
Regardless that I’m from India and my mom tongue is Bengali, and I communicate, learn, and write each Hindi and Bengali virtually in addition to English, in my profession with Pure Language Processing (NLP) I’ve labored completely with English. That is most likely not that unusual, as a result of till not too long ago, English was the language the place most NLP work occurred, and to a lesser extent a few of the main European languages (Spanish, French, German, Russian, and so forth.). Fortuitously or sadly, amongst these languages, English was the one one I knew nicely sufficient to work with.
As NLP work with European languages turned extra widespread, I secretly envied my European colleagues for being multilingual within the “proper” languages. The rise of CJK (Chinese language, Japanese, Korean) that adopted (and its impression on NLP in CJK languages) largely handed me by as nicely, since I didn’t know any of those languages both. These days, nevertheless, I’ve been inspired by the rise of NLP with Indic languages (languages spoken in India), not the least as a result of it has given me hope that I’ll lastly be capable of put my multilingual abilities to some use in any case :-).
Indic languages have largely been thought of low-resource languages, as a result of there was not sufficient materials in digital format to coach NLP fashions, regardless of most of them individually having a reasonably wealthy and advanced literature. This has modified (or least been alleviated to a big extent) with the rise of the Web and social media, and Indian folks rediscovering their roots and starting to speak of their native languages. Software program infrastructure to assist this, corresponding to Avro keyboard has additionally helped, making it simpler to start out speaking electronically utilizing non-English languages.
In any case, I noticed this tweet inviting those that spoke Bengali to a decentralized coaching experiment organized by Neuropark, Hugging Face, and Yandex Analysis to coach an ALBERT mannequin for Bengali. Individuals wanted entry to Colab and an Web connection. I used to be curious in regards to the distributed coaching half, and since I glad the conditions, I made a decision to hitch within the experiment. That was per week and a half in the past, coaching completed at present (Friday). On this publish, I’ll describe what I realized from the expertise.
The target was to coach an ALBERT-large mannequin from scratch on the Bengali language. The ALBERT transformer mannequin was proposed within the paper ALBERT: A lite BERT for Self-Supervised Studying of Language Representations in 2019 by Lan et al. It’s based mostly on the BERT transformer mannequin, however has fewer parameters and higher efficiency on many benchmark duties. The steps concerned within the coaching are as follows.
- Bengali tokenizer coaching.
- ALBERT Bengali Language Mannequin (LM) coaching.
- Mannequin analysis, each subjective and utilizing downstream job
Tokenizer Coaching
The tokenizer was skilled on the the Bengali subset of the multilingual OSCAR dataset. Textual content was normalized utilizing the next normalizer pipeline: NMT, which converts varied whitespace breaks between phrases to a easy area; NFKC, which does some unicode magic (see beneath) that unifies the best way characters are encoded; lowercase, which does not have an effect on Bengali as a lot as a result of it does not have case, however does assist with embedded English textual content, and varied regexes, together with one to remodel a sequence of areas to a single area. The Unigram Language Mannequin algorithm (see Subword Regularization: Enhancing Neural Community Translation Fashions with A number of Subword Candidates (Kudo, 2018)) wqs used for tokenization.
The open supply Bengali NLP library BNLP was used for sentence segmentation within the mannequin coaching step (see beneath). The crew additionally tried out BLTK, one other Bengali NLP library, however lastly went with BNLP after testing outcomes from each.
A earlier model of the tokenizer was skilled utilizing knowledge scraped from varied Bengali language web sites through the Bakya challenge and used Byte Pair Encoding (BPE), however this was not used within the closing coaching. In my unique publish, I had mistakenly assumed that this was the tokenizer that was getting used for the coaching.
The work round normalization occurred earlier than I joined the challenge, however I used to be round when there was a request to test the standard of sentences tokenized utilizing BNLP versus BLTK. It was then that I spotted that the crew really wanted Bengali readers fairly than audio system, and (mistakenly no less than in my case) assumed that the latter routinely implies the previous. Having grown up exterior Bengal, I realized Hindi in school as a second language, so whereas I can learn Bengali (having learnt it at dwelling), I’m not that fluent in it as I’m at Hindi.
I additionally realized one other attention-grabbing factor about Unicode character illustration for Bengali (and possibly different Indic languages), which might be associated to the Unicode magic round NFKC, that I wish to share right here. In English, the 26 letters of the alphabet are mixed in several methods to type phrases. Within the Bengali alphabet (as in Hindi and presumably different Indic languages derived from Sanskrit), there are 7 consonant teams of 5 characters every. Every group emits a sound that makes use of a selected part of your vocal equipment (lips, tongue and roof of palate, throat, and so forth), and the sound will get softer as you step throughout the group. There are additionally 14 vowel characters which might be used to switch the consonant sounds to type phrases. Not like English, the vowels are overlaid on the consonants on the similar character place. As well as, pairs of consonants might be conjoined to type new characters representing a transitional sound — that is known as যুক্তাক্ষর (pronounced juktakkhor) or conjoined phrase.
Anyway, it seems that Unicode elegantly handles each the overlaying of vowels on to consonants in addition to combining two consonants to type a 3rd, as the next code snippet illustrates (most likely extra readily obvious to Bengali readers, others might want to squint a bit on the output to get it).

Mannequin Coaching
The mannequin was skilled on textual content from Bengali Wikipedia and the Bengali portion of the OSACAR dataset mixed. The mannequin being skilled was the AlbertForPreTraining mannequin from Hugging Face. ALBERT makes use of two pre-training goals. The primary is Masked Language Modeling (MLM) just like BERT, the place we masks out 15% of the tokens and have the mannequin be taught to foretell them. The second is Sentence Order Prediction (SOP) which in case of BERT tries to foretell if one sentence follows one other, however in case of ALBERT makes use of textual content segments as an alternative of sentences, and is considered extra environment friendly in comparison with BERT SOP.
Coaching was accomplished in a distributed method utilizing the Hivemind challenge from Yandex Analysis. This challenge permits a central crew to construct the coaching script and have volunteer members on the Web (corresponding to myself) run it on a subset of the info, utilizing free GPU-enabled Colab and Kaggle notebooks. I consider Hivemind may distribute the coaching throughout hybrid non-cloud GPU cases and non-free cloud cases as nicely, however these weren’t used right here. As soon as began, the coaching script on a selected Colab or Kaggle pocket book will proceed till the consumer stops it or the platform decides to time them out, both through coverage (Kaggle permits most 9 hours steady GPU use) or attributable to inactivity. The coaching scripts might be discovered within the github repository mryab/collaborative-training.
Volunteers have to opt-in to the coaching by including themselves to an allow-list (requesting through the Discord channel) and signing up for a Hugging Face account. When beginning up their occasion, they authenticate themselves through their Hugging Face username and password. Every pocket book capabilities as a peer within the decentralized coaching setup, coaching the mannequin domestically and creating native updates in opposition to the mannequin, and logging its progress utilizing the Weights and Biases (wandb) API. On the finish of every coaching step, notebooks throughout the peer group share mannequin parameters (mannequin averaging) with one another utilizing a course of known as butterfly all-reduce. After every profitable coaching spherical, the friends shuffle round and discover new teams to hitch. This ensures that the native updates are propagated to all of the friends over time. If a peer leaves the group, this impacts solely the quick peer group, the remaining members of which will likely be re-assembled into different working peer teams.
For a extra technical protection of the distributed coaching algorithm, please seek advice from Moshpit SGD: Communication-Environment friendly Decentralized Coaching on Heterogeneous Unreliable Units (Ryabinin et al, 2021) and its predecessor In direction of Crowdsourced Coaching of Massive Neural Networks utilizing decentralized Combination-of-Specialists (Ryabinin and Gusev, 2020).
On the level when coaching began, the mannequin was reporting a lack of round 11, which got here right down to beneath 2 after one week and over 20,000 coaching steps, as proven within the loss curve on the left beneath. The alive friends on the proper exhibits the variety of simultaneous coaching cases over the week. At its peak there have been round 50, which oscillated between 20 and 40 over the course of the coaching. The gradual decline in direction of the tip of the coaching could possibly be no less than partially attributed to volunteers working out of Kaggle quotas (30 GPU hours per week) and being punished by Colab for hogging CPU assets.

Mannequin Analysis
In fact, for a language mannequin corresponding to Bengali ALBERT, a greater metric than the loss lowering from 11 to 1.97, is how nicely it does on some downstream job. Because the mannequin skilled, its checkpoints have been subjected to 2 types of analysis.
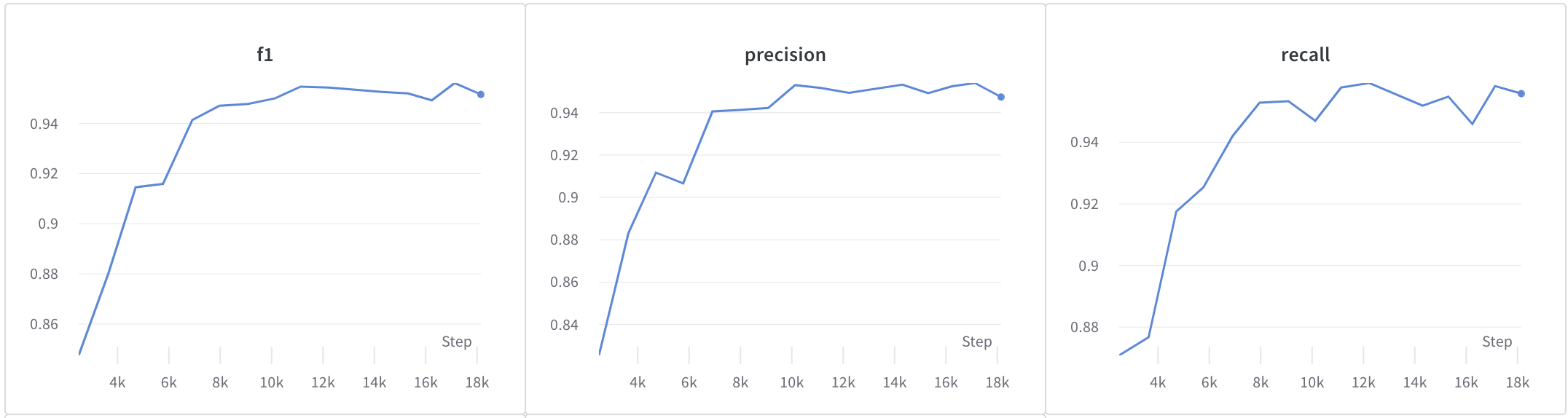
First, the mannequin was fine-tuned for an NER job (WikiNER) utilizing the Bengali subset of the multi-lingual Wiki-ANN dataset, a dataset annotated with LOC (location), PER (particular person), and ORG (group) tags in IOB format. The charts beneath the Precision, Recall, and F1 values by mannequin checkpoints over the course of the coaching. The ultimate scores have been 97.5% accuracy, 95.6% F1, 95.4% Precision, and 95.8% Recall.
As well as, mannequin checkpoints have been used to check the mannequin’s functionality to foretell masked phrases in supplied sentences. This analysis was extra subjective in nature, manually wanting on the high 5 masked phrase predictions for given sentences and testing their relevance, nevertheless it was noticed that the ultimate mannequin made virtually good masked phrase predictions, in comparison with earlier checkpoints with extra variable conduct.
Conclusion
This expertise has been of immense academic worth for me. I received to make use of and see a distributed coaching setting shut up, and received to work together with a variety of very sensible and dedicated builders and researchers and fellow volunteers who I cannot record by identify, as a result of I’m positive I’ll overlook somebody. I additionally received to see a variety of code that I’m positive I’ll use for inspiration later. For instance, I’m additionally a bit embarrassed to say that this was my first expertise utilizing the Weights and Biases (wandb) API, however I favored what I noticed, so I plan to make use of it sooner or later.
As well as, the progress that has been made in Bengali NLP (and different Indic languages) was an actual eye opener for me. Actually, the present mannequin is just not even the primary transformer based mostly mannequin for Bengali, there may be already a multi-language IndicBERT which has proven promising outcomes on some duties. Nevertheless, that is the primary transformer based mostly mannequin for Bengali that was skilled in a distributed method.
The mannequin (tentatively known as SahajBERT) and tokenizer will shortly be out there for obtain on Hugging Face. I’ll present the hyperlinks to them as they develop into out there.
Lastly, many because of Nilavya Das, Max Ryabinin, Tanmoy Sarkar, and Lucile Saulnier for his or her beneficial feedback and for fact-checking the draft model of this publish.
Updates (2021-05-24)
- Up to date description of tokenizer coaching course of.
- Added hyperlinks to papers that present extra details about the distributed coaching method.
Replace (2021-06-01) — The skilled tokenizer and mannequin described above has been revealed and is now out there for obtain at neuropark/sahajBERT on the Huggingface fashions web site.

{kind=link}