
Intel® Choose Options for Splunk and Kafka on Kubernetes use containers and S3-compliant storage to extend utility efficiency and infrastructure utilization whereas simplifying the administration of hybrid cloud environments.
Govt Abstract
Knowledge architects and directors of recent analytic and streaming platforms like Splunk and Kafka regularly search for methods to simplify the administration of hybrid or multi-cloud platforms, whereas additionally scaling these platforms to fulfill the wants of their organizations. They’re challenged with rising knowledge volumes and the necessity for quicker insights and responses. Sadly, scaling usually ends in server sprawl, underutilized infrastructure sources and operational inefficiencies.
The discharge of Splunk Operator for Kubernetes and Confluent for Kubernetes, mixed with Splunk SmartStore and Confluent Tiered Storage, presents new choices for architectures designed with containers and S3-compatible storage. These new cloud-native applied sciences, operating on Intel structure and Pure Storage FlashBlade, may also help enhance utility efficiency, improve infrastructure utilization and simplify the administration of hybrid and multi-cloud environments.
Intel and Pure Storage architects designed a brand new reference structure known as Intel® Choose Options for Splunk and Kafka on Kubernetes and carried out a proof of idea(PoC) to check the worth of this reference structure. Exams had been run utilizing Splunk Operator for Kubernetes and Confluent for Kubernetes with Intel IT’s high-cardinality manufacturing knowledge to reveal a real-world state of affairs.
In our PoC, a nine-node cluster reached a Splunk ingest price of 886 MBps, whereas concurrently finishing 400 profitable dense Splunk searches per minute, with an total CPU utilization price of 58%.1 We additionally examined Splunk super-sparse searches and Splunk ingest from Kafka knowledge saved domestically versus knowledge in Confluent Tiered Storage on FlashBlade, which exhibited outstanding outcomes. The outcomes of this PoC knowledgeable the Intel Choose Options for Splunk and Kafka on Kubernetes.
Preserve studying to learn how to construct an identical Splunk and Kafka platform that may present the efficiency and useful resource utilization your group must meet the calls for of at present’s data-intensive workloads.
 Intel
IntelResolution Transient
Enterprise problem
The continued digital transformation of just about each business implies that trendy enterprise workloads make the most of large quantities of structured and unstructured knowledge. For functions like Splunk and Kafka, the explosion of information could be compounded by different points. First, the conventional distributed scale-out mannequin with direct-attached storage requires a number of copies of information to be saved, driving up storage wants even additional. Second, many organizations are retaining their knowledge for longer intervals of time for safety and/or compliance causes. These tendencies create many challenges, together with:
- Server sprawl. The distributed scale-out mannequin, the place knowledge resides totally in native storage on the compute node, is not sensible and causes organizations so as to add each compute and storage sources when solely storage is required. It additionally drives up infrastructure and upkeep prices.
- Beneath-utilized sources. Including compute sources simply to get extra storage ends in CPU under-utilization, lowering the return on funding in infrastructure.
- Operational inefficiency. Regularly including severs to a Splunk or Kafka cluster ends in ongoing upkeep, together with knowledge rebalance, storage upgrades, firmware patches and different operational duties.
Past the challenges offered by legacy architectures, organizations usually produce other challenges. Giant organizations usually have Splunk and Kaka platforms in each on-prem and multi-cloud environments. Managing the variations between these environments creates complexity for Splunk and Kafka directors, architects and engineers.
Worth of Intel® Choose Options for Splunk and Kafka on Kubernetes
Many organizations perceive the worth of Kubernetes, which presents portability and suppleness and works with nearly any sort of container runtime. It has change into the usual throughout organizations for operating cloud-native functions; 69% of respondents from a latest Cloud-Native Computing Basis (CNCF) survey reported utilizing Kubernetes in manufacturing.2 To assist their clients’ want to deploy Kubernetes, Confluent developed Confluent for Kubernetes, and Splunk led the event of Splunk Operator for Kubernetes.
As well as, Splunk and Confluent have developed new storage capabilities: Splunk SmartStore and Confluent Tiered Storage, respectively. These capabilities use S3‑compliant object storage to scale back the price of large knowledge units. As well as, organizations can maximize knowledge availability by putting knowledge in centralized S3 object storage, whereas decreasing utility storage necessities by storing a single copy of information that was moved to S3, counting on the S3 platform for knowledge resiliency.
The cloud-native applied sciences underlying this reference structure allow techniques to shortly course of the massive quantities of knowledge at present’s workloads demand; enhance useful resource utilization and operational effectivity; and assist simplify the deployment and administration of Splunk and Kafka containers.
 Intel
IntelResolution structure highlights
We designed our reference structure to make the most of the beforehand talked about new Splunk and Kafka merchandise and applied sciences. We ran exams with a proof of idea (PoC) designed to evaluate Kafka and Splunk efficiency operating on Kubernetes with servers based mostly on high-performance Intel structure and S3-compliant storage supported by Pure Storage FlashBlade.
Determine 1 illustrates the answer structure at a excessive degree. The essential software program and {hardware} merchandise and applied sciences included on this reference structure are listed under:
- Splunk Enterprise with Splunk SmartStore
- Splunk Operator for Kubernetes
- Confluent Platform with Confluent Tiered Storage
- Confluent for Kubernetes
- S3-compliant Pure Storage FlashBlade
- 9 servers with:
- third Era Intel® Xeon® Scalable processors
- Intel® Optane™ P5800X SSDs
- Community structure with Intel® Ethernet Adapters (see “Community Topology” and “FlashBlade Configuration Particulars” for extra particulars about community setup)
Further details about a few of these parts is supplied within the “A Nearer Have a look at Intel® Choose Options for Splunk and Kafka on Kubernetes” part that follows.
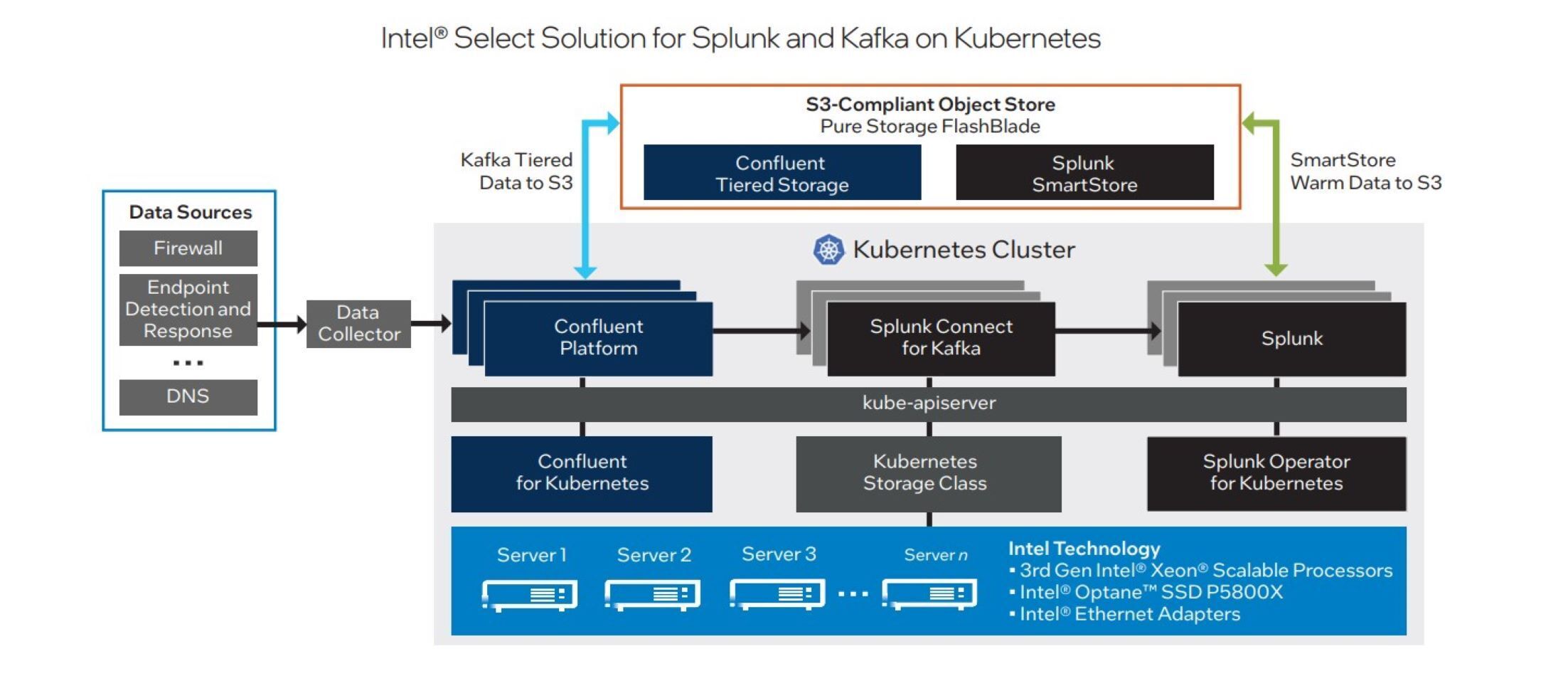 Intel
IntelDetermine 1. The answer reference structure makes use of high-performance {hardware} and cloud-native software program to assist improve efficiency and enhance {hardware} utilization and operational effectivity.
A Nearer Have a look at Intel® Choose Options for Splunk and Kafka on Kubernetes
The power to run Splunk and Kafka on the identical Kubernetes cluster linked to S3-compliant flash storage unleashes seamless scalability with a unprecedented quantity of efficiency and useful resource utilization effectivity. The next sections describe among the software program improvements that make this potential.
Confluent for Kubernetes and Confluent Tiered Storage
Confluent for Kubernetes supplies a cloud-native, infrastructure-as-code strategy to deploying Kafka on Kubernetes. It goes past the open-source model of Kubernetes to supply an entire, declarative API to construct a personal cloud Kafka service. It automates the deployment of Confluent Platform and makes use of Kubernetes to reinforce the platform’s elasticity, ease of operations and resiliency for enterprises working at any scale.
Confluent Tiered Storage structure augments Kafka brokers with the S3 object retailer by way of FlashBlade, storing knowledge on the FlashBlade as a substitute of the native storage. Subsequently, Kafka brokers comprise considerably much less state domestically, making them extra light-weight and rebalancing operations orders of magnitude quicker. Tiered Storage simplifies the operation and scaling of the Kafka cluster and permits the cluster to scale effectively to petabytes of information. With FlashBlade because the backend, Tiered Storage has the efficiency to make all Kafka knowledge accessible for each streaming shoppers and historic queries.
Splunk Operator for Kubernetes and Splunk SmartStore
The Splunk Operator for Kubernetes simplifies the deployment of Splunk Enterprise in a cloud-native surroundings that makes use of containers. The Operator simplifies the scaling and administration of Splunk Enterprise by automating administrative workflows utilizing Kubernetes greatest practices.
Splunk SmartStore is an indexer functionality that gives a approach to make use of distant object shops to retailer listed knowledge. SmartStore makes it simpler for organizations to retain knowledge for an extended time frame. Utilizing FlashBlade because the high-performance distant object retailer, SmartStore holds the one grasp copy of the nice and cozy/chilly knowledge. On the similar time, a cache supervisor on the indexer maintains the not too long ago accessed knowledge. The cache supervisor manages knowledge motion between the indexer and the distant storage tier. The info availability and constancy capabilities are offloaded to FlashBlade, which presents N+2 redundancy.4
Distant Object Storage Capabilities
Pure Storage FlashBlade is a scale-out, all-flash file and object storage system that’s designed to consolidate full knowledge silos whereas accelerating real-time insights from machine knowledge utilizing functions reminiscent of Splunk and Kafka. FlashBlade’s skill to scale efficiency and capability is predicated on 5 key improvements:
- An all-flash structure with built-in non-volatile random-access reminiscence (NVRAM).
- A unified community that helps IPv4 and IPv6 shopper entry over Ethernet hyperlinks as much as 100 Gb/s.
- Purity//FB storage working system minimizes workload balancing issues by distributing all shopper operation requests evenly amongst blades.
- A typical media architectural design for information and objects helps concurrent entry to information utilizing a wide range of protocols reminiscent of NFSv3, NFS over HTTP and SMB and objects by way of S3.
- Ease of use enabled by autonomously performing routine administrative duties, self-tuning and offering system alerts when parts fail.
A whole FlashBlade system configuration consists of as much as 10 self-contained rack-mounted servers. A single 4U chassis FlashBlade can host as much as 15 blades and a full FlashBlade system configuration can scale as much as 10 chassis (150 blades), probably representing years of information for even increased ingest techniques. Every blade meeting is a self‑contained compute module outfitted with processors, communication interfaces and both 17 TB or 52 TB of flash reminiscence for persistent knowledge storage. Determine 2 exhibits how the reference structure makes use of Splunk SmartStore and FlashBlade.
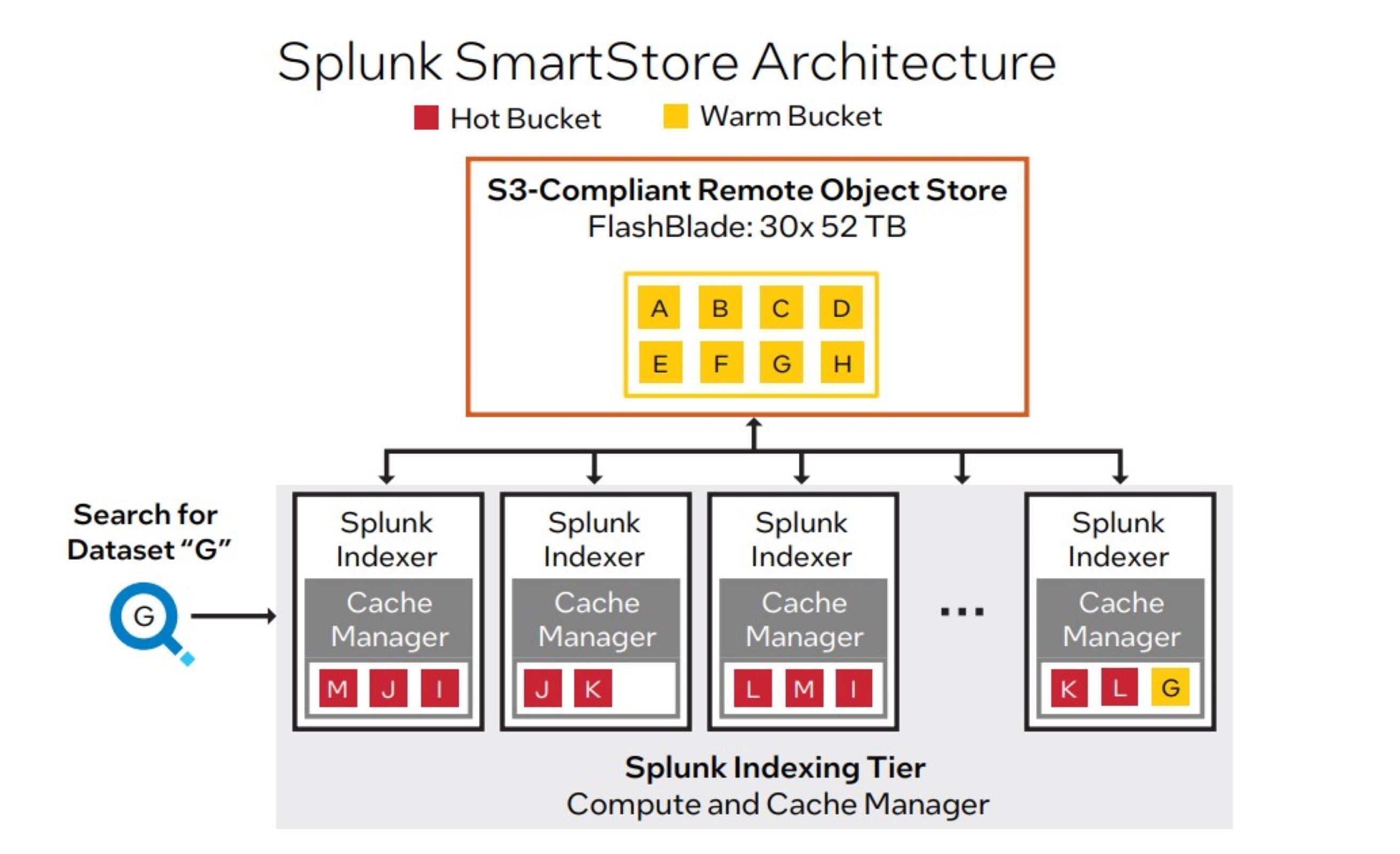 Intel
IntelDetermine 2. Splunk SmartStore utilizing FlashBlade for the distant object retailer.
Proof of Idea Testing Course of and Outcomes
The next exams had been carried out in our PoC:
- Take a look at #1: Take a look at Splunk ingest charges with simultaneous dense searches operating on bare-metal servers after which on the identical servers operating Splunk and Kafka on Kubernetes.
- Take a look at #2: Take a look at Splunk ingest price by studying enter knowledge from the Kafka native storage versus the enter knowledge from the Confluent Tiered Storage hosted on FlashBlade.
- Take a look at #3: Take a look at time required to run Splunk super-sparse searches accessing knowledge from Splunk SmartStore residing on FlashBlade.
For all of the exams, we used Intel IT’s real-world high-cardinality manufacturing knowledge from sources reminiscent of DNS, Endpoint Detection and Response (EDR) and Firewall, which had been collected into Kafka and ingested into Splunk by way of Splunk Join for Kafka.
Take a look at #1: Software Efficiency and Infrastructure Utilization
On this take a look at, we in contrast the efficiency of a naked‑metallic Splunk and Kafka deployment to a Kubernetes deployment. The take a look at consisted of studying knowledge from 4 Kafka matters and ingesting that knowledge into Splunk, whereas dense searches had been scheduled to run each minute.
Naked-Metallic Efficiency
We began with a bare-metal take a look at utilizing 9 bodily servers. 5 nodes served as Splunk indexers, three nodes as Kafka brokers and one node served as a Splunk search head. With this bare-metal cluster, the height ingest price was 301 MBps, whereas concurrently ending 90 profitable Splunk dense searches per minute (60 in cache, 30 from FlashBlade), with a median CPU utilization of 12%. The common search runtime for the Splunk dense search was 22 seconds.
Addition of Kubernetes
Subsequent, we deployed Splunk Operator for Kubernetes and Confluent for Kubernetes on the identical nine-node cluster. Kubernetes spawned 62 containers: 35 indexers, 18 Kafka brokers and 9 search heads. With this setup, we reached a peak Splunk ingest price of 886 MBps, whereas concurrently ending 400 profitable Splunk dense searches per minute (300 in cache, 100 from FlashBlade), with a median CPU utilization of 58%. The common search runtime for the Splunk dense search was 16 seconds—a 27% lower from the Splunk common search time on the bare-metal cluster. Determine 3 illustrates the improved CPU utilization gained from containerization utilizing Kubernetes. Determine 4 exhibits the excessive efficiency enabled by the reference structure.
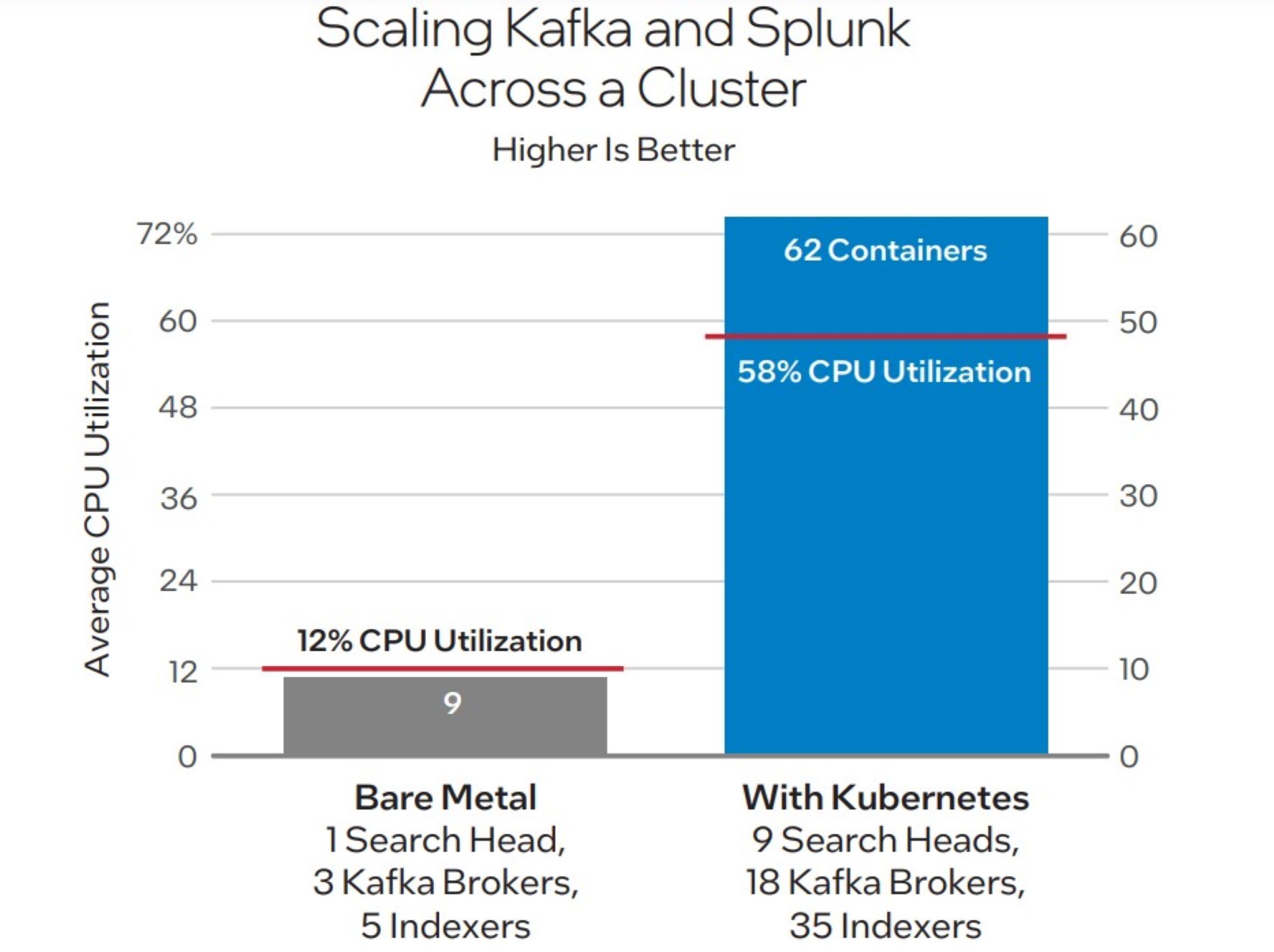 Intel
IntelDetermine 3. Deployment of the Splunk Operator for Kubernetes and Confluent for Kubernetes enabled 62 Splunk and Kafka containers on the 9 bodily servers in the PoC cluster.
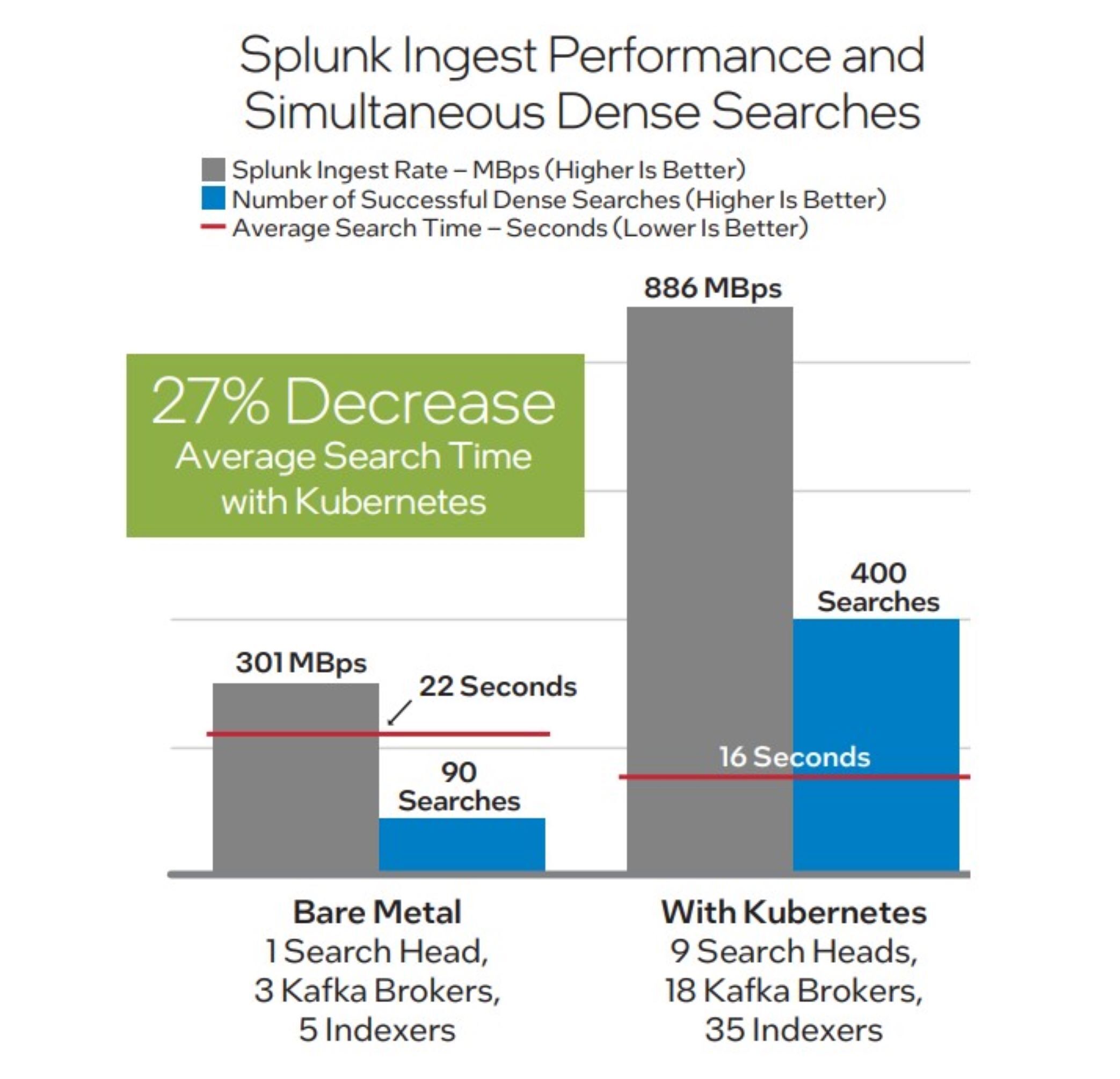 Intel
IntelIntel
Determine 4. Operating Splunk Operator for Kubernetes and Confluent for Kubernetes enabled as much as 2.9X increased ingest price, as much as 4x extra profitable dense searches, and a 27% discount in common Splunk search time, in comparison with the bare-metal cluster.
Take a look at #2: Knowledge Ingest from Kafka Native Storage versus Confluent Tiered Storage
Kafka’s two key capabilities in occasion streaming are producer (ingest) and client (search/learn). Within the traditional Kafka setup, the produced knowledge is maintained on the dealer’s native storage, however with Tiered Storage, Confluent offloads the info from the Tiered Storage to the thing retailer and permits infinite retention. If any client is in search of knowledge that isn’t within the native storage, the info can be downloaded from the thing storage.
To match the buyer/obtain efficiency, we began the Splunk Join staff for Kafka after one hour of information ingestion into Kafka with all knowledge on the native SSD storage. The Join staff learn the info from Kafka and forwarded it to the Splunk indexers, the place we measured the ingest throughput and elapsed time to load all of the unconsumed occasions. Throughout this time, Kafka learn the info from the native SSD storage, and Splunk was additionally writing the new buckets into the native SSD storage that hosts the new tier.
We repeated the identical take a look at when the subject was enabled with Tiered Storage by beginning the Splunk Join staff for Kafka, which initially learn the info out of FlashBlade and later from the native SSD storage for the final quarter-hour. We then measured the ingest throughput and the elapsed time to load all of the unconsumed occasions.
As proven in Determine 5, there is no such thing as a discount within the Kafka client efficiency when the dealer knowledge is hosted on Tiered Storage on FlashBlade. This reaffirms that offloading Kafka knowledge to the thing retailer, FlashBlade, offers not solely related efficiency for shoppers but in addition the additional advantage of longer retention.
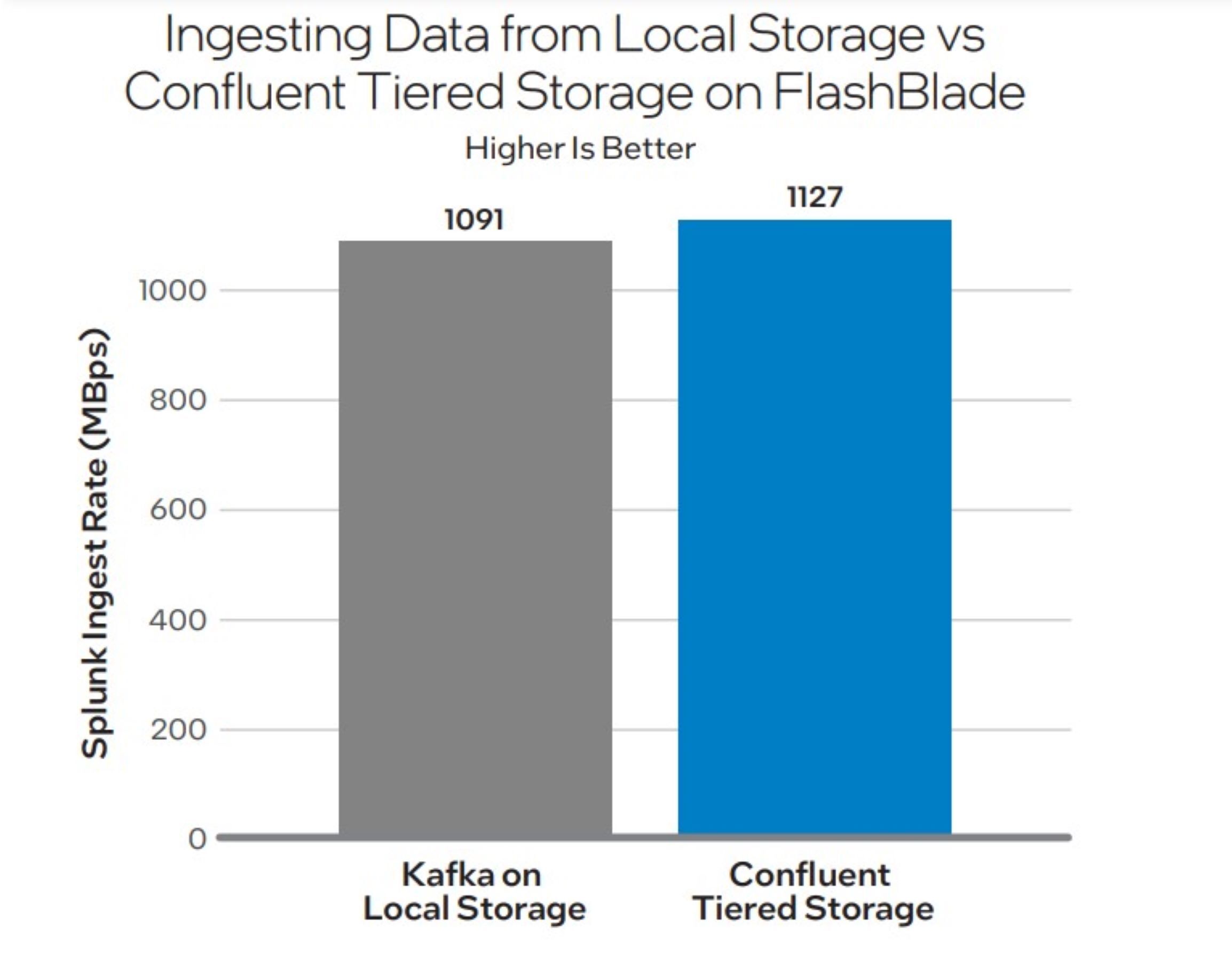 Intel
IntelIntel
Determine 5. Utilizing Confluent Tiered Storage with FlashBlade permits longer knowledge retention whereas sustaining (and even bettering) the ingest price.
Take a look at #3: Splunk Tremendous-Sparse Searches in Splunk SmartStore
When knowledge is within the cache, Splunk SmartStore searches are anticipated to be much like non-SmartStore searches. When knowledge isn’t within the cache, search occasions are depending on the quantity of information to be downloaded from the distant object retailer to the cache. Therefore, searches involving hardly ever accessed knowledge or knowledge protecting longer time intervals can have longer response occasions than skilled with non-SmartStore indexes. Nonetheless, FlashBlade accelerates the obtain time significantly compared to another “cheap-and-deep” object storage accessible at present.4
To reveal FlashBlade’s skill to speed up downloads, we examined the efficiency of a super-sparse search (the equal of discovering a needle in a haystack); the response time of any such search is usually tied to I/O efficiency. The search was initially carried out in opposition to the info within the Splunk cache to measure the ensuing occasion counts. The search returned 64 occasions out of a number of billion occasions. Following this, your entire cache was evicted from all of the indexers, and the identical super-sparse search was issued once more, which downloaded all of the required knowledge from FlashBlade into the cache to carry out the search. We found that FlashBlade supported a obtain of 376 GB in simply 84 seconds with a most obtain throughput of 19 GBps (see Desk 1).
Desk 1. Outcomes from Tremendous-Sparse Search
|
Outcomes |
|
|
Downloaded Buckets |
376 GB |
|
Elapsed Time |
84 seconds |
|
Common Obtain Throughput |
4.45 GBps |
|
Most Obtain Throughput |
19 GBps |
|
An excellent-sparse search downloading 376 GB in 84 Seconds |
|
Configuration Abstract
Introduction
The earlier pages supplied a high-level dialogue of the enterprise worth supplied by Intel Choose Options for Splunk and Kafka on Kubernetes, the applied sciences used within the answer and the efficiency and scalability that may be anticipated. This part supplies extra element concerning the Intel applied sciences used within the reference design and the invoice of supplies for constructing the answer.
Intel Choose Options for Splunk and Kafka on Kubernetes Design
The next tables describe the required parts wanted to construct this answer. Prospects should use firmware with the newest microcode. Tables 2, 3 and 4 element the important thing parts of our reference structure and PoC. The number of software program, compute, community, and storage parts was important to reaching the efficiency good points noticed.
Desk 2. Key Server Elements
|
Element |
Description |
|
CPU |
2x Intel® Xeon® Platinum 8360Y |
|
Reminiscence |
16x 32 GB DDR4 @ 3200 MT/s |
|
Storage (Cache Tier) |
1x Intel® Optane™ SSD P5800x (1.6 TB) |
|
Storage (Capability Tier) |
1x SSD DC P4510 (4 TB) |
|
Boot Drive |
1x SSD D3-S4610 (960 GB) |
|
Community |
Intel® Ethernet Community Adapter |
Desk 3. Software program Elements
|
Software program |
Model |
|
Kubernetes |
1.23.0 |
|
Splunk Operator for Kubernetes |
1.0.1 |
|
Splunk Enterprise |
8.2.0 |
|
Splunk Join for Kafka |
2.0.2 |
|
Confluent for Kubernetes |
2.2.0 |
|
Confluent Platform |
7.0.1 utilizing Apache Kafka 3.0.0 |
Desk 4. S3 Object Storage Elements
|
Pure Storage FlashBlade |
Description |
|
FlashBlades |
30x 52 TB blades |
|
Capability |
1560 TB uncooked 1440 TB usable (with no knowledge discount) |
|
Connectivity |
4x 100 Gb/s Ethernet (knowledge) 2x 1 Gb/s redundant Ethernet (administration port) |
|
Bodily |
10U (4U per chassis, 1U per XFM) |
|
Software program |
Purity//FB 3.1.10 |
Community Topology
Determine 6 illustrates the community format that’s used on this reference design.
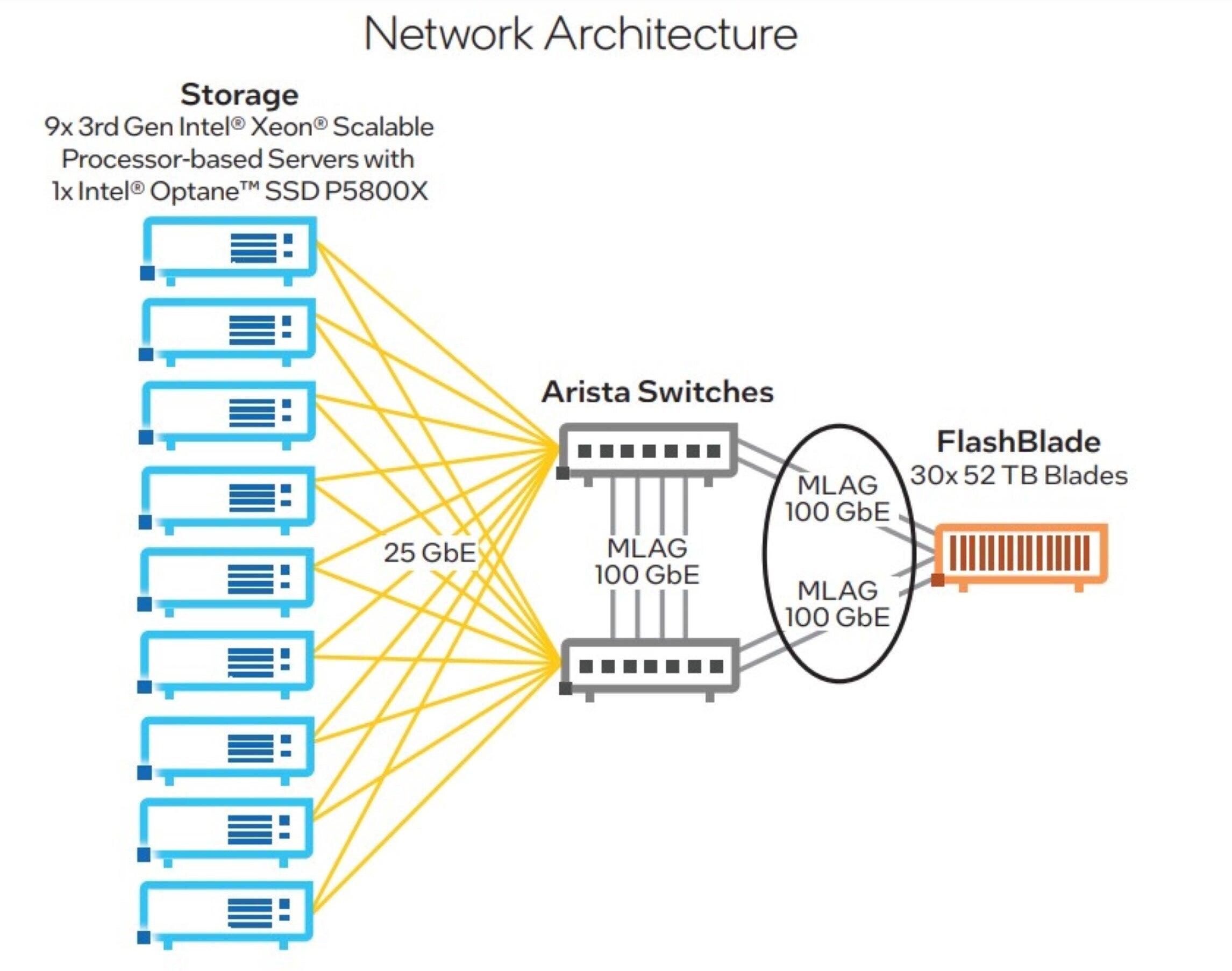 Intel
IntelDetermine 6. Community topology used within the Intel® Choose Options for Splunk and Kafka on Kubernetes.
Native Storage Particulars
The native NAND and Intel Optane SSDs on the servers had been used to provision the new/cache tier of the Splunk indexers and the Kafka brokers utilizing the Native Path Provisioner software, which makes use of the Native Persistent Quantity function of Kubernetes and creates the hostPath-based persistent quantity on the nodes routinely.
FlashBlade Configuration Particulars
The FlashBlade chassis are interconnected by high-speed hyperlinks to 2 exterior cloth modules (XFMs). Two onboard cloth modules are on the rear of every chassis to interconnect the blades, different chassis and purchasers utilizing TCP/IP over high-speed Ethernet. Each XFMs are interconnected, and every comprises a management processor and Ethernet swap ASIC. For reliability, every chassis is provided with redundant energy provides and cooling followers. The entrance of every chassis holds up to fifteen blades for processing knowledge operations and storage, and might assist greater than 1.5 million NFS IOPS, or as much as 15 GB/s of bandwidth on a single chassis with 15 blades on a 3:1 compressible dataset.5
Key Applied sciences
A number of Intel merchandise had been utilized to assist enhance efficiency.
third Era Intel Xeon Scalable Processors
Intel’s newest processors for knowledge heart workloads are third Gen Intel Xeon Scalable processors. They’re full of performance- and security-enhancing options, together with the next:
- Enhanced per-core efficiency, with as much as 40 cores in a commonplace socket
- Enhanced reminiscence efficiency with assist for as much as 3200 MT/s DIMMs (2 DIMMs per channel)
- Elevated reminiscence capability with as much as eight channels
- Sooner inter-node connections with three Intel® Extremely Path Interconnect hyperlinks at 11.2 GT/s
- Extra, quicker I/O with PCI Categorical 4 and as much as 64 lanes (per socket) at 16 GT/s
Intel Optane SSDs
Intel Optane SSD P5800X with next-generation Intel Optane storage media and superior controller delivers “no-compromises” I/O efficiency—learn or write. It additionally has excessive endurance, offering unprecedented worth over legacy storage within the accelerating world of clever knowledge. Intel Optane SSD P5800X delivers 4x higher random 4K combined learn/write IOPS and 67 p.c increased endurance in comparison with the previous-generation Intel Optane SSD DC P4800X, which makes use of PCIe gen 3.6
Intel Ethernet 800 Sequence
The Intel Ethernet 800 Sequence is the subsequent evolution in Intel’s line of Ethernet merchandise. In comparison with the Intel Ethernet 700 Sequence, the 800 Sequence presents increased bandwidth because of the usage of PCIe 4.0 and 50 Gb PAM4 SerDes. It additionally improves utility effectivity with Software System Queues and enhanced Dynamic System Personalization. The 800 Sequence is flexible, providing 2x 100/50/25/10 GbE, 4x 25/10 GbE or 8x 10 GbE connectivity. It additionally helps RDMA for each iWARP and RoCE v2, which supplies enterprises a alternative when designing their hyperconverged networks.
Reference Design and PoC Key Learnings
Whereas constructing out our reference structure, the following key learnings got here to gentle:
- To attain optimum efficiency and scaling, it’s really helpful to comply with best-practices guides for reference structure parts reminiscent of Splunk and Kafka.
- Particularly, it’s advisable to confirm that you’re utilizing the right model of software program, firmware and OS; typically the really helpful model is the newest model, however not at all times.
- As a result of these cloud-native applied sciences are comparatively new, plan on performing trial and error with configurations previous to manufacturing implementation.
- Confirm that you’ve got arrange monitoring instruments for the completely different layers of software program and {hardware}, so you’ll be able to evaluate outcomes over time.
- Make the most of high-core-count third Gen Intel Xeon Platinum or Gold processors to supply high-performance compute.
Conclusion
The demand for knowledge in addition to the enterprise alternatives from massive knowledge units has by no means been higher. However the challenges of harnessing and managing knowledge proceed to plague organizations of all sizes, and in each business.
The launch of Splunk Operator for Kubernetes and Confluent for Kubernetes, mixed with Splunk SmartStore and Confluent Tiered Storage, provide new knowledge architectures designed with containers and S3‑appropriate storage. In our PoC, we demonstrated how these new cloud-native applied sciences, operating on Intel structure and Pure Storage FlashBlade, may also help enhance utility efficiency and operational effectivity, improve infrastructure utilization and simplify the administration of hybrid and multi-cloud environments.
Be taught Extra
Discover the answer that’s proper on your group. Contact your Intel consultant.
Authors:
Aleksander Kantak, Cloud Options Engineer, Intel
Murali Madhanagopal, Cloud Software program Architect, Intel
Somu Rajarathinam, Technical Director, Pure Storage Intel
Contributors: Mariusz Klonowski, Victor Colvard, Dennis Kwong, Elaine Rainbolt, Merritte Stidston, Jason Stark
Revision Historical past
|
Doc Quantity |
Revision Quantity |
Description |
Date |
|
1.0 |
First Launch |
June 2022 |
1 See intel.com/performanceindex for workloads and configurations. Outcomes could differ. Particularly, consult with “DTCC003 Maximizing Efficiency, Scalability and Operational Effectivity with Kubernetes and Splunk SmartStore” at https://edc.intel.com/content material/www/us/en/merchandise/efficiency/benchmarks/vision-2022
2 ContainIQ, “26 Kubernetes Statistics to Reference,” https://www.containiq.com/publish/kubernetes-statistics
3 See endnote 1.
4 Pure Storage, “Splunk SmartStore on FlashBlade,” https://assist.purestorage.com/Options/Splunk/Splunk_Reference/Splunk_SmartStore_on_FlashBlade
6 See [2] and [15] at https://edc.intel.com/content material/www/us/en/merchandise/efficiency/benchmarks/intel-optane-ssd-p5800x-series/
Efficiency varies by use, configuration and different elements. Be taught extra at intel.com/PerformanceIndex. Efficiency outcomes are based mostly on testing by Intel as of February 2019 and will not mirror all publicly accessible safety updates. See configuration disclosures for particulars. No product or element could be completely safe. Your prices and outcomes could differ. Intel doesn’t management or audit third-party knowledge. It is best to seek the advice of different sources to guage accuracy. Intel applied sciences could require enabled {hardware}, software program or service activation. Intel, the Intel emblem, and different Intel marks are logos of Intel Company or its subsidiaries. Different names and types could also be claimed because the property of others.
© Intel Company 0522/JSTA/KC/PDF
Copyright © 2022 IDG Communications, Inc.

{kind=link}