Fashions that enable interplay by way of pure language have develop into ubiquitious. Analysis fashions reminiscent of BERT and T5 have develop into rather more accessible whereas the most recent technology of language and multi-modal fashions are demonstrating more and more highly effective capabilities. On the similar time, a wave of NLP startups has began to place this expertise to sensible use.
Whereas such language expertise could also be vastly impactful, latest fashions have largely targeted on English and a handful of different languages with giant quantities of assets. Growing fashions that work for extra languages is essential to be able to offset the present language divide and to make sure that audio system of non-English languages will not be left behind, amongst many different causes.
This submit takes a better take a look at how the AI neighborhood is faring on this endeavour. I might be specializing in matters associated to pure language processing (NLP) and African languages as these are the domains I’m most accustomed to. I’ve tried to cowl as many contributions as potential however undoubtedly missed related work. Be happy to depart a remark or attain out with a pointer to something I missed.
This submit is partially based mostly on a keynote I gave on the Deep Studying Indaba 2022. It covers the next high-level matters:
Standing Quo
There are round 7,000 languages spoken world wide. Round 400 languages have greater than 1M audio system and round 1,200 languages have greater than 100k . Bender highlighted the necessity for language independence in 2011. Reviewing papers printed at ACL 2008, she discovered that 63% of all papers targeted on English. For a latest examine , we equally reviewed papers from ACL 2021 and located that nearly 70% of papers solely consider on English. 10 years on, little thus appears to have modified.
Many languages in Africa, Asia, and the Americas which are spoken by tens of tens of millions of individuals have acquired little analysis consideration . Continents reminiscent of Africa with round 2,000 languages or particular person international locations reminiscent of Indonesia with round 700 languages are extremely linguistically various and on the similar time dramatically underserved by present analysis and expertise.
Past particular person languages, researchers with affiliations in international locations the place such languages are spoken are equally under-represented in each ML and NLP communities. As an illustration, whereas we will observe a slight upward pattern within the variety of authors affiliated with African universities publishing at high machine studying (ML) and NLP venues, this improve pales in comparison with the hundreds of authors from different areas publishing in such venues yearly.

Present state-of-the-art fashions in lots of ML domains are primarily based mostly on two components: 1) giant, scalable architectures (typically based mostly on the Transformer ) and a pair of) switch studying. Given the final nature of those fashions, they are often utilized to numerous kinds of information together with photographs , video , and audio . A few of the most profitable fashions in latest NLP are BERT , RoBERTa , BART , T5 , and DeBERTa , which have been educated on billions of tokens of on-line textual content utilizing variants of masked language modeling in English. In speech, wav2vec 2.0 has been pre-trained on giant quantities of unlabeled speech.
Multilingual fashions These fashions have multilingual analogues—in NLP, fashions reminiscent of mBERT, RemBERT , XLM-RoBERTa , mBART , mT5 , and mDeBERTa —that have been educated similarly, predicting randomly masked tokens on information of round 100 languages. In comparison with their monolingual counterparts, these multilingual fashions require a a lot bigger vocabulary to symbolize tokens in lots of languages.
A variety of elements has been discovered to be essential for studying strong multilingual representations, together with shared tokens , subword fertility , and phrase embedding alignment . In speech, fashions reminiscent of XSLR and UniSpeech are pre-trained on giant quantities of unlabeled information in 53 and 60 languages respectively.
The curse of multilinguality Why do these fashions solely cowl as much as 100 languages? One purpose is the ‘curse of multilinguality’ . Much like fashions which are educated on many duties, the extra languages a mannequin is pre-trained on, the much less mannequin capability is accessible to be taught representations for every language. Growing the dimensions of a mannequin ameliorates this to some extent, enabling the mannequin to dedicate extra capability to every language .
Lack of pre-training information One other limiting issue is the provision of textual content information on the net, which is skewed in the direction of languages spoken in Western international locations and with a big on-line footprint. The languages with probably the most on-line assets out there for pre-training are usually prioritized, resulting in an under-representation of languages with few assets as a consequence of this top-heavy choice. That is regarding as prior research have proven that the quantity of pre-training information in a language correlates with downstream efficiency for some duties . Particularly, languages and scripts that have been by no means seen throughout pre-training typically result in poor efficiency .

High quality points in present multilingual assets Even for languages the place information is accessible, previous work has proven that some generally used multilingual assets have extreme high quality points. Entity names in Wikidata will not be within the native script for a lot of under-represented languages whereas entity spans in WikiAnn , a weakly supervised multilingual named entity recognition dataset based mostly on Wikipedia, are sometimes misguided .
Equally, a number of routinely mined assets and routinely aligned corpora used for machine translation are problematic . As an illustration, 44/65 audited languages in WikiMatrix and 19/20 audited langages in CCAligned include lower than 50% appropriate sentences. General, nevertheless, efficiency appears to be largely constrained by the amount moderately than high quality of information in under-represented languages .
Multilingual analysis outcomes We will get a greater image of the cutting-edge by wanting on the efficiency of latest fashions on a consultant multilingual benchmark reminiscent of XTREME —a multilingual counterpart to GLUE and SuperGLUE —which aggregates efficiency throughout 9 duties and 40 languages. Beginning with the primary multilingual pre-trained fashions two and a half years in the past, efficiency has improved steadily and is slowly approaching human-level efficiency on the benchmark.

Nonetheless, wanting on the common efficiency on such a benchmark obscures which languages a mannequin was really evaluated on. Past a couple of datasets with a big language protection—Common Dependencies , WikiAnn , and Tatoeba —different duties solely cowl few languages, and are once more skewed in the direction of languages with extra assets. Most present benchmarks thus solely present a distorted view of the general progress in the direction of multilingual AI for the world’s languages.
For a extra correct impression, we will take a look at the normalized state-of-the-art efficiency on completely different language expertise duties averaged the world over’s languages both based mostly on their speaker inhabitants (demographic utility) or equally (linguistic utility) .

Most NLP duties fare higher once we common based mostly on speaker inhabitants. General, nevertheless, we observe very low linguistic utility numbers, exhibiting an unequal efficiency distribution the world over’s languages. This conclusion, nevertheless, could also be considerably overly pessimistic because it solely considers languages for which analysis information is presently out there. Cross-lingual efficiency prediction could possibly be used to estimate efficiency for a broader set of languages.
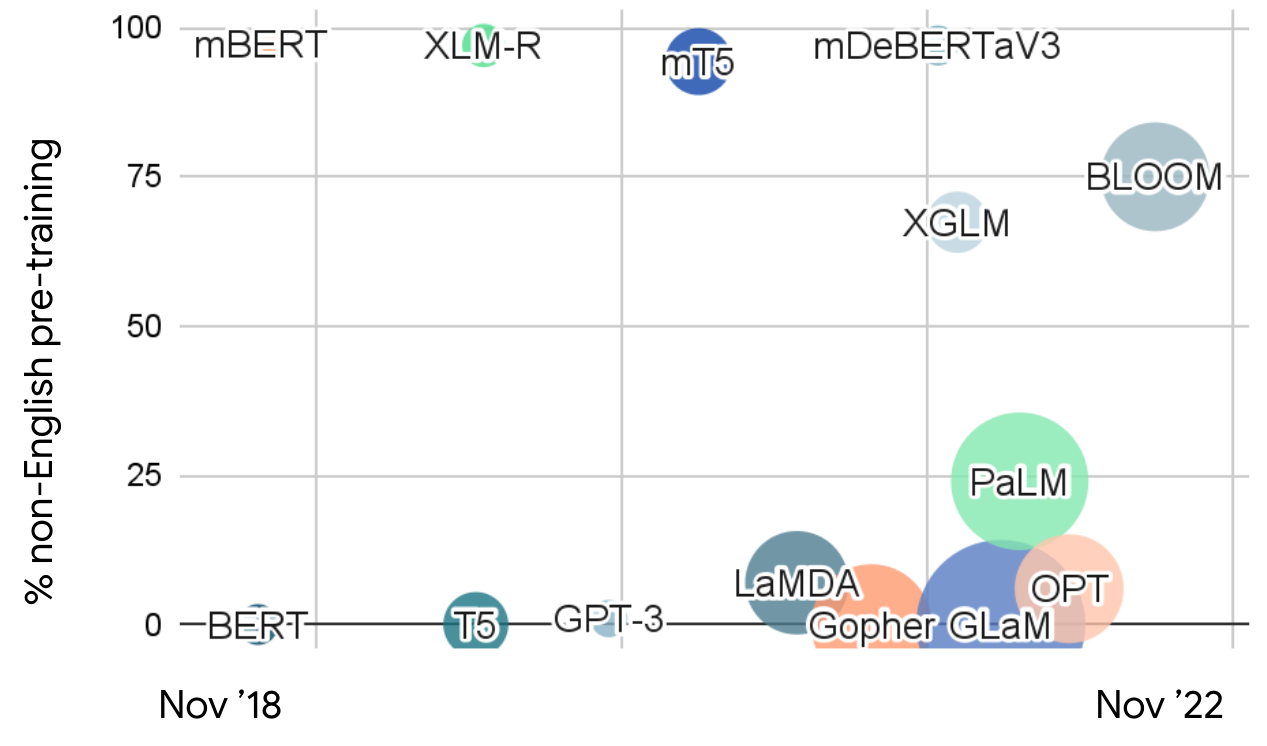
Multilingual vs English-centric fashions Allow us to now take a step again and take a look at latest giant language fashions in NLP basically. We will plot latest fashions based mostly on the fraction of non-English information they’re pre-trained on. Based mostly on this characterization, we will observe two distinct streams of analysis: 1) Multilingual fashions which are educated on multingual information in lots of languages and a pair of) English-centric fashions which are educated on largely English information.

The latter type the muse for the mainstream of NLP analysis and whereas these fashions have been getting bigger, they haven’t been getting rather more multilingual. An exception is BLOOM , the most important multilingual open-source mannequin so far. A few of these giant fashions have demonstrated stunning multilingual capabilities. As an illustration, GPT-3 and PaLM can translate textual content between languages with giant quantities of information. Whereas they’ve been proven to have the ability to carry out multilingual few-shot studying , fashions carry out finest when prompts or enter information are translated to English. Additionally they carry out poorly when translating between non-English language pairs or into languages with restricted information. Whereas PaLM is ready to summarize non-English textual content into English, it struggles when producing textual content in different languages.
Equally, latest speech fashions reminiscent of HuBERT and WavLM and up to date giant imaginative and prescient fashions that generate textual content based mostly on a picture reminiscent of Flamingo or a picture based mostly on textual content reminiscent of DALL-E 2 , Imagen , and Parti are English-centric. Exceptions are Whisper and PaLI , that are pre-trained on giant quantities of weakly supervised information from the online for ASR and picture captioning in 96 and 109 languages respectively. Nonetheless, total, for the most recent technology of enormous fashions, multilinguality stays a side-effect moderately than a key design criterion.
Consumer-facing applied sciences With regard to user-facing applied sciences, keyboards and spell checkers reminiscent of Gboard assist greater than 900+ languages however many languages nonetheless lack assist or audio system could also be unaware {that a} keyboard for his or her language is accessible . Different user-facing applied sciences with broad language protection are machine translation and computerized speech recognition (ASR). Google Translate and speech-to-text, as an example, assist 133 and greater than 125 languages respectively as of the publishing of this submit.
Latest Progress
Latest progress on this space will be categorized into two classes: 1) new teams, communities, assist buildings, and initiatives which have enabled broader work; and a pair of) high-level analysis contributions reminiscent of new datasets and fashions that enable others to construct on them.
Analysis communities There are various languages with energetic present analysis communities devoted to them. These embrace languages with giant speaker populations reminiscent of Japanese, Mandarin, Turkish, and Hindi in addition to languages with fewer audio system reminiscent of Gaelic or Basque . There have additionally been concerted efforts up to now to gather information for particular under-represented languages reminiscent of Inuktitut .
In the previous few years, varied new communities have emerged specializing in under-represented languages or language households. These embrace teams specializing in linguistic areas reminiscent of Masakhane for African languages, AmericasNLP for native American languages, IndoNLP for Indonesian languages, GhanaNLP and HausaNLP, amongst others. Occasions such because the Deep Studying Indaba, IndabaX, Khipu, EEML, SEAMLS, and ALPS, amongst many others and workshops reminiscent of AfricaNLP have enabled these communities to return collectively and complement longer-running occasions such because the Arabic NLP, ComputEL, and SIGTYP workshops.

On the similar time, there are communities with broader focus areas reminiscent of ML Collective which have contributed to this area. One of many largest community-driven efforts in multilingual AI is BigScience, which has launched BLOOM . In lots of circumstances, initiatives in these communities have been participatory and extremely collaborative , reducing the barrier to doing analysis and involving members of the neighborhood at each stage of the method.
Different communities reminiscent of Zindi or Information Science Nigeria have targeted on internet hosting competitions and offering coaching programs whereas new applications such because the African Grasp’s in Machine Intelligence search to coach the following technology of AI researchers.
Initiatives The Affiliation for Computational Linguistics (ACL) has emphasised the significance of language range, with a particular theme observe on the primary ACL 2022 convention on this matter. The ACL has additionally launched the 60-60 initiative, which goals to make scientific content material extra accessible by making a) translations of the whole ACL anthology into 60 languages; b) cross-lingual subtitling and dubbing for all plenary talks in 10 languages; and c) a complete standardized scientific and NLP terminology checklist in 60 languages. The latter useful resource and glossaries for African languages might assist to facilitate the dialogue of language expertise in native languages.
Datasets On the analysis facet, there was a flurry of latest datasets overlaying a number of purposes, from unlabeled speech and textual content corpora , to language identification , textual content classification , sentiment evaluation , ASR, named entity recognition , query answering , and summarization in a spread of under-represented languages. New benchmarks search to evaluate fashions on a broad set of duties in Romanian , Korean , and Turkish , in geographically associated languages reminiscent of Indonesian or Indian languages , and in numerous modalities reminiscent of speech , image-grounded textual content , and textual content technology . The event of those datasets has been enabled by new funding buildings and initiatives such because the Lacuna Fund and FAIR Ahead which have incentivized work on this space.

Different present corpora have grown of their language protection with neighborhood involvement: The Widespread Voice speech corpus now covers 100 languages whereas the most recent launch of Common Dependencies consists of 130 languages. Given the variety of new datasets, there have been efforts to catalogue out there datasets in African and Indonesian languages, Arabic, and a various set of languages .
Fashions New fashions developed on this space focus particularly on under-represented languages. There are text-based language fashions that concentrate on African languages reminiscent of AfriBERTa , AfroXLM-R , and KinyaBERT and fashions for Indonesian languages reminiscent of IndoBERT and IndoGPT . For Indian languages, there are text-based fashions reminiscent of IndicBERT and MuRIL and speech fashions reminiscent of CLSRIL and IndicWav2Vec . Many of those approaches practice a mannequin on a number of associated languages and are thus capable of leverage constructive switch and to be rather more environment friendly than bigger multilingual fashions. See and for latest surveys of latest multilingual fashions in NLP and speech.
Trade In business, startups have been creating new expertise to serve native languages reminiscent of InstaDeep creating a mannequin for Tunisian Arabic , Nokwary enabling monetary inclusion in Ghanaian languages, BarefootLaw using NLP expertise to offer authorized assist in Uganda, and NeuralSpace constructing speech and textual content APIs for a geographically various set of languages, amongst many others.
Equally, giant tech firms have expanded their ASR and machine translation choices. Each Google and Meta have described efforts on easy methods to scale machine translation expertise to the following thousand languages. On the coronary heart of those efforts are a) mining high-quality monolingual information from the online based mostly on improved language identification and filtering; b) coaching massively multilingual fashions on monolingual and parallel information; and c) in depth analysis on newly collected datasets. These elements are equally essential for constructing higher ASR techniques for under-represented languages .
Challenges and Alternatives
Given this latest progress, what are the remaining challenges and alternatives on this space?
Problem #1: Restricted Information
Arguably the largest problem in multilingual analysis is the restricted quantity of information out there for many of the world’s languages. Joshi et al. categorized the languages of the world into six completely different classes based mostly on the quantity of labeled and unlabeled information out there in them.

88% of the world’s languages are in useful resource group 0 with just about no textual content information out there to them whereas 5% of languages are in useful resource group 1 the place there’s very restricted textual content information out there.
Alternative #1: Actual-world Information
How can we overcome this huge discrepancy within the useful resource distribution the world over’s languages? The creation of latest information, notably in languages with few annotators, is dear. For that reason, many present multilingual datasets reminiscent of XNLI , XQuAD , and XCOPA are based mostly on translations of established English datasets.
Such translation-based information, nevertheless, are problematic. Translated textual content in a language will be thought-about a dialect of that language, referred to as ‘translationese’, which differs from pure language . Translation-based check units could thus over-estimate the efficiency of fashions educated on related information, which have discovered to take advantage of translation artifacts .
Over-representation of Western ideas Past these points, translating an present dataset inherits the biases of the unique information. Particularly, translated information differs from information that’s naturally created by audio system of various languages. As present datasets have been largely created by crowdworkers or researchers based mostly in Western international locations, they largely replicate Western-centric ideas. For instance, ImageNet , one of the influential datasets in ML, is predicated on English WordNet. In consequence, it captures ideas which are overly English-specific and unknown in different cultures . Equally, Flickr30k accommodates depictions of ideas which are primarily acquainted to folks from sure Western areas reminiscent of tailgating within the US .

American annotators described the exercise within the picture as tailgating, a North-American pastime the place folks collect to get pleasure from a casual (typically barbecue) meal on the car parking zone exterior a sports activities stadium (van Miltenburg et al., 2017).
The commonsense reasoning dataset COPA accommodates many referents that haven’t any language-specific phrases in some languages, e.g., bowling ball, hamburger, and lottery . Most questions in present QA datasets ask about US or UK nationals whereas many different datasets, notably these based mostly on Wikipedia, include primarily entities from Europe, the US, and the Center East .
Sensible information For brand new datasets, it’s thus ever extra essential to create information that’s knowledgeable by real-world utilization. On the one hand, information ought to replicate the background of the audio system talking the language. For instance, MaRVL is a multi-modal reasoning dataset that covers ideas consultant of various cultures and languages.

Given the growing maturity of language expertise, you will need to accumulate information that’s related for real-world purposes and which will have a constructive affect on audio system of under-represented languages. Such purposes embrace the event of assistive language expertise for humanitarian crises, well being, training, authorized, and finance. Languages which will profit from such expertise are standardised languages and make contact with languages, together with creoles and regional language varieties .
Creating real-world datasets has the potential to floor analysis and allows it to have a bigger affect. It additionally reduces the distribution shift between analysis and sensible situations and makes it extra probably that fashions developed on tutorial datasets might be helpful in manufacturing.
Past the creation of the coaching or analysis information, the event of a language mannequin requires the involvement of a lot of stakeholders, a lot of whom are sometimes not explicitly acknowledged. Most of the elements on this course of are under-performing and infrequently not out there in lots of languages.

This begins in the beginning of information creation the place on-line platforms and keyboards could not assist sure languages , dictionaries don’t cowl sure languages and language ID doesn’t carry out properly in these languages . In lots of languages, the connections between completely different stakeholders are additionally lacking and it’s troublesome to seek out unique content material or to determine certified annotators. The truth that textual content on the net is troublesome to seek out for some languages doesn’t imply, nevertheless, that these languages are resource-poor or that information for these languages doesn’t exist.
Multi-modal information Many languages world wide are extra generally spoken than written. We will overcome the reliance (and lack of) textual content information by specializing in data from multi-modal information sources reminiscent of radio broadcasts and on-line movies in addition to combining data from a number of modalities. Latest speech-and-text fashions obtain sturdy enhancements on speech duties reminiscent of ASR, speech translation, and text-to-speech. They nonetheless carry out extra poorly, nevertheless, on text-only duties as a consequence of a scarcity of capability . There may be quite a lot of potential to leverage multi-modal information in addition to to analyze the linguistic traits of various languages and their interaction in textual content and speech .

Past multi-modal data, information might also be out there in codecs which are locked to present fashions reminiscent of in handwritten paperwork and non-digitized books, amongst others. Applied sciences reminiscent of optical character recognition (OCR) and new datasets such because the Bloom Library will assist us make such untapped information sources extra accessible. There are additionally assets which have to this point been used comparatively little regardless of their giant language protection such because the Bible, which covers round 1,600 languages and lexicons, which cowl round 5,700 languages . Different information sources could also be available however have to this point gone unused or unnoticed. Latest examples of such ‘fortuitous information’ embrace HTML and internet web page construction , amongst others.
Given the generalization potential of pre-trained language fashions, benchmarks have been more and more shifting in the direction of analysis in low-resource settings. When creating new datasets, giant check units with ample statistical energy ought to thus be prioritized. As well as, languages for annotation will be prioritized based mostly on the anticipated acquire in utility and discount in inequality .
Lastly, there are challenges for accountable AI when amassing information and creating expertise for under-represented languages, together with information governance, security, privateness, and participation. Addressing these challenges requires answering questions reminiscent of: How are acceptable utilization and possession of the info and expertise assured ? Are there strategies in place to detect and filter delicate and biased information and detect bias in fashions? How is privateness preserved throughout information assortment and utilization? How can the info and expertise improvement be made participatory ?
Problem #2: Restricted Compute
Beneath-represented language purposes face constraints that transcend the shortage of information. Cell information, compute, and different computational assets could typically be costly or unavailable. GPU servers, as an example, are scarce even in high universities in lots of international locations whereas the price of cell information is larger in international locations the place under-represented languages are spoken .
Alternative #2: Effectivity
As a way to make higher use of restricted compute, we should develop strategies which are extra environment friendly. For an outline of environment friendly Transformer architectures and environment friendly NLP strategies basically confer with and . As pre-trained fashions are extensively out there, a promising path is the difference of such fashions by way of parameter-efficient strategies, which have been proven to be more practical than in-context studying .
A typical technique are adapters , small bottleneck layers which are inserted between a pre-trained mannequin’s weights. These parameter-efficient strategies can be utilized to beat the curse of multilinguality by enabling the allocation of extra language-specific capability. Additionally they allow the difference of a pre-trained multilingual mannequin to languages that it has not been uncovered to throughout pre-training . As such adapter layers are separate from the remaining parameters of the mannequin, they permit studying modular interactions between duties and languages .

Adapters have been proven to enhance robustness , result in elevated pattern effectivity in comparison with fine-tuning , and outperform different parameter-efficient strategies . They permit for extensions reminiscent of incorporating hierarchical construction or conditioning by way of hyper-networks .
Cross-lingual parameter-efficient switch studying is just not restricted to adapters however can take different kinds reminiscent of sparse sub-networks . Such strategies have been utilized to a various set of purposes and domains, from machine translation to ASR and speech translation .
Problem #3: Language Typology
If we plot the typological options of the world’s languages based mostly on the World Atlas of Language Constructions (WALS) and venture them into two dimensions utilizing PCA, we get a density plot such because the one beneath. Marking the languages which are current in Common Dependencies , one of the multilingual assets with crimson stars, we will observe that the languages for which information is accessible lie largely in low-density areas of this plot. The distribution of languages in present datasets is thus closely skewed in comparison with the real-world distribution of languages and languages with out there information are unrepresentative of many of the world’s languages.

Beneath-represented languages have many linguistic options that aren’t current in Western languages. A typical linguistic characteristic is tone, which is current in round 80% of African languages and will be lexical or gramatical. In Yorùbá, lexical tone distinguishes that means, as an example, within the following phrases: igbá (“calabash”, “basket”), igba (“200”), ìgbà (“time”), ìgbá (“backyard egg”), and igbà (“rope”). In Akan, grammatical tone distinguishes routine and stative verbs reminiscent of for Ama dá ha (“Ama sleeps right here”) and Ama dà ha (“Ama is sleeping right here”). Tone is comparatively unexplored in speech and NLP purposes.
Whereas the typological options of languages world wide are various, languages inside a area typically share linguistic options. As an illustration, African languages primarily belong to a couple main language households.

Alternative #3: Specialization
Wealthy Sutton highlights a bitter lesson for the sector of AI analysis:
“The nice energy of basic objective strategies […] that proceed to scale with elevated computation […]. The 2 strategies that appear to scale arbitrarily: search and studying.”
For many under-represented languages, computation and information, nevertheless, are restricted. It’s thus cheap to include (some quantity of) information into our language fashions to make them extra helpful for such languages.
This could take the type of biasing the tokenization course of, which frequently produces poor segmentations for languages with a wealthy morphology or restricted information. We will modify the algorithm to desire tokens which are shared throughout many languages , protect tokens’ morphological construction , or make the tokenization algorithm extra strong to take care of misguided segmentations .
We will additionally exploit the truth that many under-represented languages belong to teams of comparable languages. Fashions specializing in such teams can thus extra simply share data throughout languages. Whereas latest fashions focus primarily on associated languages , future fashions might also embrace language variants and dialects, which may profit from constructive switch from associated languages.
Whereas principled variants of masking reminiscent of complete phrase masking and PMI-masking have been discovered helpful up to now, new pre-training targets that take linguistic traits reminiscent of wealthy morphology or tone into consideration could result in extra sample-efficient studying. Lastly, the architeture of fashions will be tailored to include details about morphology reminiscent of within the KinyaBERT mannequin for Kinyarwanda .

Conclusion
Whereas there was an amazing quantity of progress in latest multilingual AI, there’s nonetheless much more to do. Most significantly, we should always concentrate on creating information that displays the real-world circumstances of language audio system and to develop language expertise that serves the wants of audio system world wide. Whereas there’s momentum and growing consciousness that such work is essential, it takes a village to develop equitable language expertise for the world’s languages. Masakhane (“allow us to construct collectively” in isiZulu)!
Quotation
For attribution in tutorial contexts or books, please cite this work as:
Sebastian Ruder, "The State of Multilingual AI". http://ruder.io/state-of-multilingual-ai/, 2022.
BibTeX quotation:
@misc{ruder2022statemultilingualai,
writer = {Ruder, Sebastian},
title = {{The State of Multilingual AI}},
12 months = {2022},
howpublished = {url{http://ruder.io/state-of-multilingual-ai/}},
}

{kind=link}
{kind=link}