
The demand for prime volumes of information has elevated the necessity for databases that may deal with each knowledge ingestion and querying with the bottom potential latency (aka excessive efficiency). To satisfy this demand, database designs have shifted to prioritize minimal work throughout ingestion and querying, with different duties being carried out within the background as post-ingestion and pre-query.
This text will describe these duties and find out how to run them in a totally completely different server to keep away from sharing sources (CPU and reminiscence) with servers that deal with knowledge loading and studying.
Duties of post-ingestion and pre-query
The duties that may proceed after the completion of information ingestion and earlier than the beginning of information studying will differ relying on the design and options of a database. On this publish, we describe the three most typical of those duties: knowledge file merging, delete utility, and knowledge deduplication.
Information file merging
Question efficiency is a vital objective of most databases, and good question efficiency requires knowledge to be nicely organized, resembling sorted and encoded (aka compressed) or listed. As a result of question processing can deal with encoded knowledge with out decoding it, and the much less I/O a question must learn the sooner it runs, encoding a considerable amount of knowledge into just a few massive recordsdata is clearly useful. In a standard database, the method that organizes knowledge into massive recordsdata is carried out throughout load time by merging ingesting knowledge with present knowledge. Sorting and encoding or indexing are additionally wanted throughout this knowledge group. Therefore, for the remainder of this text, we’ll focus on the kind, encode, and index operations hand in hand with the file merge operation.
Quick ingestion has turn into an increasing number of vital to dealing with massive and steady flows of incoming knowledge and close to real-time queries. To help quick efficiency for each knowledge ingesting and querying, newly ingested knowledge isn’t merged with the present knowledge at load time however saved in a small file (or small chunk in reminiscence within the case of a database that solely helps in-memory knowledge). The file merge is carried out within the background as a post-ingestion and pre-query process.
A variation of LSM tree (log-structured merge-tree) approach is normally used to merge them. With this system, the small file that shops the newly ingested knowledge ought to be organized (e.g. sorted and encoded) the identical as different present knowledge recordsdata, however as a result of it’s a small set of information, the method to type and encode that file is trivial. The explanation to have all recordsdata organized the identical will probably be defined within the part on knowledge compaction under.
Discuss with this article on knowledge partitioning for examples of data-merging advantages.
Delete utility
Equally, the method of information deletion and replace wants the information to be reorganized and takes time, particularly for giant historic datasets. To keep away from this value, knowledge isn’t really deleted when a delete is issued however a tombstone is added into the system to ‘mark’ the information as ‘delicate deleted’. The precise delete is known as ‘onerous delete’ and will probably be accomplished within the background.
Updating knowledge is commonly applied as a delete adopted by an insert, and therefore, its course of and background duties would be the ones of the information ingestion and deletion.
Information deduplication
Time sequence databases resembling InfluxDB settle for ingesting the identical knowledge greater than as soon as however then apply deduplication to return non-duplicate outcomes. Particular examples of deduplication functions may be present in this text on deduplication. Like the method of information file merging and deletion, the deduplication might want to reorganize knowledge and thus is a perfect process for performing within the background.
Information compaction
The background duties of post-ingestion and pre-query are generally often called knowledge compaction as a result of the output of those duties usually incorporates much less knowledge and is extra compressed. Strictly talking, the “compaction” is a background loop that finds the information appropriate for compaction after which compacts it. Nevertheless, as a result of there are a lot of associated duties as described above, and since these duties normally contact the identical knowledge set, the compaction course of performs all of those duties in the identical question plan. This question plan scans knowledge, finds rows to delete and deduplicate, after which encodes and indexes them as wanted.
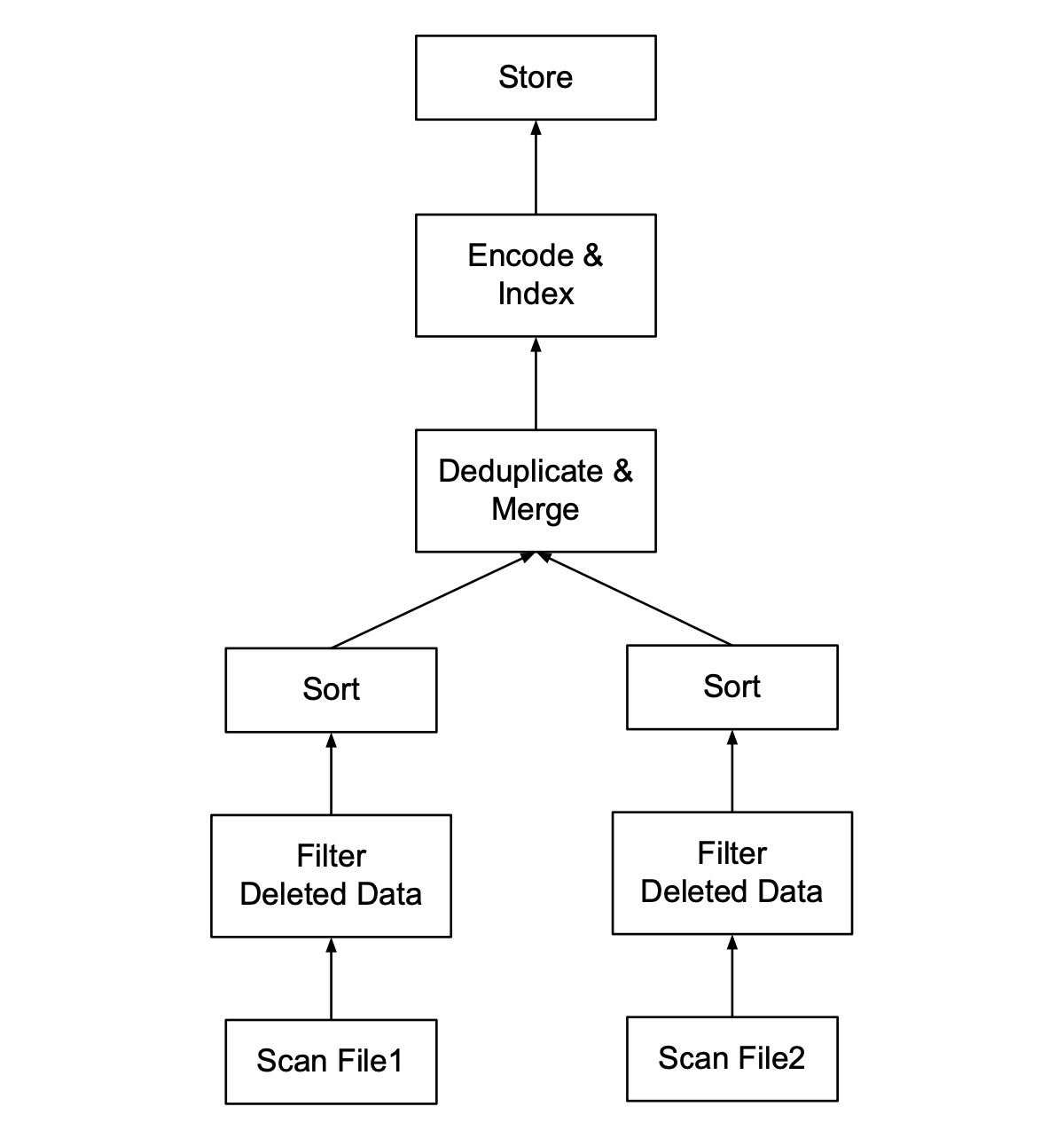
Determine 1 reveals a question plan that compacts two recordsdata. A question plan within the database is normally executed in a streaming/pipelining style from the underside up, and every field within the determine represents an execution operator. First, knowledge of every file is scanned concurrently. Then tombstones are utilized to filter deleted knowledge. Subsequent, the information is sorted on the first key (aka deduplication key), producing a set of columns earlier than going via the deduplication step that applies a merge algorithm to eradicate duplicates on the first key. The output is then encoded and listed if wanted and saved again in a single compacted file. When the compacted knowledge is saved, the metadata of File 1 and File 2 saved within the database catalog may be up to date to level to the newly compacted knowledge file after which File 1 and File 2 may be safely eliminated. The duty to take away recordsdata after they’re compacted is normally carried out by the database’s rubbish collector, which is past the scope of this text.
 InfluxData
InfluxDataDetermine 1: The method of compacting two recordsdata.
Although the compaction plan in Determine 1 combines all three duties in a single scan of the information and avoids studying the identical set of information thrice, the plan operators resembling filter and type are nonetheless not low-cost. Allow us to see whether or not we are able to keep away from or optimize these operators additional.
Optimized compaction plan
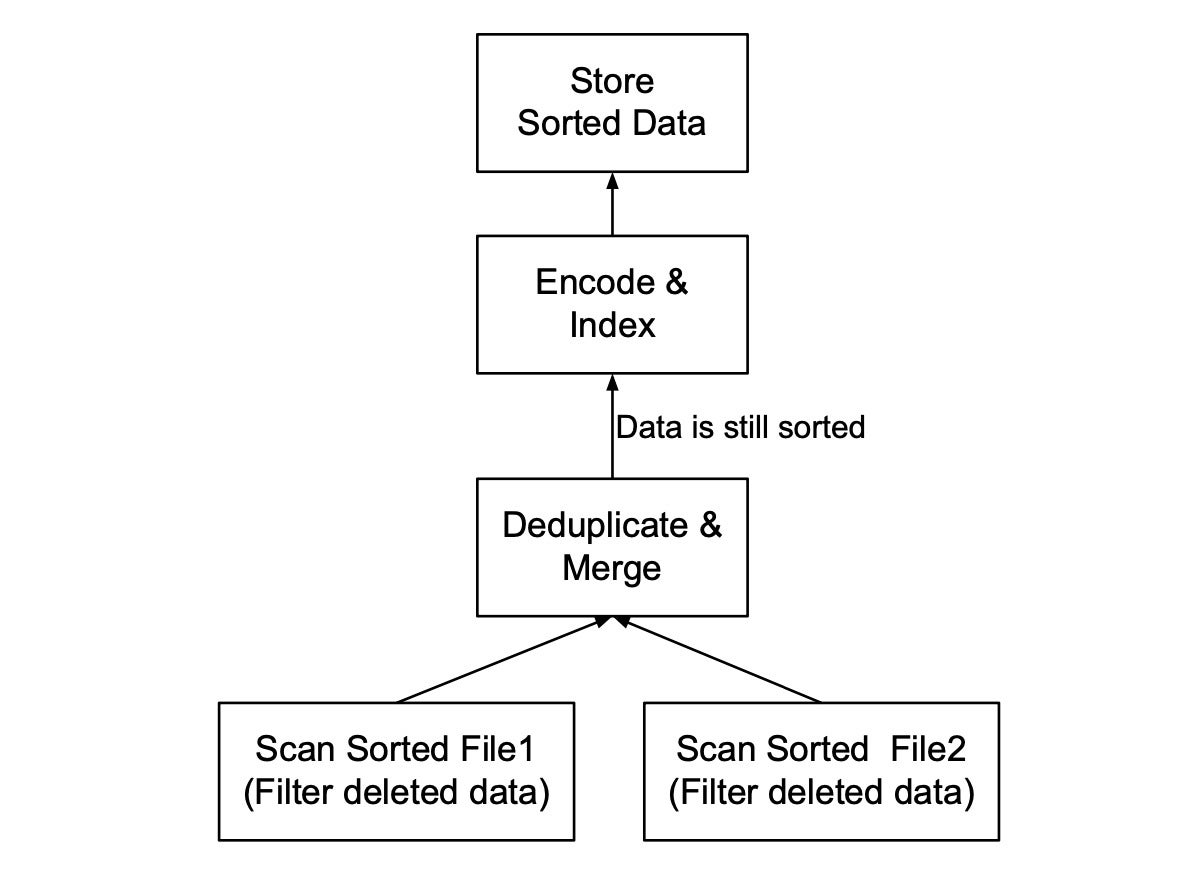
Determine 2 reveals the optimized model of the plan in Determine 1. There are two main modifications:
- The operator Filter Deleted Information is pushed into the Scan operator. That is an efficient predicate-push-down strategy to filter knowledge whereas scanning.
- We not want the Kind operator as a result of the enter knowledge recordsdata are already sorted on the first key throughout knowledge ingestion. The Deduplicate & Merge operator is applied to maintain its output knowledge sorted on the identical key as its inputs. Thus, the compacting knowledge can also be sorted on the first key for future compaction if wanted.
 InfluxData
InfluxDataDetermine 2: Optimized means of compacting two sorted recordsdata.
Be aware that, if the 2 enter recordsdata include knowledge of various columns, which is frequent in some databases resembling InfluxDB, we might want to hold their type order suitable to keep away from doing a re-sort. For instance, let’s say the first key incorporates columns a, b, c, d, however File 1 consists of solely columns a, c, d (in addition to different columns that aren’t part of the first key) and is sorted on a, c, d. If the information of File 2 is ingested after File 1 and consists of columns a, b, c, d, then its type order have to be suitable with File 1’s type order a, c, d. This implies column b may very well be positioned wherever within the type order, however c have to be positioned after a and d have to be positioned after c. For implementation consistency, the brand new column, b, may all the time be added because the final column within the type order. Thus the kind order of File 2 could be a, c, d, b.
One more reason to maintain the information sorted is that, in a column-stored format resembling Parquet and ORC, encoding works nicely with sorted knowledge. For the frequent RLE encoding, the decrease the cardinality (i.e., the decrease the variety of distinct values), the higher the encoding. Therefore, placing the lower-cardinality columns first within the type order of the first key won’t solely assist compress knowledge extra on disk however extra importantly assist the question plan to execute sooner. It is because the information is stored encoded throughout execution, as described in this paper on materialization methods.
Compaction ranges
To keep away from the costly deduplication operation, we need to handle the information recordsdata in a approach that we all know whether or not they probably share duplicate knowledge with different recordsdata or not. This may be accomplished by utilizing the approach of information overlapping. To simplify the examples of the remainder of this text, we’ll assume that the information units are time sequence during which knowledge overlapping implies that their knowledge overlap on time. Nevertheless, the overlap approach may very well be outlined on non-time sequence knowledge, too.
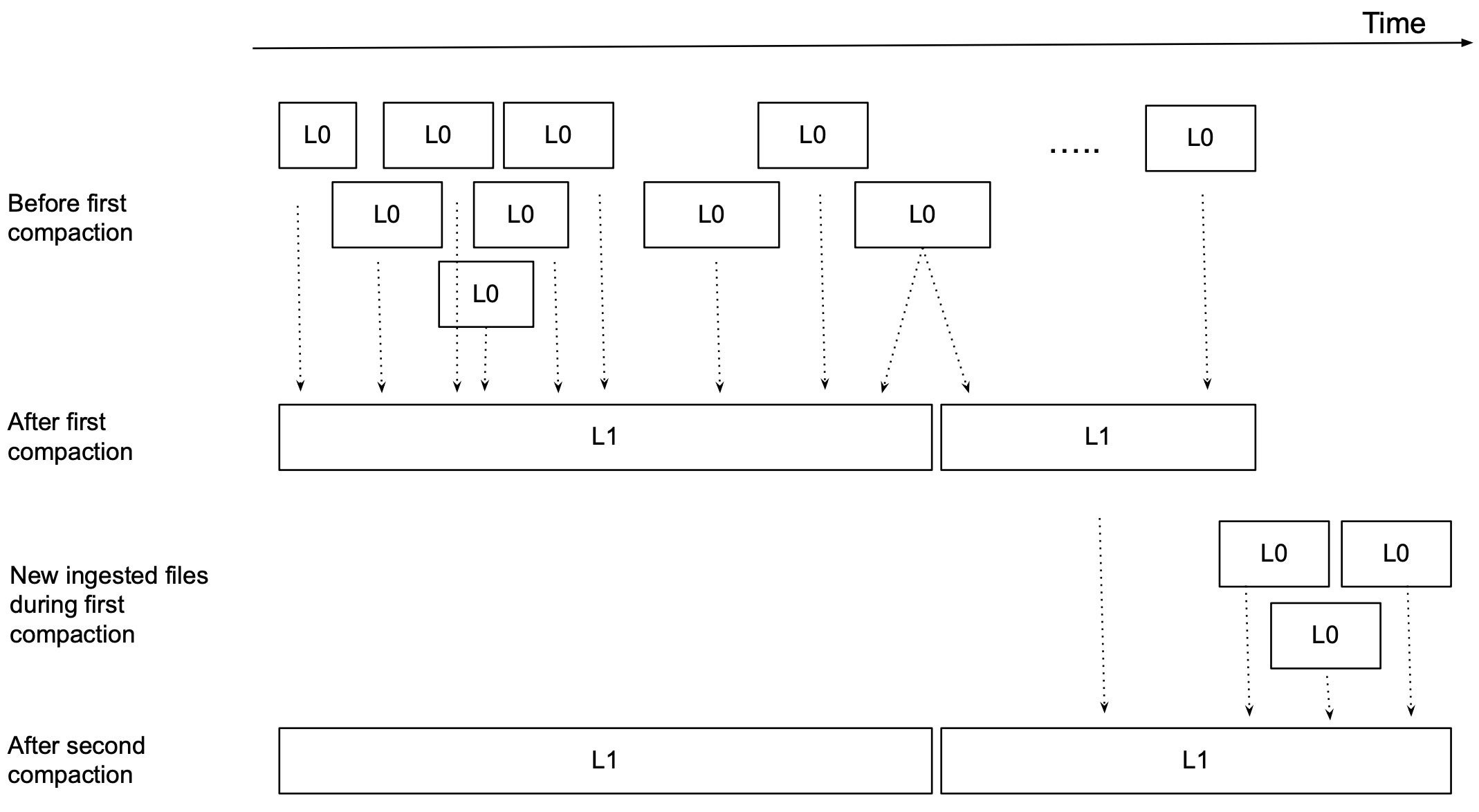
One of many methods to keep away from recompacting well-compacted recordsdata is to outline ranges for the recordsdata. Degree 0 represents newly ingested small recordsdata and Degree 1 represents compacted, non-overlapping recordsdata. Determine 3 reveals an instance of recordsdata and their ranges earlier than and after the primary and second rounds of compaction. Earlier than any compaction, the entire recordsdata are Degree 0 and so they probably overlap in time in arbitrary methods. After the primary compaction, many small Degree 0 recordsdata have been compacted into two massive, non-overlapped Degree 1 recordsdata. Within the meantime (bear in mind this can be a background course of), extra small Degree 0 recordsdata have been loaded in, and these kick-start a second spherical of compaction that compacts the newly ingested Degree 0 recordsdata into the second Degree 1 file. Given our technique to hold Degree 1 recordsdata all the time non-overlapped, we don’t must recompact Degree 1 recordsdata if they don’t overlap with any newly ingested Degree 0 recordsdata.
 InfluxData
InfluxDataDetermine 3: Ingested and compacted recordsdata after two rounds of compaction.
If we need to add completely different ranges of file measurement, extra compaction ranges (2, 3, 4, and many others.) may very well be added. Be aware that, whereas recordsdata of various ranges might overlap, no recordsdata ought to overlap with different recordsdata in the identical stage.
We must always attempt to keep away from deduplication as a lot as potential, as a result of the deduplication operator is pricey. Deduplication is particularly costly when the first key consists of many columns that must be stored sorted. Constructing quick and reminiscence environment friendly multi-column kinds is critically necessary. Some frequent strategies to take action are described right here and right here.
Information querying
The system that helps knowledge compaction must know find out how to deal with a mix of compacted and not-yet-compacted knowledge. Determine 4 illustrates three recordsdata {that a} question must learn. File 1 and File 2 are Degree 1 recordsdata. File 3 is a Degree 0 file that overlaps with File 2.
 InfluxData
InfluxDataDetermine 4: Three recordsdata {that a} question must learn.
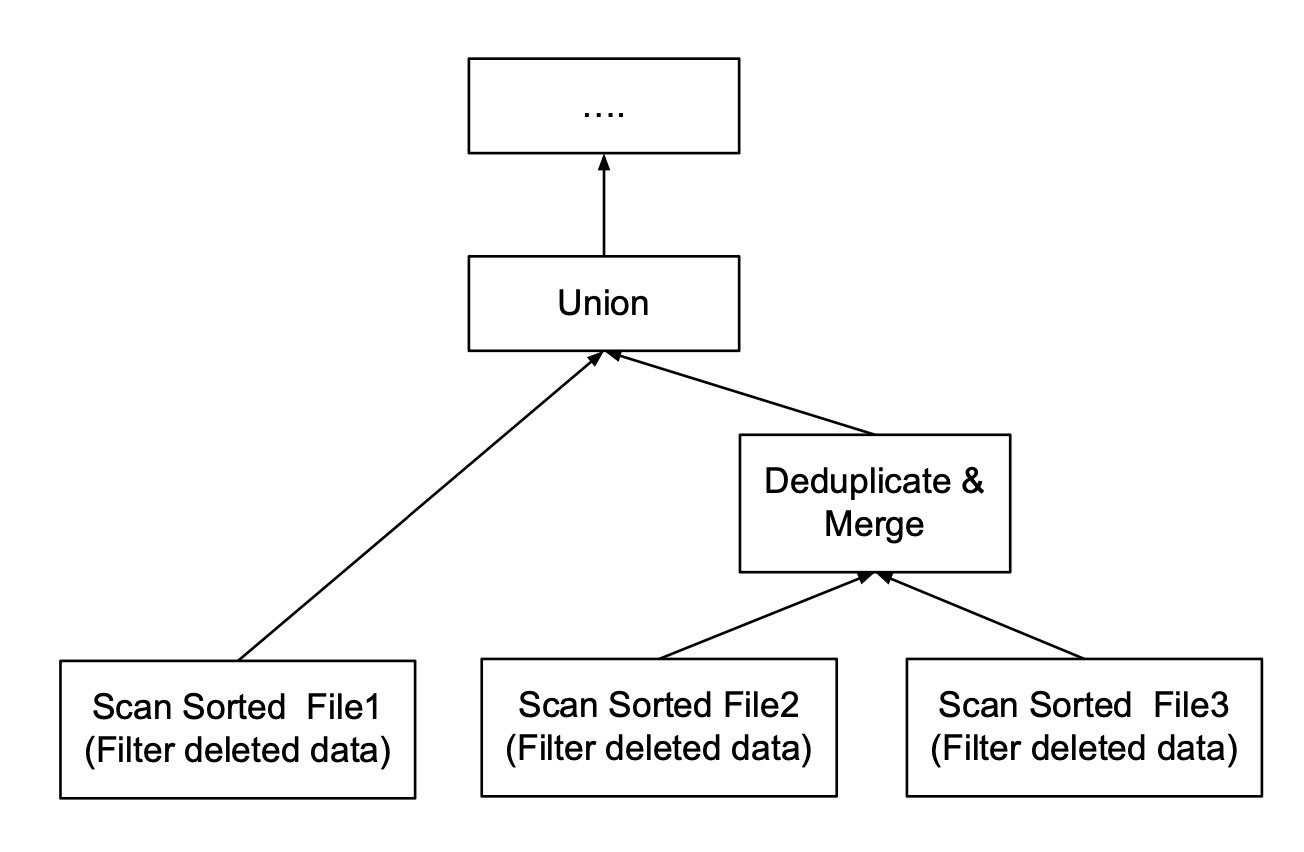
Determine 5 illustrates a question plan that scans these three recordsdata. As a result of File 2 and File 3 overlap, they should undergo the Deduplicate & Merge operator. File 1 doesn’t overlap with any file and solely must be unioned with the output of the deduplication. Then all unioned knowledge will undergo the same old operators that the question plan has to course of. As we are able to see, the extra compacted and non-overlapped recordsdata may be produced throughout compaction as pre-query processing, the much less deduplication work the question has to carry out.
 InfluxData
InfluxDataDetermine 5: Question plan that reads two overlapped recordsdata and one non-overlapped one.
Remoted and hidden compactors
Since knowledge compaction consists of solely post-ingestion and pre-query background duties, we are able to carry out them utilizing a totally hidden and remoted server known as a compactor. Extra particularly, knowledge ingestion, queries, and compaction may be processed utilizing three respective units of servers: integers, queriers, and compactors that don’t share sources in any respect. They solely want to hook up with the identical catalog and storage (usually cloud-based object storage), and comply with the identical protocol to learn, write, and arrange knowledge.
As a result of a compactor doesn’t share sources with different database servers, it may be applied to deal with compacting many tables (and even many partitions of a desk) concurrently. As well as, if there are a lot of tables and knowledge recordsdata to compact, a number of compactors may be provisioned to independently compact these completely different tables or partitions in parallel.
Moreover, if compaction requires considerably much less sources than ingestion or querying, then the separation of servers will enhance the effectivity of the system. That’s, the system may draw on many ingestors and queriers to deal with massive ingesting workloads and queries in parallel respectively, whereas solely needing one compactor to deal with the entire background post-ingestion and pre-querying work. Equally, if the compaction wants much more sources, a system of many compactors, one ingestor, and one querier may very well be provisioned to satisfy the demand.
A well known problem in databases is find out how to handle the sources of their servers—the ingestors, queriers, and compactors—to maximise their utilization of sources (CPU and reminiscence) whereas by no means hitting out-of-memory incidents. It’s a massive subject and deserves its personal weblog publish.
Compaction is a vital background process that permits low latency for knowledge ingestion and excessive efficiency for queries. The usage of shared, cloud-based object storage has allowed database methods to leverage a number of servers to deal with knowledge ingestion, querying, and compacting workloads independently. For extra details about the implementation of such a system, try InfluxDB IOx. Different associated strategies wanted to design the system may be present in our companion articles on sharding and partitioning.

{kind=link}