text supplies an outline of vector databases and their use instances. It highlights the significance of vector databases in bettering search and enhancing LLM capabilities by giving them entry to an exterior data database to generate factually correct outcomes.
The article additionally showcases how vector databases can allow speedy prototyping of GenAI functions. Other than a simple setup, vector databases can assist builders in the event that they deal with vectorization of information routinely at import and question time, allow higher search not solely with vector search however along with keyword-based searches, and seamlessly combine with different parts of the know-how stack. Moreover, the article discusses how vector databases can help enterprises in shifting these prototypes to manufacturing by addressing issues of scalability, deployment, and knowledge safety.
In case you are fascinated with utilizing an open-source vector database in your GenAI software, head over to Weaviate’s Quickstart Information and take a look at it out your self.

{kind=link}