This submit expands on the ACL 2019 tutorial on Unsupervised Cross-lingual Illustration Studying.
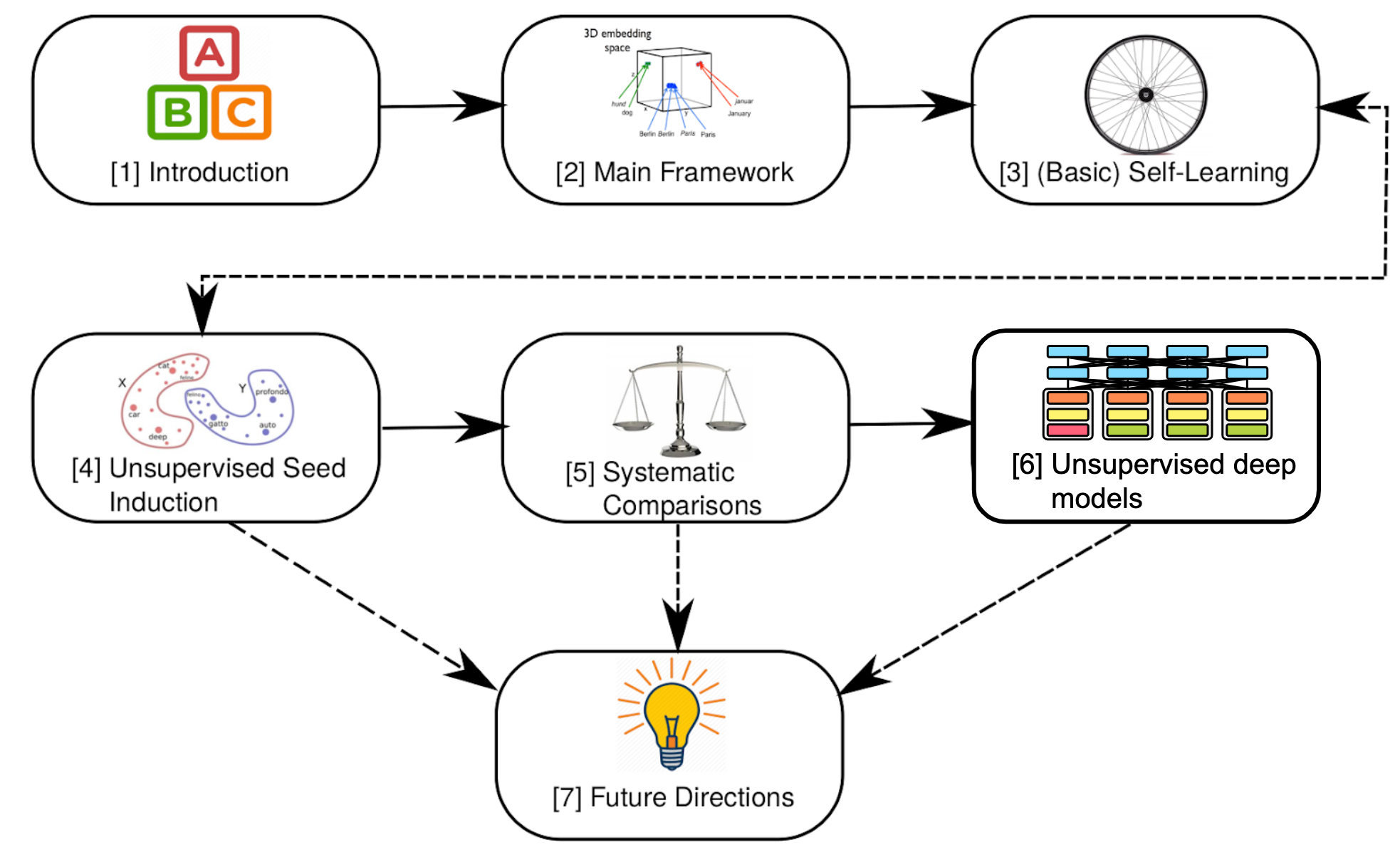
The tutorial was organised by Ivan Vulić, Anders Søgaard, and me. On this submit, I spotlight key insights and takeaways and supply further context and updates primarily based on latest work. Particularly, I cowl unsupervised deep multilingual fashions reminiscent of multilingual BERT. You possibly can see the construction of this submit under:
The slides of the tutorial are out there on-line.
Cross-lingual illustration studying may be seen for example of switch studying, just like area adaptation. The domains on this case are totally different languages.
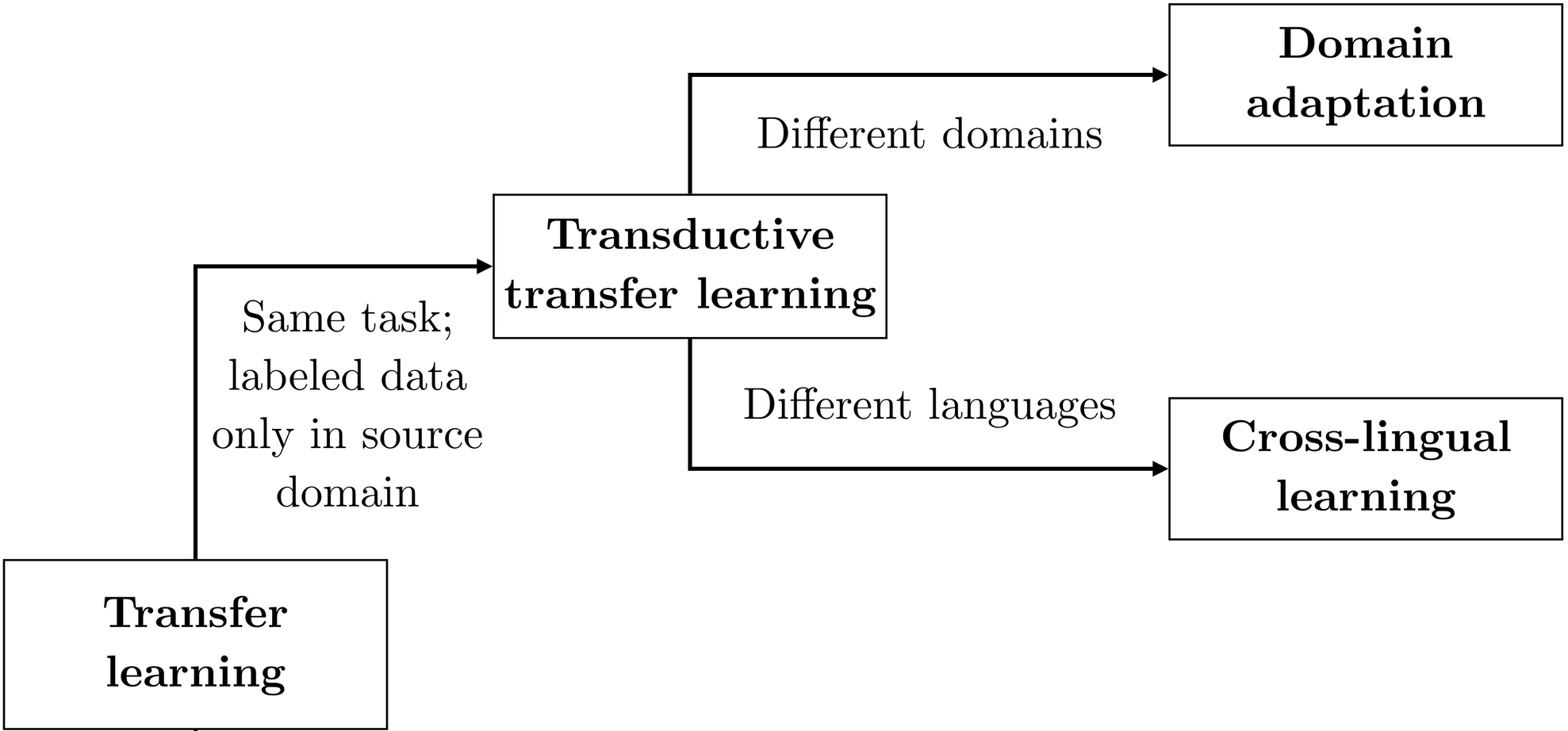
Strategies from area adaptation have additionally been utilized to cross-lingual switch (Prettenhofer & Stein, 2011, Wan et al., 2011). For a clearer distinction between area adaptation and cross-lingual studying, take a look at this part.
Viewing cross-lingual studying as a type of switch studying might help us perceive why it is perhaps helpful and when it would fail:
- Switch studying is beneficial at any time when the situations between which we switch share some underlying construction. In the same vein, languages share commonalities on many ranges—from loanwords and cognates on the lexical stage, to the construction of sentences on the syntactic stage, to the that means of phrases on the semantic stage. Studying in regards to the construction of 1 language might subsequently assist us do higher when studying a second language.
- Switch studying struggles when the supply and goal settings are too totally different. Equally, it’s tougher to switch between languages which are dissimilar (e.g. which have totally different typological options within the World Atlas of Language Buildings).
Much like the broader switch studying panorama, a lot of the work on cross-lingual studying during the last years has targeted on studying representations of phrases. Whereas there have been approaches that be taught sentence-level representations, solely not too long ago are we witnessing the emergence of deep multilingual fashions. Take a look at this survey for an outline of the historical past of cross-lingual fashions. For extra on switch studying, take a look at this latest submit. Cross-lingual studying is perhaps helpful—however why ought to we care about making use of NLP to different languages within the first place?
The Digital Language Divide
The language you converse shapes your expertise of the world. This is called the Sapir-Whorf speculation and is contested. Alternatively, it’s factual that the language you converse shapes your expertise of the world on-line. What language you converse determines your entry to info, schooling, and even human connections. In different phrases, regardless that we consider the Web as being open to anybody, there’s a digital language divide between dominant languages (largely from the western world) and others.
As NLP applied sciences have gotten extra commonplace, this divide extends to the technological stage: At finest, which means that non-English language audio system don’t profit from the most recent options of digital assistants; at worst, algorithms are biased towards or discriminate towards audio system of non-English languages—we are able to see occurrences of this already at present. To make sure that non-English language audio system usually are not left behind and on the identical time to offset the present imbalance, we have to apply our fashions to non-English languages.
The NLP Useful resource Hierarchy
In present machine studying, the quantity of obtainable coaching knowledge is the primary issue that influences an algorithm’s efficiency. Knowledge that’s helpful for present NLP fashions can vary from unlabelled knowledge within the type of paperwork on-line or articles on Wikipedia, labelled knowledge within the type of giant curated datasets, or parallel corpora utilized in machine translation.
We are able to roughly differentiate between languages with many and languages with few knowledge sources in a hierarchy, which may be seen under.

This roughly corresponds with a language’s presence on-line. Observe that many languages can’t be assigned clearly to a single stage of the hierarchy. Some languages with few audio system reminiscent of Aragonese or Waray-Waray have a disproportionally giant Wikipedia, whereas for others reminiscent of Latvian parallel knowledge is out there as a consequence of their standing as an official language. Alternatively, many languages with tens of thousands and thousands of audio system reminiscent of Xhosa and Zulu have barely greater than 1,000 Wikipedia articles.
Nonetheless, the existence of such a hierarchy highlights why unsupervised cross-lingual illustration studying is promising: for many of the world’s languages, no labelled knowledge is out there and creating labelled knowledge is pricey as native audio system are under-represented on-line. With a purpose to prepare fashions for such languages, we have to make use of unlabelled knowledge and switch studying from high-resource languages.
Cross-lingual Representations
Whereas prior to now it was essential to be taught language-specific fashions for each language and preprocessing and options wanted to be utilized to each language in isolation, cross-lingual illustration studying permits us to use the switch studying components of pretraining and adaptation throughout languages.
On this context, we’ll speak about a (high-resource) supply language (L_1) the place unlabelled knowledge and labelled knowledge for a specific activity can be found, and a (low-resource) goal language (L_2) the place solely unlabelled knowledge is out there. For cross-lingual switch studying, we add one further step to the switch studying recipe above:
- Pretraining: Be taught cross-lingual representations which are shared throughout languages. That is what the remainder of this submit is about.
- Adaptation: Adapt the mannequin to the labelled knowledge of the specified activity in (L_1) by studying task-specific parameters on high of the cross-lingual representations. The cross-lingual parameters are sometimes saved fastened (this is similar as characteristic extraction). Because the task-specific parameters are discovered on high of cross-lingual ones, they’re anticipated to switch to the opposite language.
- Zero-shot switch: The mannequin, which captures cross-lingual info, may be utilized on to carry out inference on knowledge of the goal language.
If labelled knowledge within the goal language can also be out there, then the mannequin may be fine-tuned collectively on each languages in Step 2.
All through this submit, I’ll concentrate on approaches that be taught cross-lingual representations because the means for transferring throughout languages. Relying on the duty, there are different methods of transferring info throughout languages reminiscent of by area adaptation (as seen above), annotation projection (Padó & Lapata, 2009; Ni et al., 2017; Nicolai & Yarowsky, 2019), distant supervision (Plank & Agić, 2018) or machine translation (MT; Zhou et al., 2016; Eger et al., 2018).
Why not Machine Translation?
In gentle of the latest success of massively multilingual and unsupervised machine translation (Lample et al., 2018; Artetxe et al., 2019), an apparent query is why we’d not simply use MT to translate the coaching knowledge in our supply language to the goal language and prepare a mannequin on the translated knowledge—or translate the take a look at set and apply our supply mannequin on to it, which regularly works higher in observe. If an MT system is out there, this is usually a sturdy baseline (Conneau et al., 2018) and unsupervised MT specifically may be helpful for low-resource languages (Lample et al., 2018).
Nevertheless, an MT system for the specified language pair will not be simply out there and may be costly to coach. As well as, fashions educated on machine-translated knowledge usually underperform state-of-the-art deep multilingual fashions. MT struggles with distant language pairs and area mismatches (Guzmán et al., 2019). It’s also not a match for all duties; the efficiency of translation-based fashions for query answering duties relies upon closely on the interpretation high quality of named entities (Liu et al., 2019). For sequence labelling duties, MT requires projecting annotations throughout languages, itself a tough drawback (Akbik & Vollgraf, 2018).
Generally, nevertheless, MT and the strategies described on this submit usually are not at odds however complementary. Cross-lingual phrase representations are used to initialise unsupervised MT (Artetxe et al., 2019) and cross-lingual representations have been proven to enhance neural MT efficiency (Lample & Conneau, 2019). Strategies from MT reminiscent of phrase alignment have additionally impressed a lot work in cross-lingual illustration studying (Ruder et al., 2019). Lastly, a multilingual mannequin advantages from being fine-tuned on translations of the labelled knowledge in a number of languages (Conneau et al., 2019).
We now focus on the best way to be taught unsupervised representations, beginning on the phrase stage. The primary framework for studying cross-lingual phrase embeddings (CLWEs) consists of mapping-based or post-hoc alignment approaches. For an outline of different approaches, take a look at our survey or ebook on the subject.
Mapping-based strategies are at present the popular method as a consequence of their ease and effectivity of use and conceptual simplicity. They solely require monolingual phrase embeddings educated in every language after which merely be taught a linear projection that maps between the embedding areas. The overall framework may be seen within the Determine under.
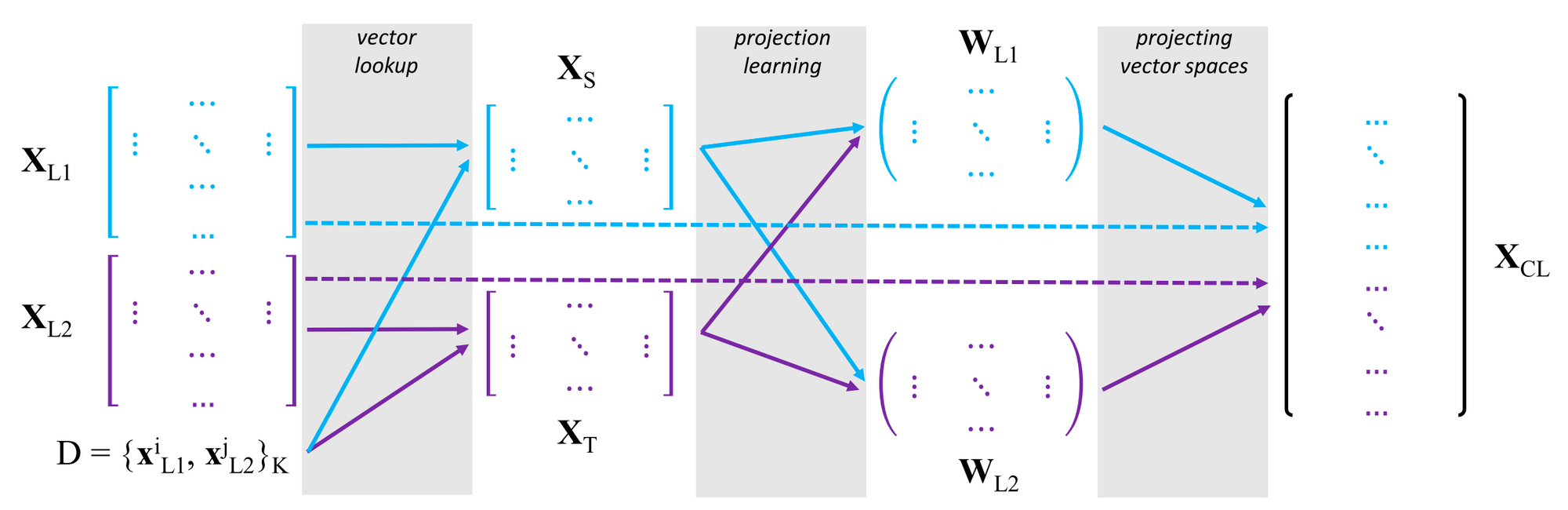
Given monolingual embedding areas (mathbf{X}_{L_1} = {mathbf{x}^i_{L_1} }^{|V_{L_1}|}_{i=1} ) and (mathbf{X}_{L_2} = {mathbf{x}^j_{L_2} }^{|V_{L_2}|}_{j=1} ) in two languages the place (mathbf{x}) is a phrase embedding and (|V|) is the dimensions of the vocabulary, we carry out the next steps (Glavaš et al., 2019):
- Assemble a seed translation dictionary. The dictionary (D = {w^i_{L_1}, w^j_{L_2} }^Okay) accommodates (Okay) pairs of phrases and their translations.
- Create word-aligned monolingual subspaces. We create subspaces (mathbf{X}_S = {mathbf{x}i_{L_1}}K_{i=1} ) and (mathbf{X}_T = {mathbf{x}j_{L_2}}K_{j=1} ) the place (mathbf{X}_S in mathbb{R}^{Okay occasions d}) and (mathbf{X}_T in mathbb{R}^{Okay occasions d}) the place (d) is the dimensionality of the phrase embeddings. We do that just by trying up the vectors of the phrases and their translations within the monolingual embedding areas, ( {w^i_{L_1} } ) from (mathbf{X}_{L_1}) and ( {w^j_{L_2} } ) from (mathbf{X}_{L_2}) respectively.
- Be taught a mapping between the subspaces to a standard area. Particularly, we mission the matrices (mathbf{X}_S) and (mathbf{X}_T) into a standard area (mathbf{X}_{CL}). Within the common setting, we be taught two projection matrices (mathbf{W}_{L_1} in mathbb{R}^{d occasions d} ) and (mathbf{W}_{L_2} in mathbb{R}^{d occasions d}) to mission (mathbf{X}_{L_1}) and (mathbf{X}_{L_2}) respectively to the shared area.
We frequently deal with one of many monolingual areas (mathbf{X}_{L_1}) (sometimes the English area) because the cross-lingual area (mathbf{X}_{CL}) and solely be taught a mapping (mathbf{W}_{L_2}) from (mathbf{X}_{L_2}) to this area. The usual method for studying this mapping is to minimise the Euclidean distance between the representations of phrases ( mathbf{X}_T ) and their projected translations ( mathbf{X}_Smathbf{W} ) within the dictionary (D) (Mikolov et al., 2013):
(mathbf{W}_{L_2} = arg min_{mathbf{W}} | mathbf{X}_Smathbf{W} – mathbf{X}_T |_2 )
After having discovered this mapping, we are able to now mission a phrase embedding (mathbf{x}_{L_2}) from (mathbf{X}_{L_2}) merely as (mathbf{W}_{L_2} mathbf{x}_{L_2} ) to the area of ( mathbf{X}_{L_1}). We are able to see how this mapping appears to be like like geometrically under.
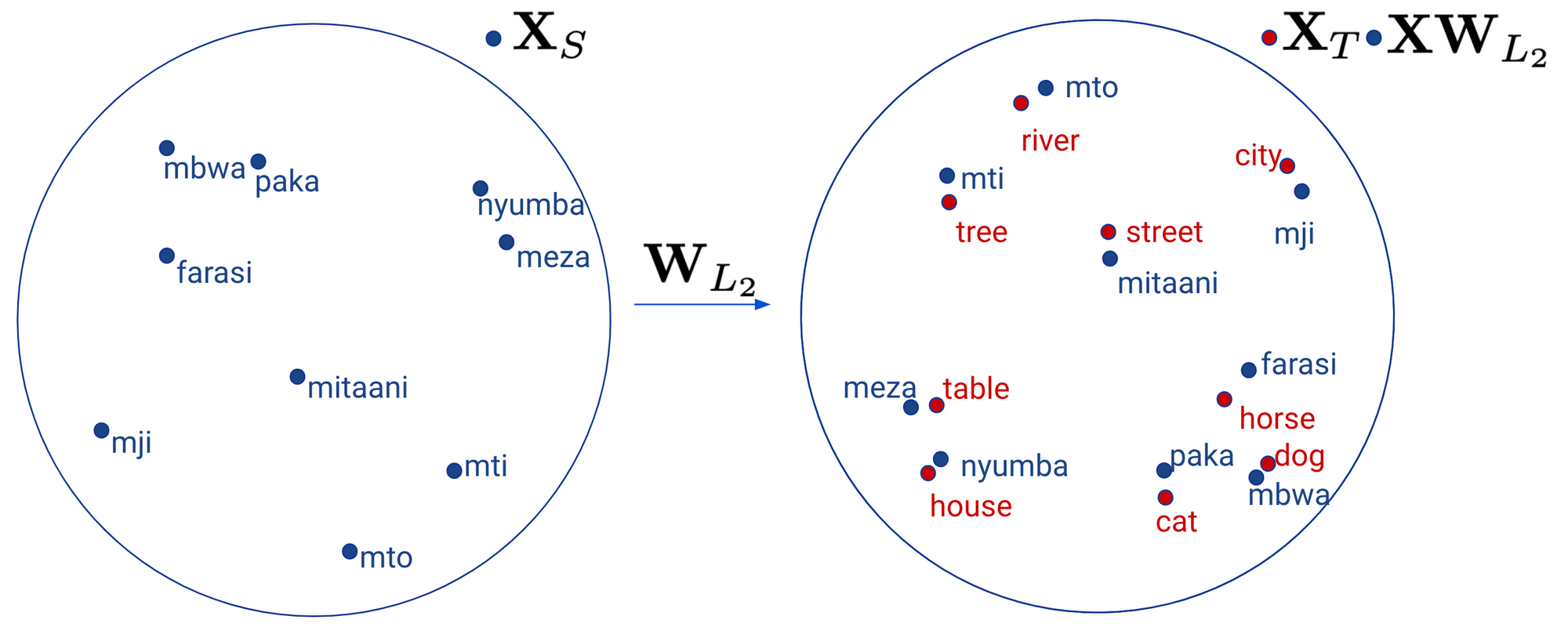
Extra advanced mappings (reminiscent of with a deep neural community) have been noticed to result in poorer efficiency (Mikolov et al., 2013). Higher phrase translation outcomes may be achieved when (mathbf{W}_{L_2}) is constrained to be orthogonal (Xing et al., 2015, Artetxe et al., 2016). Intuitively, this ensures that when (mathbf{W}_{L_2}) vectors are projected to the (mathbf{X}_{CL}) area that the construction of the monolingual embedding area is preserved. If (mathbf{W}_{L_2}) is orthogonal, then the optimisation drawback is called the so-called Procrustes drawback (Schönemann, 1966), which has a closed type resolution:
(
start{align}
start{break up}
mathbf{W}_{L_2} & = mathbf{UV}^high, textual content{with}
mathbf{U Sigma V}^high & = SVD(mathbf{X}_T mathbf{X}_S{}^high)
finish{break up}
finish{align}
)
Nearly all projection-based strategies, whether or not they’re supervised or unsupervised, resolve the Procrustes drawback to be taught a linear mapping in Step 3. The primary half the place they differ is in how they acquire the preliminary seed dictionary in Step 1. Latest supervised approaches (Artetxe et al., 2017) have been proven to realize cheap efficiency utilizing dictionaries of solely 25-40 translation pairs. The primary thought that allows studying from such restricted supervision is bootstrapping or self-learning.
Ranging from a seed dictionary, latest approaches make use of a self-learning process (Artetxe et al., 2017), which may be seen under.
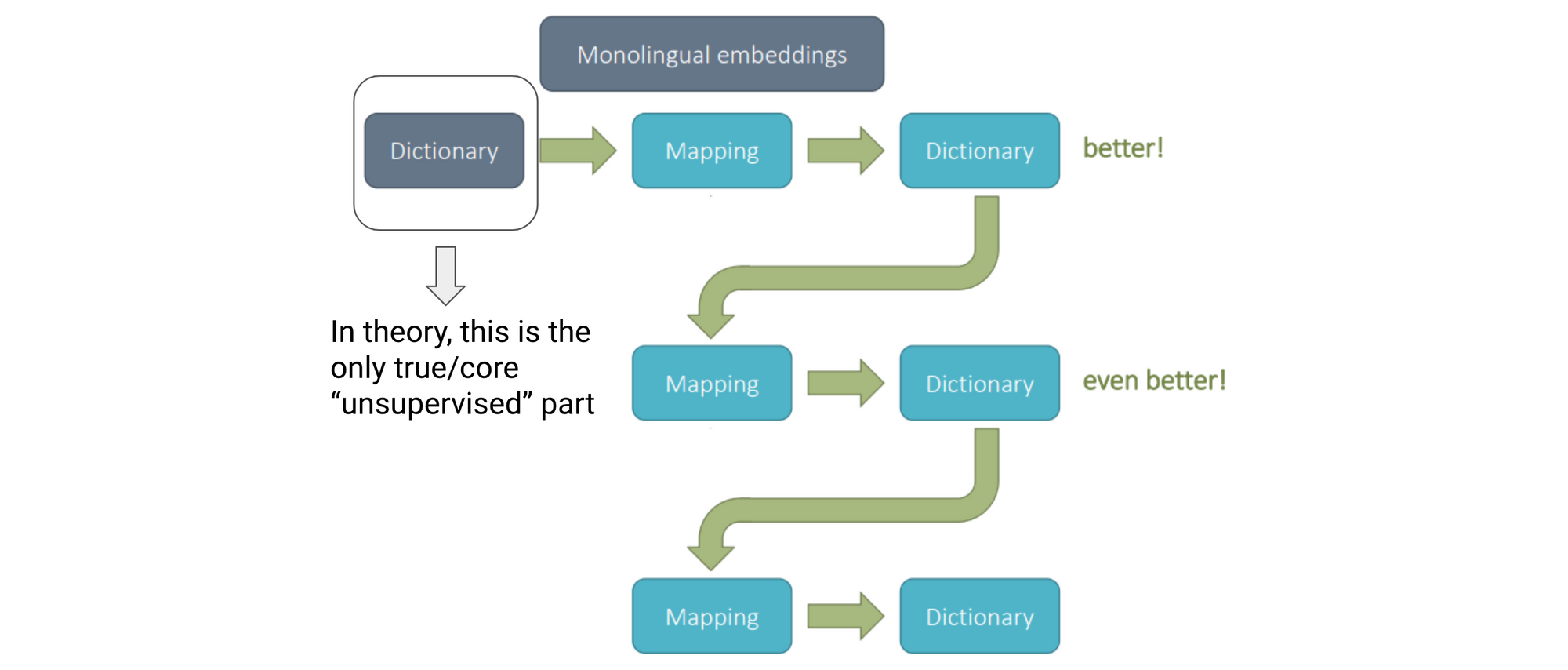
We be taught an preliminary mapping primarily based on the seed dictionary and use this mapping to mission (mathbf{X}_{L_2}) vectors to the goal area (mathbf{X}_{CL}). On this cross-lingual area, (L_1) phrases must be near their translations in (L_2). We are able to now use the (L_1) phrases and their nearest neighbours in (L_2) to construct our new dictionary. In observe, individuals usually solely think about frequent phrases and mutual nearest neighbours, i.e. phrases which are nearest neighbours from each (L_1) and (L_2) instructions (Vulić et al., 2016; Lample et al., 2018).
The framework that’s sometimes utilized in observe consists of further parts (Artetxe et al., 2018) that may be seen within the Determine under.
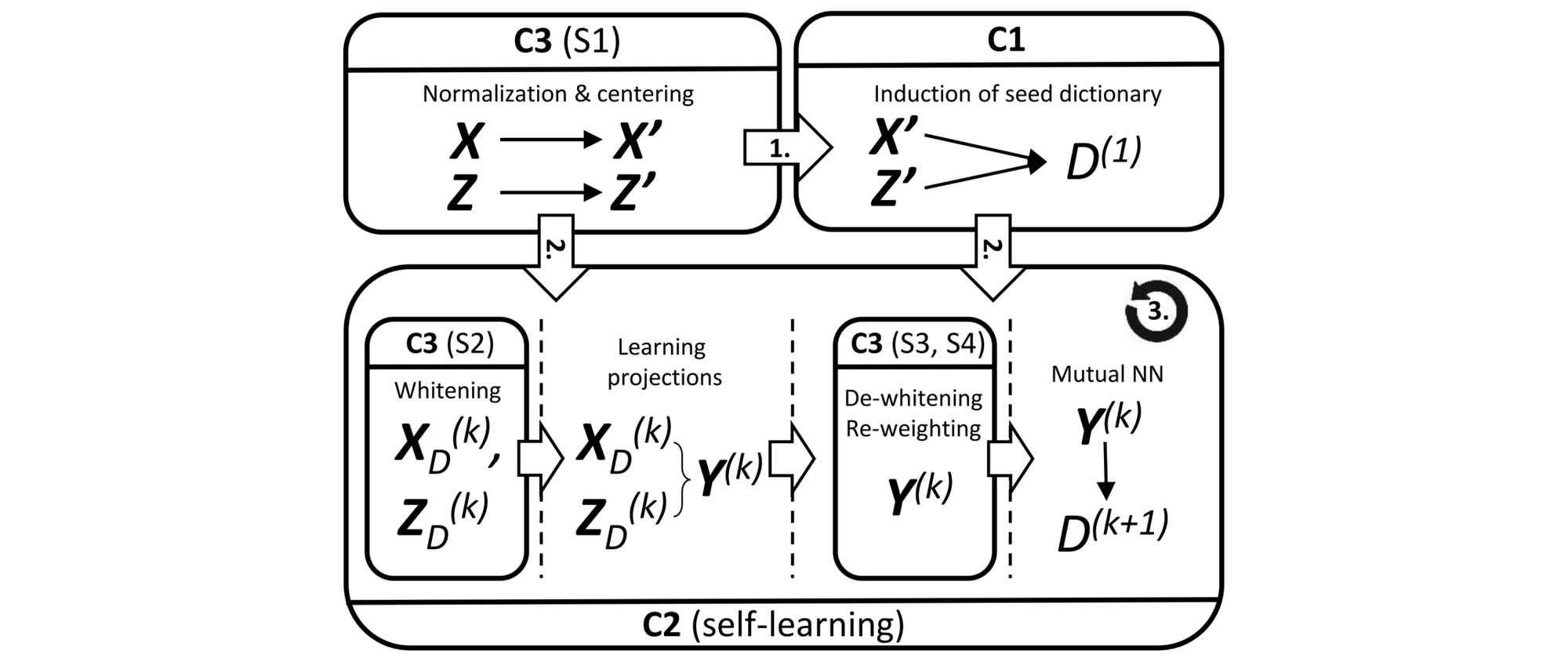
Particularly, past the induction of the preliminary seed dictionary (C1), the educational of the projections, and the self-learning (C3), there are a number of pre- and post-processing steps which are usually utilized in observe. You possibly can take a look at the slides or confer with Artetxe et al. (2018) for an outline.
Unsupervised seed induction goals to discover a good preliminary dictionary that we are able to use to bootstrap the self-learning loop. We are able to differentiate approaches primarily based on whether or not they be taught an preliminary mapping by minimising the gap between the (mathbf{X}_{L_1}) or (mathbf{X}_{L_2}) areas—usually with an adversarial element—or whether or not they depend on a non-adversarial method.
Adversarial approaches
Adversarial approaches are impressed by generative adversarial networks (GANs). The generator is parameterised by our projection matrix (mathbf{W}_{L_2}) whereas the discriminator is a separate neural community that tries to discriminate between true embeddings from (mathbf{X}_{L_2}) and projected embeddings (mathbf{W}_{L_1} mathbf{X}_{L_1}) as may be seen under.
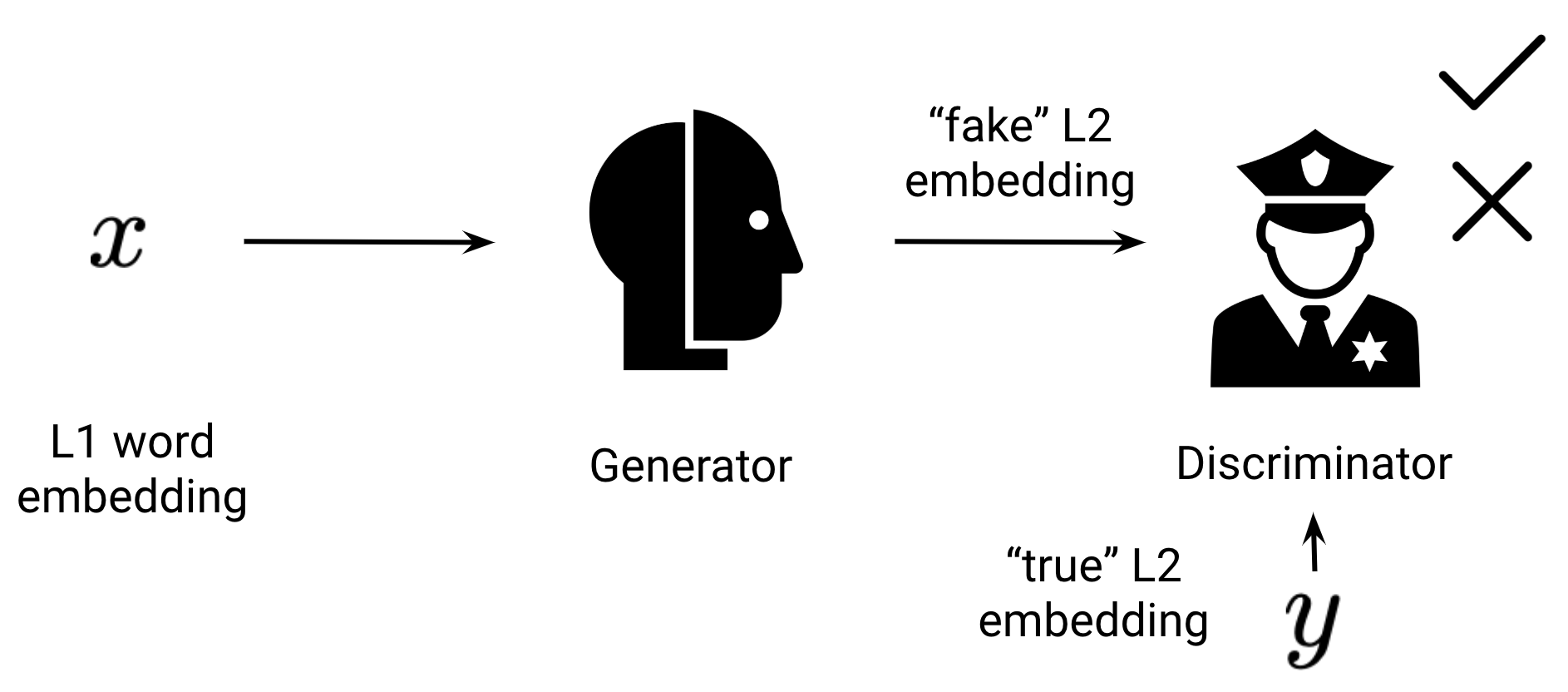
With a purpose to idiot the discriminator, the generator has to rework (mathbf{X}_{L_1}) in such a manner that it matches the distribution of (mathbf{X}_{L_2}). The underlying speculation is that the transformation that makes the distributions as comparable as attainable additionally places phrases near their translations within the cross-lingual area (mathbf{X}_{CL}). GANs may be notoriously brittle. The primary method that labored extra robustly in sure settings was proposed by Conneau et al. (2018).
Different methods have been proposed to minimise the gap between the distributions of (mathbf{X}_{L_1}) and (mathbf{X}_{L_2}) that leverage Wasserstein GANs, Earth Mover’s distance, and optimum transport. For extra particulars about these approaches and their connections, take a look at the corresponding slides.
Weak supervision and second-order similarity
One other technique for acquiring a seed lexicon is thru using heuristics. If the writing methods of two languages share the identical alphabet, then there can be many phrases which are spelled the identical in each languages, lots of them named entities reminiscent of “New York” and “Barack Obama”. A listing of pairs of such identically spelled phrases can be utilized as a weakly supervised seed dictionary (Søgaard et al., 2018). Even when languages don’t share alphabets, many languages nonetheless use Arabic numerals, which can be utilized as a seed dictionary (Artetxe et al., 2017).
Such a weakly supervised seed dictionary is out there for many language pairs and works surprisingly nicely, usually outperforming purely unsupervised approaches. Intuitively, regardless of being noisy, a dictionary consisting of identically spelled phrases supplies a enough variety of anchor factors for studying an preliminary mapping.
Nonetheless, it could be helpful to have a seed dictionary that’s impartial of a language’s writing system. Slightly than requiring that translations must be comparable (e.g. spelled the identical), we are able to go one step additional and require that translations must be just like different phrases throughout languages in the identical manner (Artetxe et al. 2018). In different phrases, the similarity distributions of translations inside every language must be comparable.
Particularly, if we calculate the cosine similarity of 1 phrase with all different phrases in the identical language, type the values, and normalise, we acquire the next distributions for “two”, “due” and “cane”:
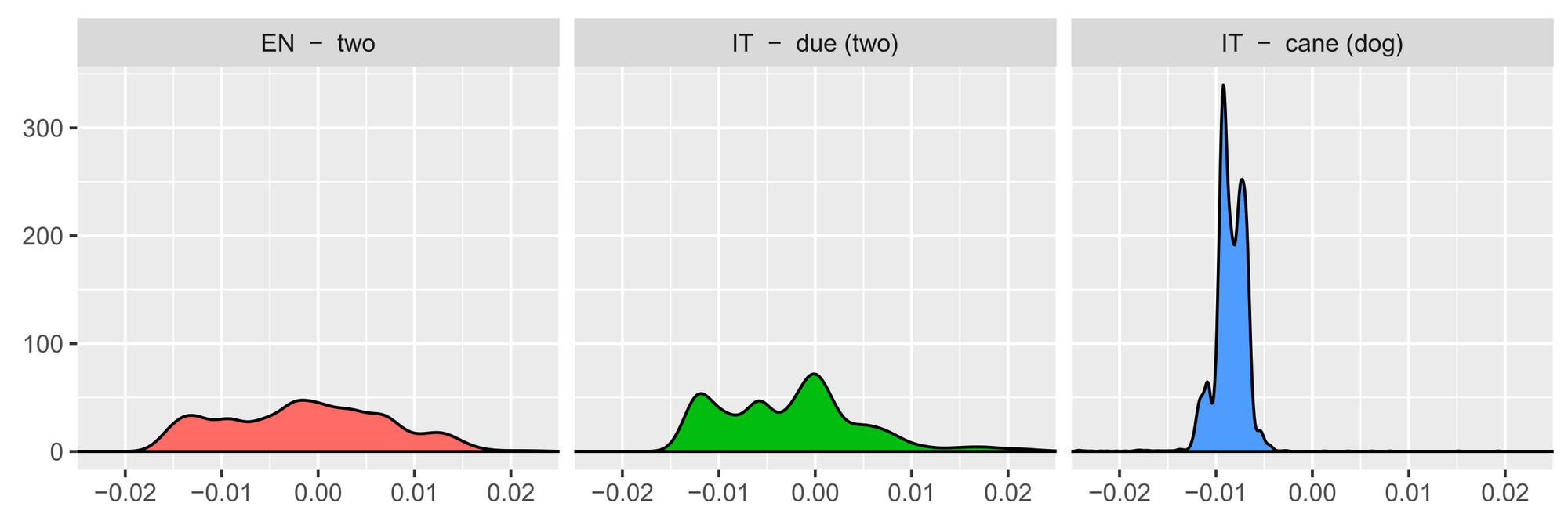
The intralingual similarity distributions of translations reminiscent of “two” and “due” must be extra comparable in comparison with different phrases reminiscent of “cane”. Based mostly on this perception, we are able to use the closest neighbours of our similarity distributions throughout languages because the preliminary dictionary. This notion of second-order similarity (the similarity of similarity distributions) is a robust idea and can also be leveraged by distance metrics such because the Gromov-Wasserstein distance.
Unsupervised cross-lingual phrase embeddings are theoretically fascinating. They will educate us the best way to higher leverage monolingual knowledge throughout languages. We are able to additionally use them to be taught extra about how totally different languages relate to one another.
Nevertheless, supervision within the type of translation pairs is out there for a lot of languages and weak supervision is available. Unsupervised strategies are thus solely of sensible curiosity if they’re able to outperform to their supervised counterparts.
Preliminary papers claimed that unsupervised strategies are certainly aggressive and even outperform the essential supervised Procrustes technique. Latest research, nevertheless, management for the further parts within the framework and evaluate unsupervised and supervised strategies on equal footing. The image that has emerged is that present unsupervised strategies usually underperform supervised strategies with 500-1,000 seed translation pairs (Glavaš et al., 2019; Vulić et al., 2019) as may be seen within the Determine under.
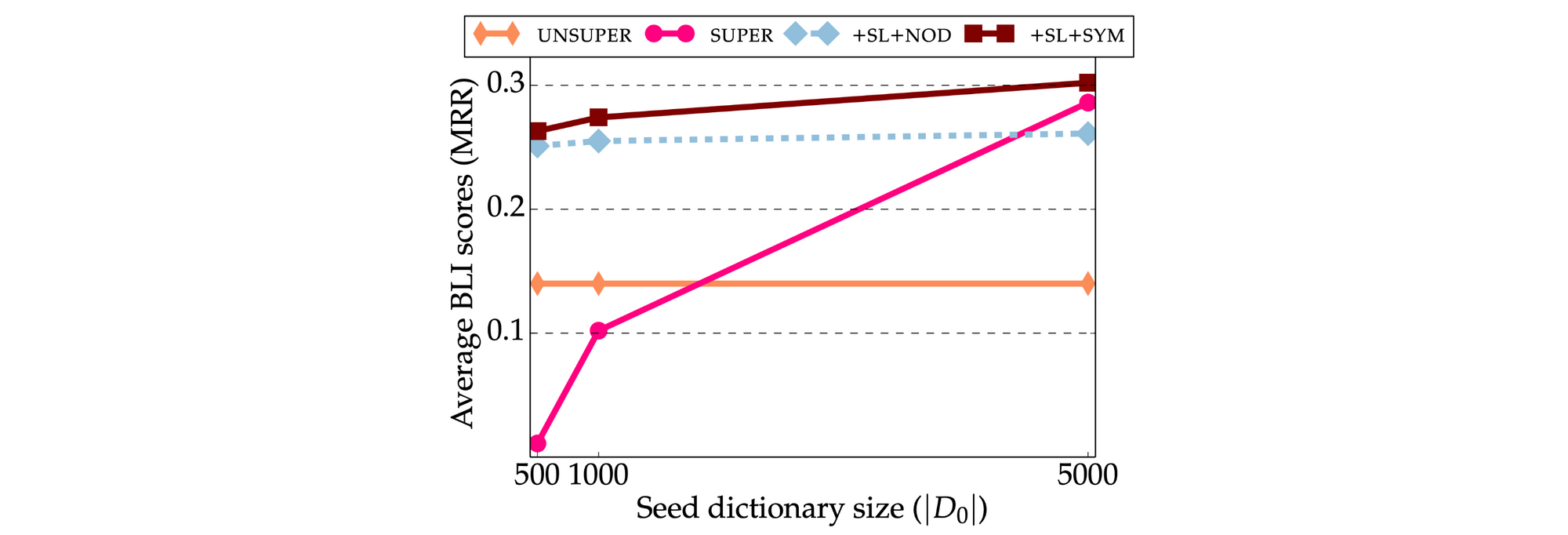
Furthermore, even probably the most strong unsupervised mapping-based approaches fail for a lot of language pairs. This has to do with the topology of the monolingual embedding areas: Unsupervised strategies depend on the idea that the embedding areas are roughly isomorphic, i.e. that they’ve comparable construction (Søgaard et al., 2018). If this isn’t the case, then the unsupervised seed induction step fails.
The construction of embedding areas may be totally different if embeddings belong to dissimilar languages but in addition in the event that they had been educated on totally different domains or utilizing totally different algorithms (Søgaard et al., 2018; Hartmann et al., 2018). Completely different strategies reminiscent of a mixture of a number of impartial linear maps (Nakashole, 2018), iterative normalisation (Zhang et al., 2019), or incrementally including new languages to the multilingual area (Heymann et al., 2019) have been proposed to align such non-isomorphic embedding areas. Latest work has additionally proven that—controlling for added parts—the usual GAN method is aggressive with extra superior GANs reminiscent of Wasserstein GAN and with the second-order similarity initialisation (Hartmann et al., 2019).
Supervised deep fashions that be taught from parallel sentences or paperwork have been proposed earlier than (see Sections 7 and eight of this survey). In gentle of the success of pretrained language fashions, comparable strategies have not too long ago been utilized to coach unsupervised deep cross-lingual representations.
Joint fashions
Probably the most outstanding instance on this line of labor is multilingual BERT (mBERT), a BERT-base mannequin that was collectively educated on the corpora of 104 languages with a shared vocabulary of 110k subword tokens.
mBERT is educated utilizing masked language modelling (MLM)—with no express supervision—however has nonetheless been proven to be taught cross-lingual representations that generalise surprisingly nicely to different languages through zero-shot switch (Pires et al., 2019; Wu & Dredze, 2019). This generalisation capability has been attributed to 3 elements: 1) an identical subwords within the shared vocabulary appearing as anchor factors for studying an alignment (just like the weak supervision of CLWEs); 2) joint coaching throughout a number of languages that spreads this impact; and three) deep cross-lingual representations that transcend vocabulary memorisation and generalise throughout languages.
Latest work (Artetxe et al., 2019; Nameless et al., 2019; Wu et al., 2019), nevertheless, reveals {that a} shared vocabulary is just not required for studying unsupervised deep cross-lingual representations. Artetxe et al. (2019) moreover show that joint coaching is pointless and determine the vocabulary measurement per language as an vital issue: Multilingual fashions with bigger vocabulary sizes constantly carry out higher.
Extensions to mBERT increase it with a supervised goal (Lample and Conneau, 2019), which is impressed by bilingual skip-gram approaches and may be seen within the Determine under. Others add auxiliary pre-training duties reminiscent of cross-lingual phrase restoration and paraphrase detection (Huang et al., 2019), encourage representations of translations to be comparable (Nameless, 2019), and scale it up (Conneau et al., 2019). Joint coaching has been utilized not solely to Transformers but in addition to LSTM-based strategies the place initialisation with CLWEs has been discovered helpful (Mulcaire et al., 2019).
Mapping-based approaches
The mapping-based approaches that we mentioned beforehand have additionally been utilized to the contextual representations of deep bilingual fashions. The primary assumption behind these strategies is that contextual representations—just like their non-contextual counterparts—can be aligned through a linear transformation. As may be seen within the Determine under, contextual representations cluster and have comparable distributions throughout languages.
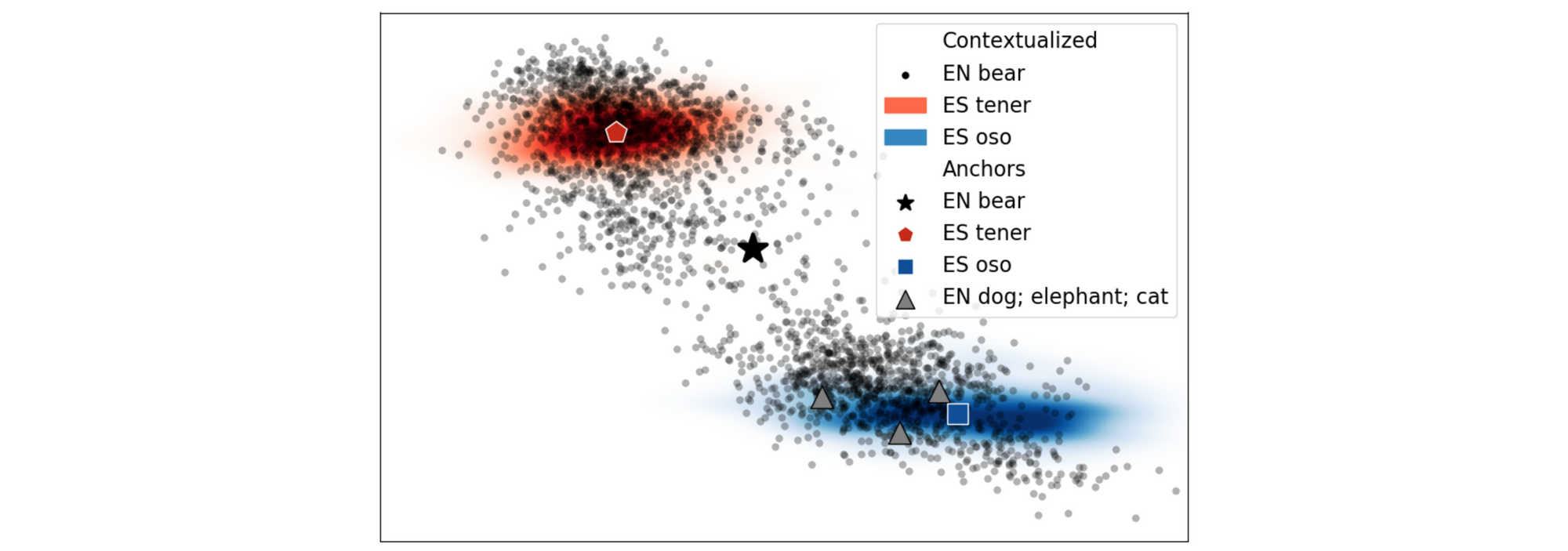
For contextual representations, the mapping may be achieved both on the token stage or on the sort stage. On the token stage, contextual representations of tokens in each languages may be aligned utilizing phrase alignment info in parallel knowledge (Aldarmaki & Diab, 2019). On the sort stage, an combination illustration of a phrase’s contextual representations reminiscent of its imply can be utilized as its kind embeddings (Schuster et al., 2019). Kind embeddings throughout languages can then be aligned utilizing the identical mapping-based approaches as earlier than. Liu et al. (2019) carry out additional analyses and discover that type-level alignment performs finest. Mapping-based strategies have additionally not too long ago been utilized to BERT-based representations (Nameless et al., 2019; Wu et al., 2019).
Slightly than studying a mapping between two current pretrained fashions in (L_1) and (L_2), we are able to apply a mannequin that was pretrained in a high-resource language (L_1) to a low-resource language (L_2) way more simply by merely studying token-level embeddings in (L_2) whereas protecting the mannequin physique fastened (Artetxe et al., 2019, Nameless et al., 2019). The total course of may be seen under. This alignment to a monolingual mannequin might keep away from the non-isomorphism of fastened monolingual vector areas and the ensuing mannequin is aggressive with collectively educated fashions.
Benchmarks
An ordinary activity for evaluating CLWEs is bilingual lexicon induction (BLI), which evaluates the standard of the cross-lingual embedding area by figuring out whether or not phrases are nearest neighbours of their translations in a take a look at dictionary. Not too long ago, a number of researchers have recognized points with the usual MUSE dictionaries (Conneau et al., 2018) for this activity, which solely characterize frequent phrases and usually are not morphologically various (Czarnowska et al., 2019; Kementchedjhieva et al., 2019). BLI efficiency on phrases with decrease frequency ranks drops off drastically as may be seen under.
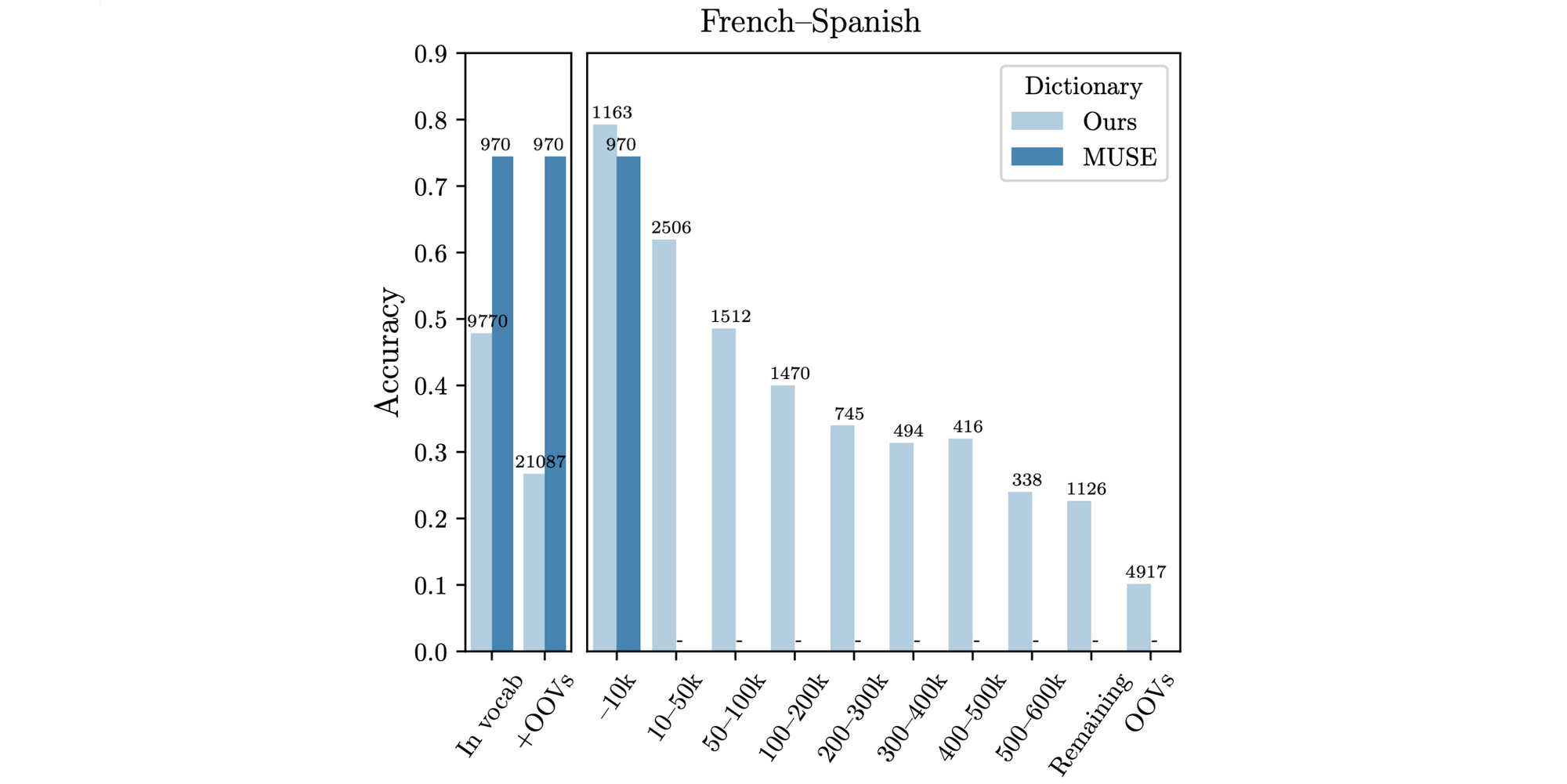
We’re finally taken with making use of our strategies to downstream duties in low-resource languages. Whereas BLI correlates nicely with sure downstream duties for mapping-based approaches (Glavaš et al., 2019), the correlation is weaker for strategies that aren’t primarily based on an orthogonal transformation. Downstream analysis is thus vital to precisely gauge the efficiency of novel strategies sooner or later.
Nevertheless, even current cross-lingual downstream duties have their issues. Cross-lingual doc classification, a traditional activity for the analysis of cross-lingual representations (Klementiev et al., 2012), largely requires superficial keyword-matching and CLWEs outperform deep representations (Artetxe et al., 2019). A more moderen multilingual benchmark, XNLI (Conneau et al., 2018) could also be tormented by comparable artefacts because the MultiNLI dataset from which it has been derived (Gururangan et al., 2018).
On the entire, we want more difficult benchmarks for evaluating multilingual fashions. Query answering is perhaps an excellent candidate as it’s a widespread probe for language understanding and has been proven to be tougher to take advantage of. Not too long ago, a number of cross-lingual query answering datasets have been proposed, together with XQuAD (Artetxe et al., 2019), which extends SQuAD 1.1. to 10 different languages, the open-domain XQA (Liu et al., 2019), and MLQA (Lewis et al., 2019).
Understanding representations
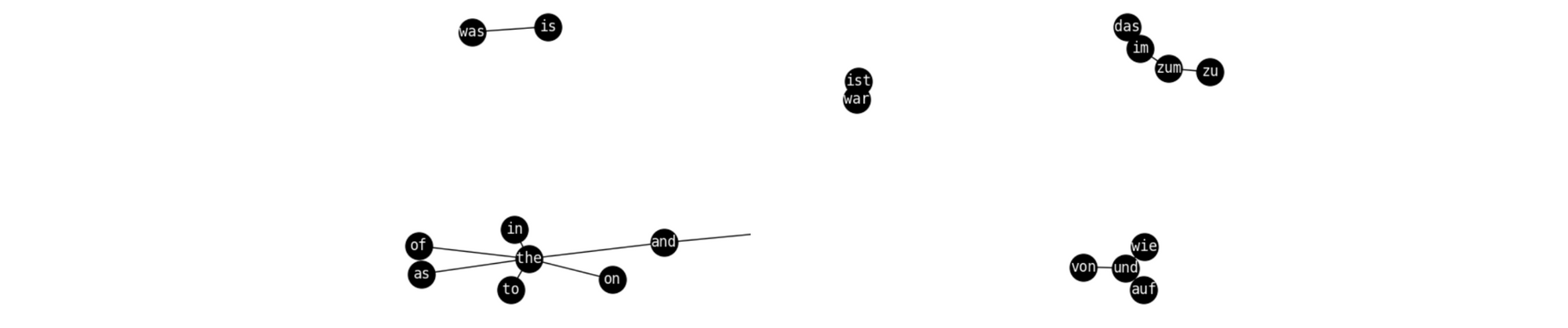
Benchmarks are additionally vital for higher understanding the representations that our fashions be taught. Alongside these traces, it’s nonetheless unclear what makes monolingual embedding areas non-isomorphic. Even embedding areas between comparable languages usually are not strictly isomorphic as may be seen under. Related points would possibly have an effect on the areas of deep contextual representations. Figuring out the reason for this phenomenon might assist us acquire a greater understanding of our studying algorithms and the biases they encode of their representations. It might additionally make clear the semantic similarities and variations between languages.
There have been a number of research analysing what CLWEs be taught however it’s nonetheless largely unclear what representations discovered by unsupervised deep multilingual fashions seize. As token-level alignment to a deep monolingual mannequin achieves aggressive outcomes (Artetxe et al., 2019), deep multilingual fashions should largely be taught lexical alignment. If that is so, we want higher strategies that incentivise studying deep multilingual representations. Parallel knowledge improves efficiency in observe (Lample & Conneau, 2019), however for low-resource languages we wish to use as little supervision as attainable.
Deep representations from an English BERT mannequin may be transferred to a different language with none modification (apart from studying new token embeddings; Artetxe et al., 2019). Consequently, it must be fascinating to analyse what cross-lingual info monolingual fashions seize. With a purpose to acquire new insights, nevertheless, we want higher benchmarks and analysis protocols for the evaluation of cross-lingual information.
Sensible issues
Ultimately, we might wish to be taught cross-lingual representations with the intention to apply them to downstream duties in low-resource languages. In gentle of this, we should always not overlook sensible issues of such low-resource situations. Whereas zero-shot switch is a spotlight of present strategies, zero-shot switch is just not free. It requires entry to coaching knowledge from the identical activity and distribution in a high-resource language. We should always thus proceed investing in approaches that may be educated with few samples in a goal language and that mix the very best of each the monolingual and cross-lingual worlds, as an example through cross-lingual bootstrapping that may be seen under (Eisenschlos et al., 2019).
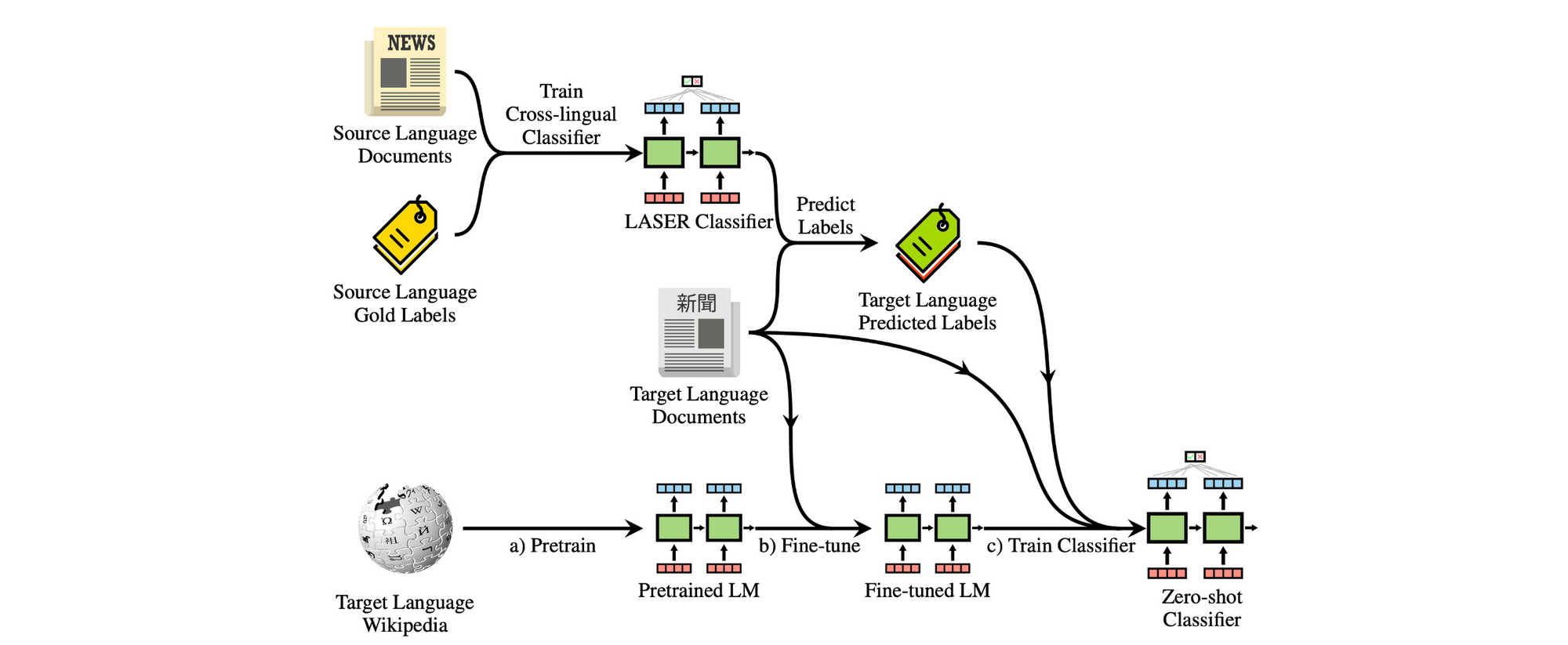
As well as, latest deep multilingual fashions are giant and costly to coach. Coaching smaller multilingual fashions, as an example through distillation (Tsai et al., 2019), can be key for deployment in resource-constrained situations.
Latest wide-coverage parallel corpora reminiscent of JW-300 (Agić & Vulić, 2019) and WikiMatrix (Schwenk et al., 2019) allow the coaching of massively multilingual or supervised methods for a lot of new low-resource languages the place parallel knowledge was beforehand not out there. Nevertheless, these sources nonetheless don’t cowl languages the place solely few unlabelled knowledge is out there. With a purpose to apply our strategies to duties in such languages, we have to develop approaches that may be taught representations from a restricted variety of samples. Sources that present restricted knowledge (largely dictionaries) for numerous languages are the ASJP database, PanLex, and BabelNet.
Lastly, whereas CLWEs underperform deep multilingual fashions on more difficult benchmarks (Artetxe et al., 2019), they’re nonetheless most well-liked for simpler duties reminiscent of doc classification as a consequence of their effectivity and ease of use. As well as, they function a helpful initialisation to kick-start the coaching of deep fashions (Mulcaire et al., 2019; Nameless et al., 2019) and of unsupervised NMT fashions (Artetxe et al., 2019). Consequently, they could be a helpful basis for the event of extra useful resource and parameter-efficient deep multilingual fashions.
Quotation
In case you discovered this submit useful, think about citing the tutorial as:
@inproceedings{ruder2019unsupervised,
title={Unsupervised Cross-Lingual Illustration Studying},
writer={Ruder, Sebastian and S{o}gaard, Anders and Vuli{'c}, Ivan},
booktitle={Proceedings of ACL 2019, Tutorial Abstracts},
pages={31--38},
12 months={2019}
}
{kind=link}