Pure language processing (NLP) analysis predominantly focuses on creating strategies that work properly for English regardless of the various optimistic advantages of engaged on different languages. These advantages vary from an outsized societal impression to modelling a wealth of linguistic options to avoiding overfitting in addition to fascinating challenges for machine studying (ML).
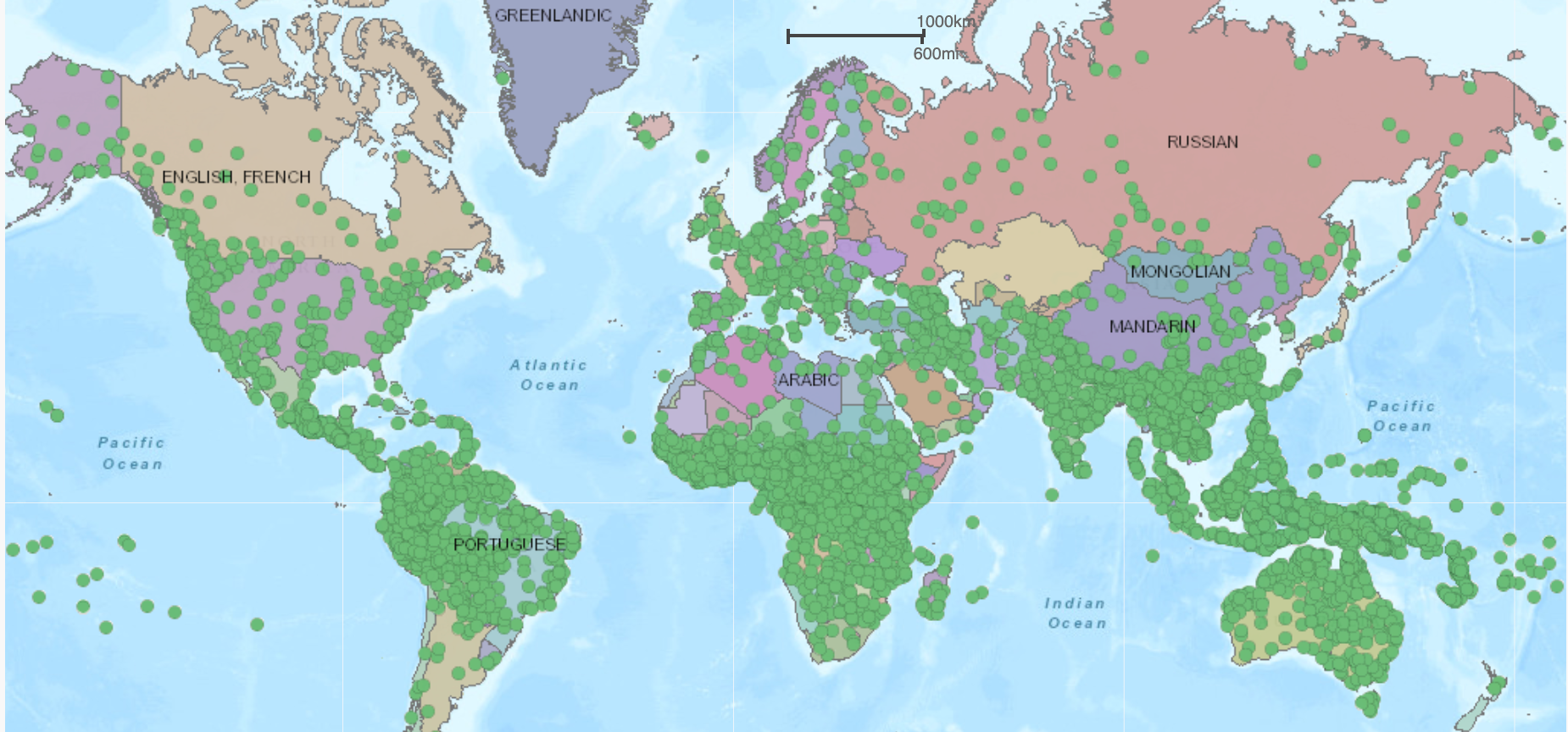
There are round 7,000 languages spoken all over the world. The map above (see the interactive model at Langscape) provides an summary of languages spoken all over the world, with every inexperienced circle representing a local language. A lot of the world’s languages are spoken in Asia, Africa, the Pacific area and the Americas.
Whereas we now have seen thrilling progress throughout many duties in pure language processing (see Papers with Code and NLP Progress for an summary) over the past years, most such outcomes have been achieved in English and a small set of different high-resource languages.
In a earlier overview of our ACL 2019 tutorial on Unsupervised Cross-lingual Illustration Studying, I’ve outlined a useful resource hierarchy based mostly on the provision of unlabelled information and labelled information on-line. In a current ACL 2020 paper, Joshi et al. outline a taxonomy equally based mostly on information availability, which you’ll see under.
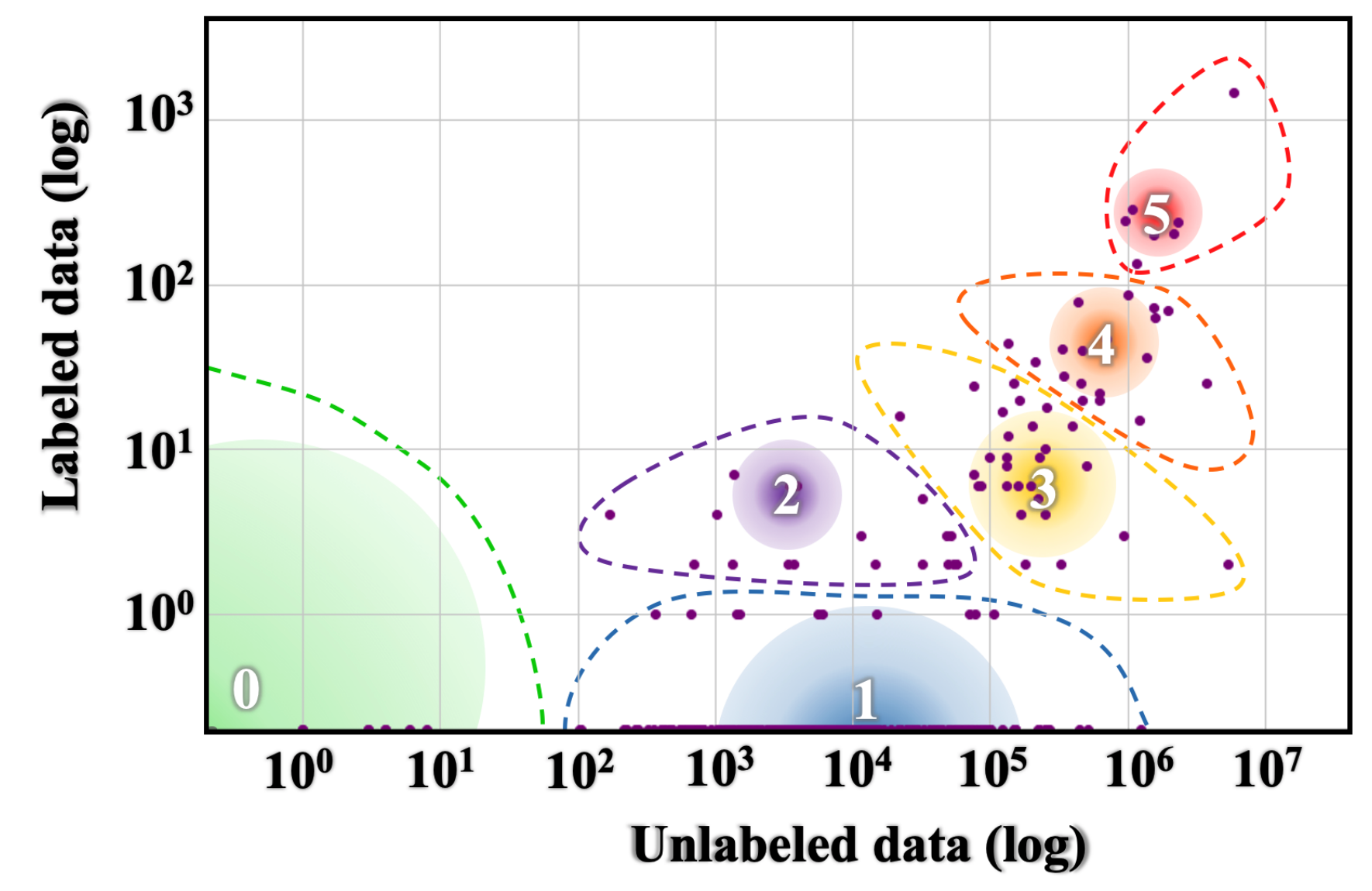
Languages in classes 5 and 4 that lie at a candy spot of getting each massive quantities of labelled and unlabelled information out there to them are well-studied within the NLP literature. However, languages within the different teams have largely been uncared for.
On this publish, I’ll argue why it is best to work on languages apart from English. Particularly, I’ll spotlight causes from a societal, linguistic, machine studying, cultural and normative, and cognitive perspective.
The societal perspective
Know-how can’t be accessible if it’s only out there for English audio system with a commonplace accent.
What language you communicate determines your entry to info, training, and even human connections. Although we consider the Web as open to everybody, there’s a digital language divide between dominant languages (principally from the Western world) and others. Just a few hundred languages are represented on the net and audio system of minority languages are severely restricted within the info out there to them.
As many extra languages are being written in casual contexts in chat apps and on social media, this divide extends to all ranges of expertise: On the most simple language expertise stage, low-resource languages lack keyboard help and spell checking (Soria et al., 2018)—and keyboard help is even rarer for languages and not using a widespread written custom (Paterson, 2015). At the next stage, algorithms are biased and discriminate towards audio system of non-English languages or just with completely different accents.
The latter is an issue as a result of a lot present work treats a high-resource language akin to English as homogeneous. Our fashions consequently underperform on the plethora of associated linguistic subcommunities, dialects, and accents (Blodgett et al., 2016). In actuality, the boundaries between language varieties are a lot blurrier than we make them out to be and language identification of comparable languages and dialects continues to be a difficult downside (Jauhiainen et al., 2018). For example, although Italian is the official language in Italy, there are round 34 regional languages and dialects spoken all through the nation.
A unbroken lack of technological inclusion won’t solely exacerbate the language divide however it could additionally drive audio system of unsupported languages and dialects to high-resource languages with higher technological help, additional endangering such language varieties. To make sure that non-English language audio system will not be left behind and on the similar time to offset the prevailing imbalance, to decrease language and literacy boundaries, we have to apply our fashions to non-English languages.
The linguistic perspective
Although we declare to be desirous about creating basic language understanding strategies, our strategies are usually solely utilized to a single language, English.
English and the small set of different high-resource languages are in some ways not consultant of the world’s different languages. Many resource-rich languages belong to the Indo-European language household, are spoken principally within the Western world, and are morphologically poor, i.e. info is generally expressed syntactically, e.g. through a hard and fast phrase order and utilizing a number of separate phrases fairly than by way of variation on the phrase stage.
For a extra holistic view, we are able to check out the typological options of various languages. The World Atlas of Language Construction catalogues 192 typological options, i.e. structural and semantic properties of a language. For example, one typological characteristic describes the standard order of topic, object, and verb in a language. Every characteristic has 5.93 classes on common. 48% of all characteristic classes exist solely within the low-resource languages of teams 0–2 above and can’t be present in languages of teams 3–5 (Joshi et al., 2020). Ignoring such a big subset of typological options implies that our NLP fashions are doubtlessly lacking out on precious info that may be helpful for generalisation.
Engaged on languages past English might also assist us achieve new information concerning the relationships between the languages of the world (Artetxe et al., 2020). Conversely, it could assist us reveal what linguistic options our fashions are in a position to seize. Particularly, you might use your information of a specific language to probe facets that differ from English akin to using diacritics, intensive compounding, inflection, derivation, reduplication, agglutination, fusion, and so on.
The ML perspective
We encode assumptions into the architectures of our fashions which are based mostly on the information we intend to use them. Although we intend our fashions to be basic, lots of their inductive biases are particular to English and languages much like it.
The shortage of any explicitly encoded info in a mannequin doesn’t imply that it’s really language agnostic. A traditional instance are n-gram language fashions, which carry out considerably worse for languages with elaborate morphology and comparatively free phrase order (Bender, 2011).
Equally, neural fashions typically overlook the complexities of morphologically wealthy languages (Tsarfaty et al., 2020): Subword tokenization performs poorly on languages with reduplication (Vania and Lopez, 2017), byte pair encoding doesn’t align properly with morphology (Bostrom and Durrett, 2020), and languages with bigger vocabularies are tougher for language fashions (Mielke et al., 2019). Variations in grammar, phrase order, and syntax additionally trigger issues for neural fashions (Ravfogel et al., 2018; Ahmad et al., 2019; Hu et al., 2020). As well as, we usually assume that pre-trained embeddings readily encode all related info, which is probably not the case for all languages (Tsarfaty et al., 2020).
The above issues pose distinctive challenges for modelling construction—each on the phrase and the sentence stage—, coping with sparsity, few-shot studying, encoding related info in pre-trained representations, and transferring between associated languages, amongst many different fascinating instructions. These challenges will not be addressed by present strategies and thus name for a brand new set of language-aware approaches.
Current fashions have repeatedly matched human-level efficiency on more and more troublesome benchmarks—that’s, in English utilizing labelled datasets with 1000’s and unlabelled information with hundreds of thousands of examples. Within the course of, as a neighborhood we now have overfit to the traits and situations of English-language information. Specifically, by specializing in high-resource languages, we now have prioritised strategies that work properly solely when massive quantities of labelled and unlabelled information can be found.
In distinction, most present strategies break down when utilized to the data-scarce situations which are frequent for a lot of the world’s languages. Even current advances in pre-training language fashions that dramatically cut back the pattern complexity for downstream duties (Peters et al., 2018; Howard and Ruder, 2018; Devlin et al., 2019; Clark et al., 2020) require large quantities of unpolluted, unlabelled information, which isn’t out there for a lot of the world’s languages (Artetxe et al., 2020). Doing properly with few information is thus an excellent setting to check the restrictions of present fashions—and analysis on low-resource languages constitutes arguably its most impactful real-world utility.
The cultural and normative perspective
The info our fashions are skilled on reveals not solely the traits of the precise language but additionally sheds gentle on cultural norms and customary sense information.
Nevertheless, such frequent sense information could also be completely different for various cultures. For example, the notion of ‘free’ and ‘non-free’ varies cross-culturally the place ‘free’ items are ones that anybody can use with out looking for permission, akin to salt in a restaurant. Taboo matters are additionally completely different in several cultures. Moreover, cultures range of their evaluation of relative energy and social distance, amongst many different issues (Thomas, 1983). As well as, many real-world conditions akin to ones included within the COPA dataset (Roemmele et al., 2011) don’t match the direct expertise of many and equally don’t mirror key conditions which are apparent background information for many individuals on the earth (Ponti et al., 2020).
Consequently, an agent that was solely uncovered to English information originating primarily within the Western world could possibly have an inexpensive dialog with audio system from Western nations, however conversing with somebody from a unique tradition might result in pragmatic failures.
Past cultural norms and customary sense information, the information we practice a mannequin on additionally displays the values of the underlying society. As an NLP researcher or practitioner, we now have to ask ourselves whether or not we wish our NLP system to completely share the values of a particular nation or language neighborhood.
Whereas this determination could be much less vital for present programs that principally cope with easy duties akin to textual content classification, it would turn into extra vital as programs turn into extra clever and must cope with complicated decision-making duties.
The cognitive perspective
Human youngsters can purchase any pure language and their language understanding potential is remarkably constant throughout all types of languages. To be able to obtain human-level language understanding, our fashions ought to be capable to present the identical stage of consistency throughout languages from completely different language households and typologies.
Our fashions ought to in the end be capable to study abstractions that aren’t particular to the construction of any language however that may generalise to languages with completely different properties.
What you are able to do
Datasets If you happen to create a brand new dataset, reserve half of your annotation finances for creating the identical measurement dataset in one other language.
Analysis If you’re desirous about a specific process, contemplate evaluating your mannequin on the identical process in a unique language. For an summary of some duties, see NLP Progress or our XTREME benchmark.
Bender Rule State the language you’re engaged on.
Assumptions Be express concerning the indicators your mannequin makes use of and the assumptions it makes. Think about that are particular to the language you’re learning and which could be extra basic.
Language range Estimate the language range of the pattern of languages you’re learning (Ponti et al., 2020).
Analysis Work on strategies that deal with challenges of low-resource languages. Within the subsequent publish, I’ll define fascinating analysis instructions and alternatives in multilingual NLP.
Quotation
For attribution in tutorial contexts, please cite this work as:
@misc{ruder2020beyondenglish,
creator = {Ruder, Sebastian},
title = {{Why You Ought to Do NLP Past English}},
12 months = {2020},
howpublished = {url{http://ruder.io/nlp-beyond-english}},
}Due to Aida Nematzadeh, Laura Rimell, and Adhi Kuncoro for precious suggestions on drafts of this publish.

{kind=link}