Learn to work with the Pandas resample methodology, a cool technique to work with time primarily based information
Time primarily based information is without doubt one of the commonest information codecs that you just, as information scientist, have in all probability stumbled. Both within the format of historic options (as an illustration, buyer information) or time sequence information, it’s fairly frequent that one has to cope with timestamp columns in information pipelines.
For those who work as a knowledge scientist in 2022, it’s necessary that you understand how to work with pandas, one of the crucial highly effective Python libraries to wrangle information. pandasis known for its common updates and new strategies that match quite a lot of duties concerning information wrangling and manipulation.
One in every of its most well-known strategies is the resampleone, that permits you to deal with time primarily based information easily. In a nutshell, resample accommodates a number of options that assist you to sort out time primarily based grouping and aggregation in a extremely easy manner, bettering the velocity and ease when working with datetime columns. Up to now, you’d in all probability should assemble difficult (and even buggy) features, that will tend to be laborious to keep up. With resample that’s utterly gone and you’ll mess around with dates in pandas dataframes a lot simply.
On this submit, we’ll discover some cool issues about this methodology and the way straightforward it’s to use it — significantly once we wish to create time primarily based options for our information science algorithms.
First, I‘ll begin by loading a time sequence information set that consists of Hourly Climate information between 2008 and 2021 in Gallipoli, Turkey — a dataset belonging to Meteoblue.
Let me begin by loading this dataset into Python:
gallipoli_data = pd.read_csv(‘../Hourly Climate Information in Gallipoli (2008–2021).csv’)
Let’s have a look at the primary 10 rows of the dataset:

To work with resample, our information should meet two situations:
- The column that we are going to be utilizing to symbolize time have to be a
datetimeinformation sort. - That column should go into the index of the dataframe.
Beginning by changing the DateTime column right into a DateTime sort:
gallipoli_data[‘DateTime’] = pd.to_datetime(gallipoli_data[‘DateTime’])
And passing our column into the index of the dataframe:
gallipoli_data.index = gallipoli_data[‘DateTime’]
Our dataframe is prepared! Let’s additionally load the libraries wanted to observe alongside this weblog submit:
import pandas as pdimport numpy as np
Having all the things arrange, let’s sort out our resample methodology!
Let’s begin with a easy use case: think about that we wish to get the common temperature in Gallipoli for each 3 hour interval. Though easy, if we might strive to do that in base Python or with customized pandas code, it could be a bit cumbersome as we must:
- create some sort of column that will increment each 3 hours;
- use a bunch by on that column;
Though that is manageable with a few strains of code, a one liner could be higher, proper? And what if that one liner would additionally have the ability to generalize for different time frames (weeks, months, quarter and even minutes)? That’s precisely what resample is for! We are able to carry out a fast time primarily based aggregation on the information actually quick:
gallipoli_data.Temperature.resample(rule = ‘3h’).imply()
Right here’s the output of the code above:
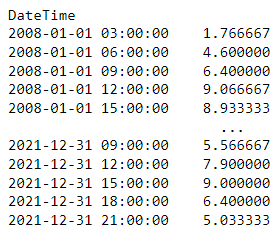
How cool? The resample methodology accommodates a bunch of knobs we are able to flip such because the rule or the aggregator perform we’re utilizing. Are you able to guess what we have to tweak if we wish to examine the utmost worth of sunshine period in an interval of three hours? We simply swap imply() for max() !
gallipoli_data[‘Sunshine Duration’].resample(rule = ‘3h’).max()

To make this much more clear and peak beneath the hood of resample, let’s see the evolution of the Sunshine Length for the 2nd of January in Gallipoli:
(
gallipoli_data.loc[
(gallipoli_data.DateTime >= '2008-01-02')
&
(gallipoli_data.DateTime <= '2008-01-03')
]
)['Sunshine Duration'].plot(coloration='darkorange')
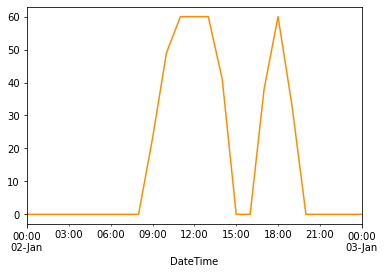
Whatresample is doing is grouping information for each three hours by making use of the next:
- From 9 a.m. till 12, the utmost
Sunshine Lengthis 60. - From midday till 15 p.m., the utmost
Sunshine Lengthis 60. - From 15 till 18 p.m., the utmost
Sunshine Lengthis 38.
That is mirrored on the desk we’ve seen above — checking it once more:
Discover that the interval is closed on the left aspect. Which means that the row that pertains to 2008-01-02 09:00:00 aggregates the complete information from 09:00:00 a.m. till 11:59:59 a.m. If we wish to change this habits, we have to move a brand new argument closedto the resample :
gallipoli_data['Sunshine Duration'].resample(rule = '3h', closed= 'proper').max()
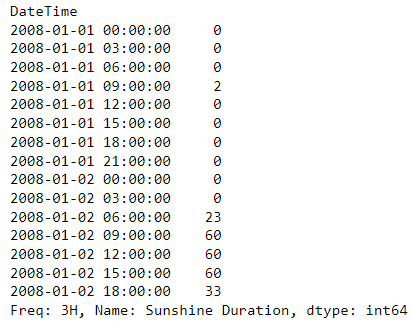
On this case, the identical row 2008-01-02 09:00:00 aggregates all information from 09:00:01 a.m. till 12:00:00 a.m.
Tweaking the resample knobs may be very straightforward. One other frequent argument that we might wish to tweak is the timeframe aggregation — as an illustration, aggregating our information by week or month. Is that this attainable? Let’s see, subsequent.
With the ruleargument we’re not solely restricted to hourly aggregations! This is without doubt one of the coolest options of the resampleperform. As an example, if we want a bi-weekly aggregation, we are able to:
gallipoli_data.Temperature.resample(rule = ‘2w’).imply()
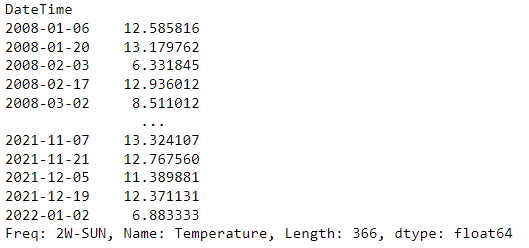
The quantity earlier than the w defines the variety of situations we wish to group by and the w defines that we would like every week timeframe.
Are you able to guess what’s the argument we have to move to combination our information for each 4-months?
gallipoli_data.Temperature.resample(rule = ‘4m’).imply()

In abstract, rule controls the time interval we wish to group by. Among the most well-known rule parameters you should utilize are:
sfor secondstfor minuteshfor hourswfor weeksmfor monthsqfor quarter
One other necessary characteristic of resampleis that it might assist you to create a extra full information body by making sense of the gaps within the information. As an example, think about we might have a hourly gross sales dataset from a store:
date_range = pd.date_range('1/2/2022', intervals=24, freq='H')
gross sales = np.random.randint(100, 400, dimension=24)sales_data = pd.DataFrame(
gross sales,
index = date_range,
columns = ['Sales']
)
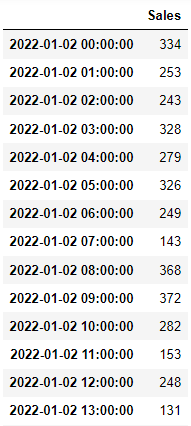
Let’s delete the row of the gross sales at 10 a.m. (imagining this was one thing that actually occurred and there have been no gross sales on this retailer throughout this time):
sales_data = sales_data.drop(sales_data.iloc[10].title)

If we apply a resampleto this dataframe, a brand new row with NaN will present up:
pd.DataFrame(
sales_data.Gross sales.resample('h').imply()
)

That is extraordinarily helpful in quite a lot of time primarily based situations. Usually, if we have now a niche in our time sequence information, we wish to have a row that represents that hole and resample offers us a fast technique to obtain it. Within the instance above, we are able to even add a fillna(0) to make our situation of “lack of gross sales” at 10 a.m. much more apparent:
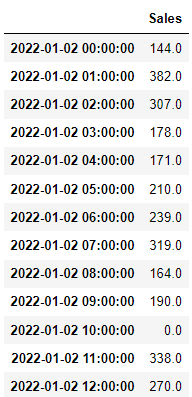
Filling the gaps is a extremely frequent factor we might wish to do when working with time primarily based information. Not solely when creating options, but in addition as a technique to catch main bugs on our information pipelines.
Thanks for taking the time to learn this submit!
For those who work with time primarily based information and by no means usedresample earlier than, I actually advocate that you just examine this methodology completely as it would prevent quite a lot of complications throughout your information wranling course of.
Both once we’re constructing time primarily based options or manipulating time-series information, utilizing resample makes our code extra environment friendly and clear. As we’ve mentioned, this methodology can be helpful to catch some sudden gaps in time-based information so I hope you should utilize the data on this submit someday in your future information pipelines!
The dataset used on this submit is beneath CC BY 4.0 and belongs to Meteoblue.
