This put up expands on the EMNLP 2021 tutorial on Multi-domain Multilingual Query Answering.
The tutorial was organised by Avi Sil and me. On this put up, I spotlight key insights and takeaways of the tutorial. The slides are obtainable on-line. You could find the desk of contents under:
Query answering is likely one of the most impactful duties in pure language processing (NLP). Within the tutorial, we give attention to two major classes of query answering studied within the literature: open-retrieval query answering (ORQA) and studying comprehension (RC).
Open-Retrieval QA vs Studying Comprehension
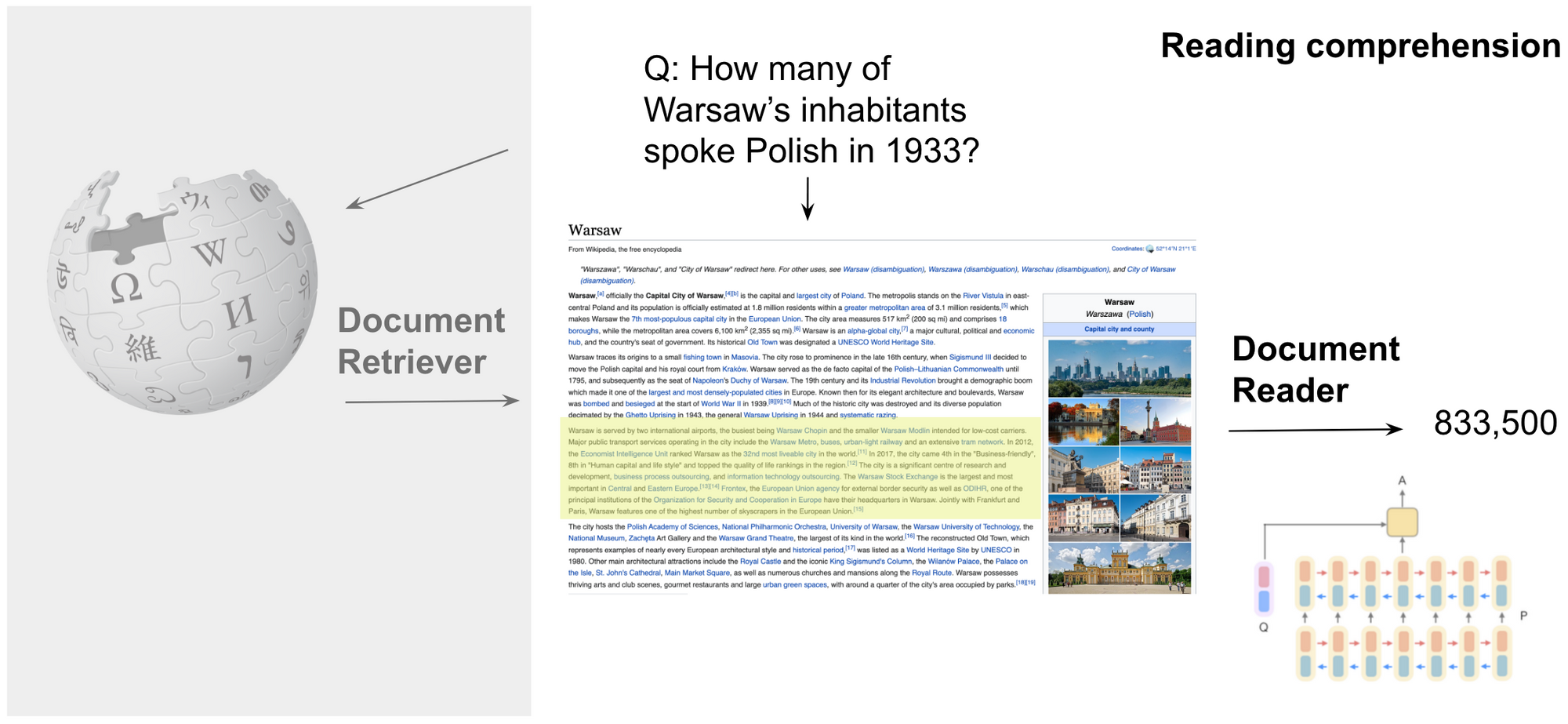
Open-retrieval QA focuses on probably the most normal setting the place given a query we first must retrieve related paperwork from a big corpus resembling Wikipedia. We then course of these paperwork to establish the related reply as may be seen under. We keep away from utilizing the time period open-domain QA as “open-domain” may additionally discuss with a setting protecting many domains.

Studying comprehension may be seen as a sub-problem of open-retrieval QA because it assumes that now we have entry to the gold paragraph that accommodates the reply (see under). We then solely want to search out the corresponding reply on this paragraph. In each settings, solutions are generally represented as a minimal span.
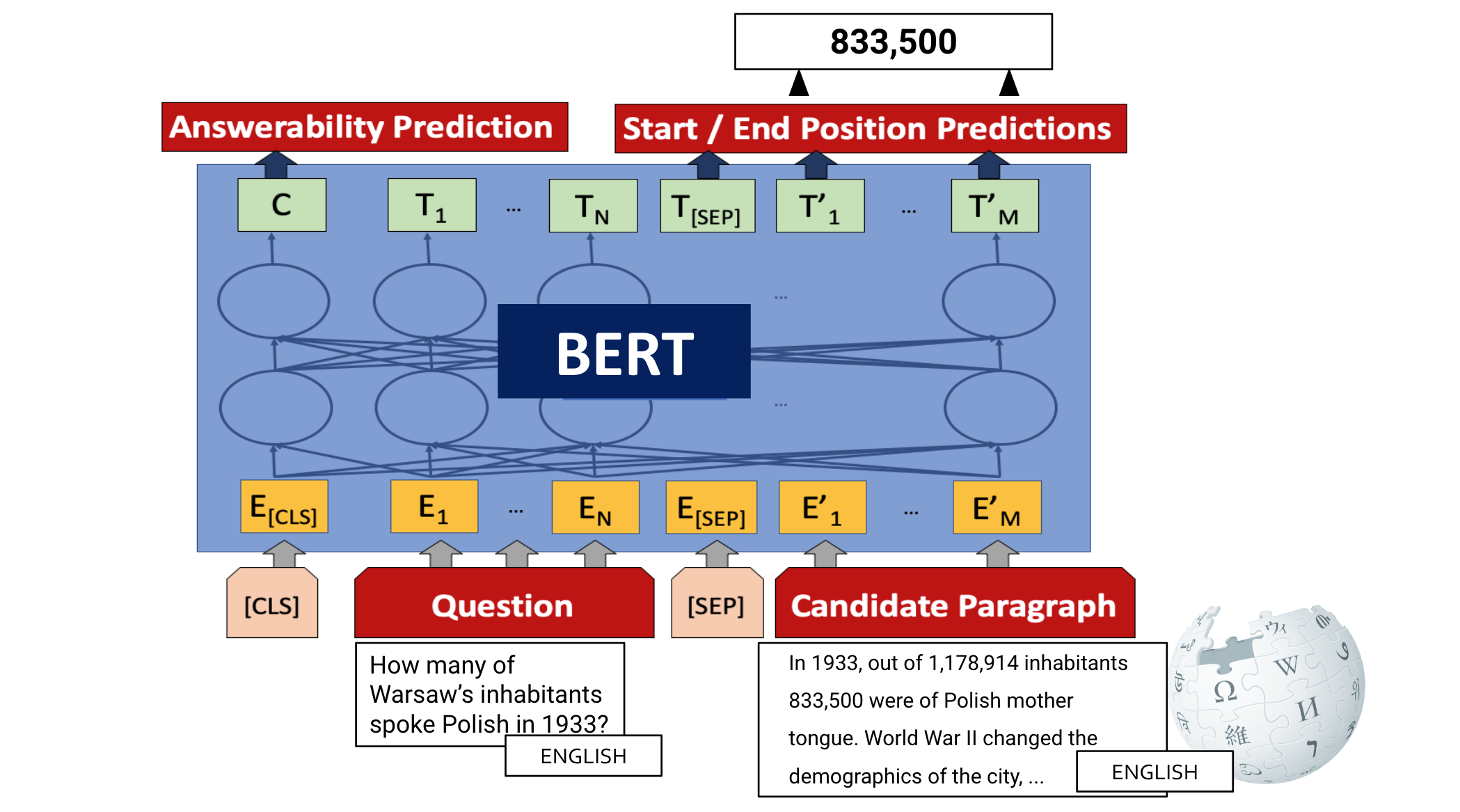
Commonplace approaches for studying comprehension construct on pre-trained fashions resembling BERT. The mannequin is supplied with the query and candidate paragraph as enter and is skilled to foretell whether or not the query is answerable (sometimes utilizing the illustration related to its [CLS] token) and whether or not every token is the beginning or finish of a solution span, which may be seen under. The identical strategy can be utilized for ORQA, with some modifications (Alberti et al., 2019).
Info retrieval (IR) strategies are used to retrieve the related paragraphs. Traditional sparse strategies resembling BM25 (Robertson et al., 2009) don’t require any coaching as they weigh phrases and paperwork primarily based on their frequency utilizing tf-idf measures. Latest dense neural approaches resembling DPR (Karpukhin et al., 2020) practice fashions to maximise the similarity between query and passage after which retrieve probably the most related passages through most interior product search.
What’s a Area?
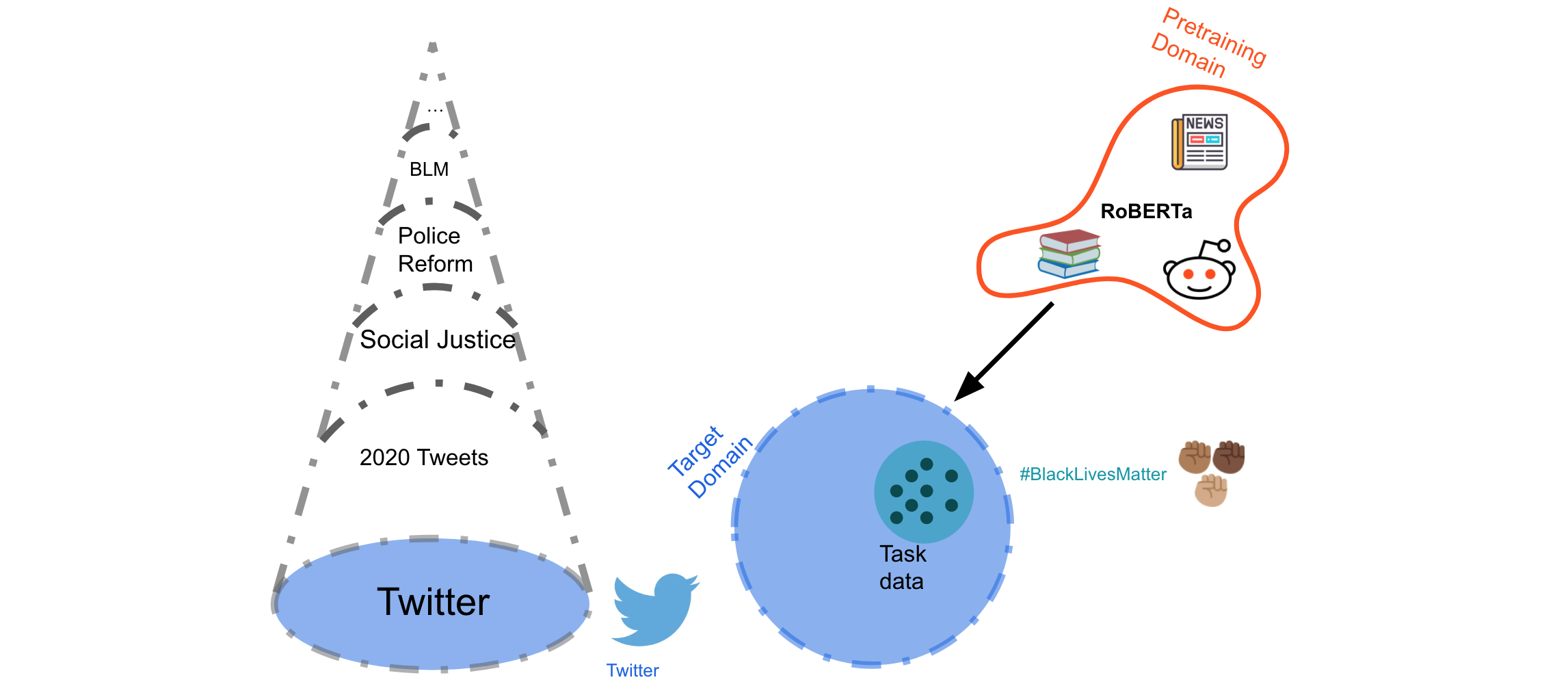
A website may be seen as a manifold in a high-dimensional selection house consisting of many dimensions resembling socio-demographics, language, style, sentence kind, and many others (Plank et al., 2016). Domains differ when it comes to their granularity and enormous domains resembling Twitter can include a number of extra slim domains to which we’d need to adapt our fashions. Two main aspects of this selection house are style (we’ll use this time period interchangeably with ‘area’) and language, which would be the focus of this put up.
In every of the 2 major sections of this put up, we’ll first focus on widespread datasets after which modelling approaches.
Datasets for Multi-Area QA
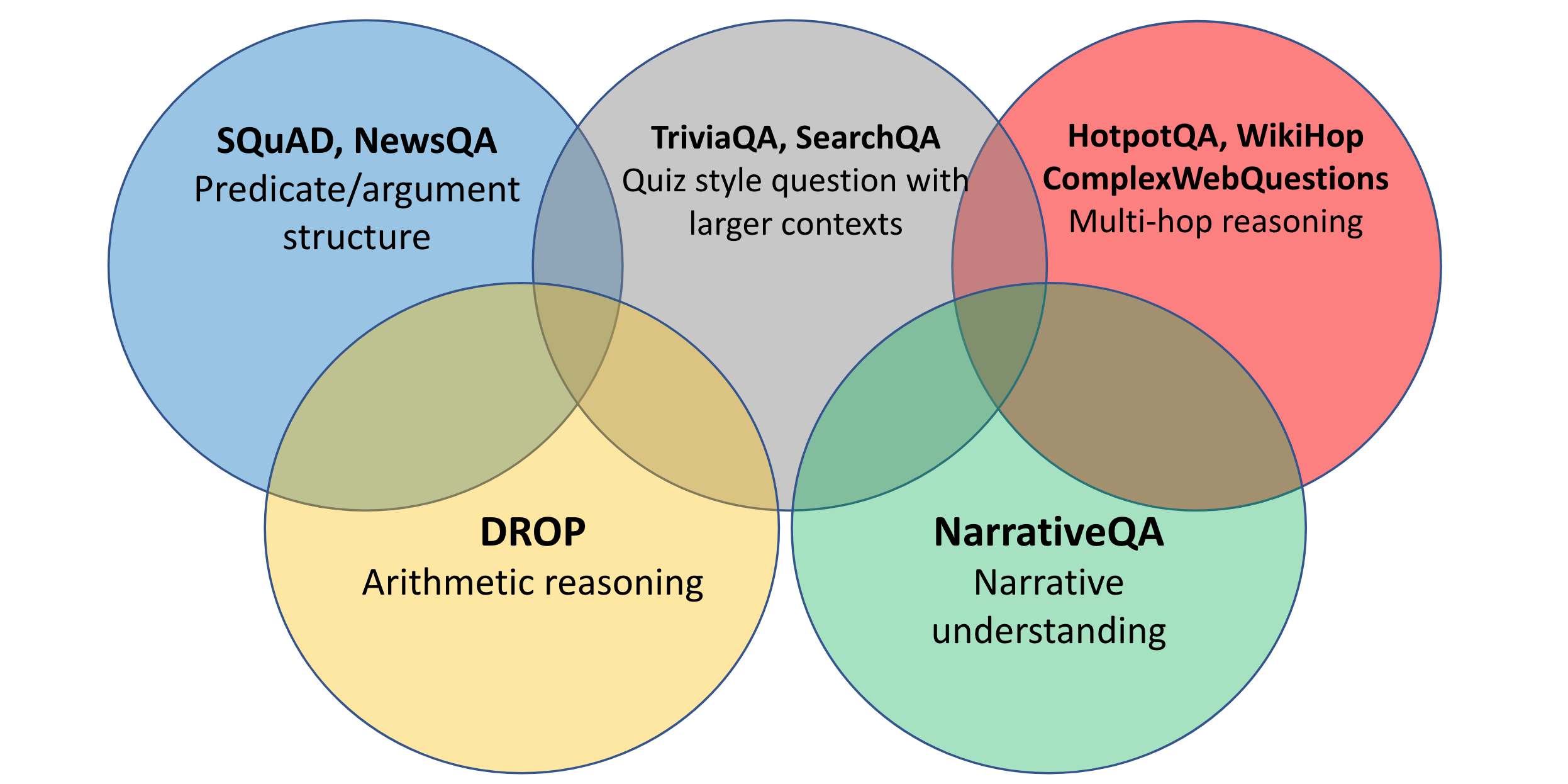
Analysis in query answering has spanned many domains, as may be seen under. The most typical area is Encyclopedia, which covers many Wikipedia-based datasets resembling SQuAD (Rajpurkar et al., 2016), Pure Questions (NQ; Kwiatkowski et al., 2019), DROP (Dua et al., 2019), and WikiReading (Hewlett et al., 2016), amongst many others. Datasets on this area are sometimes known as “open-domain” QA.
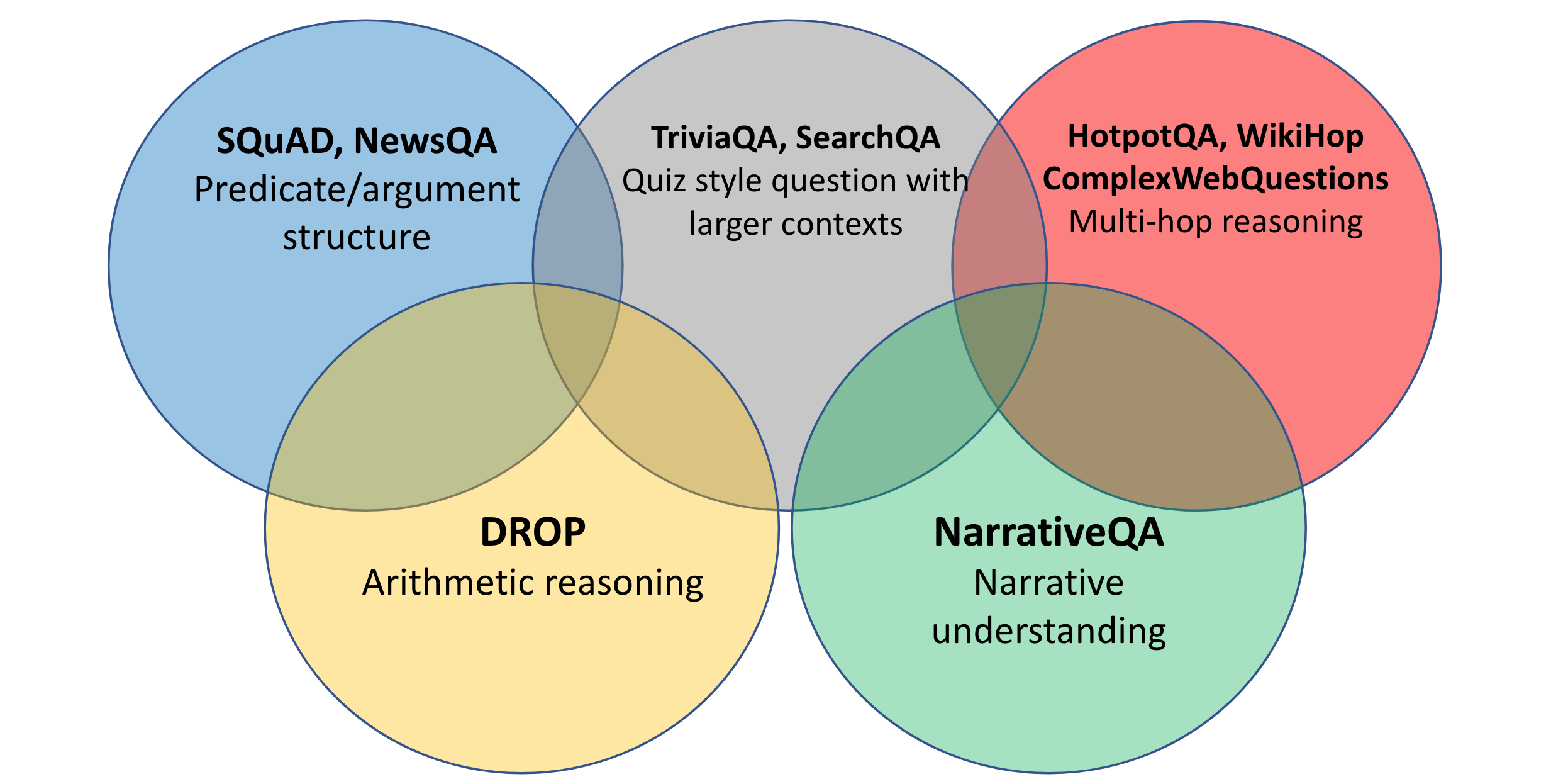
Datasets within the Fiction area sometimes require processing narratives in books resembling NarrativeQA (Kočiský et al., 2018), Kids’s Guide Check (Hill et al., 2016), and BookTest (Bajgar et al., 2016) or narratives written by crowd staff resembling MCTest (Richardson et al., 2013), MCScript (Modi et al., 2016), and ROCStories (Mostafazedh et al., 2016).
Tutorial assessments datasets goal science questions in US faculty assessments resembling ARC (Clark et al., 2018), college-level examination assets resembling ReClor (Yu et al., 2019) and school-level examination assets resembling RACE (Lai et al., 2017).
Information datasets embrace NewsQA (Trischler et al., 2017), CNN / Each day Mail (Hermann et al., 2015), and NLQuAD (Soleimani et al., 2021).
As well as, there are datasets centered on Specialised Knowledgeable Supplies together with manuals, experiences, scientific papers, and many others. Such domains are commonest in trade as domain-specific chatbots are more and more utilized by firms to answer customers queries however related datasets are not often made obtainable. Present datasets give attention to tech boards resembling TechQA (Castelli et al., 2020) and AskUbuntu (dos Santos et al., 2015) in addition to scientific articles together with BioASQ (Tsatsaronis et al., 2015) and Qasper (Dasigi et al., 2021). As well as, the pandemic noticed the creation of many datasets associated to COVID-19 resembling COVID-QA-2019 (Möller et al., 2020), COVID-QA-147 (Tang et al., 2020), and COVID-QA-111 (Lee et al., 2020).
Past these datasets specializing in particular person domains, there are a number of datasets spanning a number of domains resembling CoQA (Reddy et al., 2019), QuAIL (Rogers et al., 2020), and MultiReQA (Guo et al., 2021), amongst others. Lastly, the ORB analysis server (Dua et al., 2019) permits the analysis of programs throughout datasets spanning a number of domains.
Multi-Area QA Fashions
Typically when studying in a multi-domain setting there could also be restricted or no labelled information obtainable within the goal area obtainable. We focus on the right way to adapt to a goal area utilizing solely unlabelled information, the simplest method to make use of pre-trained language fashions for area adaptation in QA, and the right way to generalize throughout domains.
Unsupervised Area Adaptation for QA
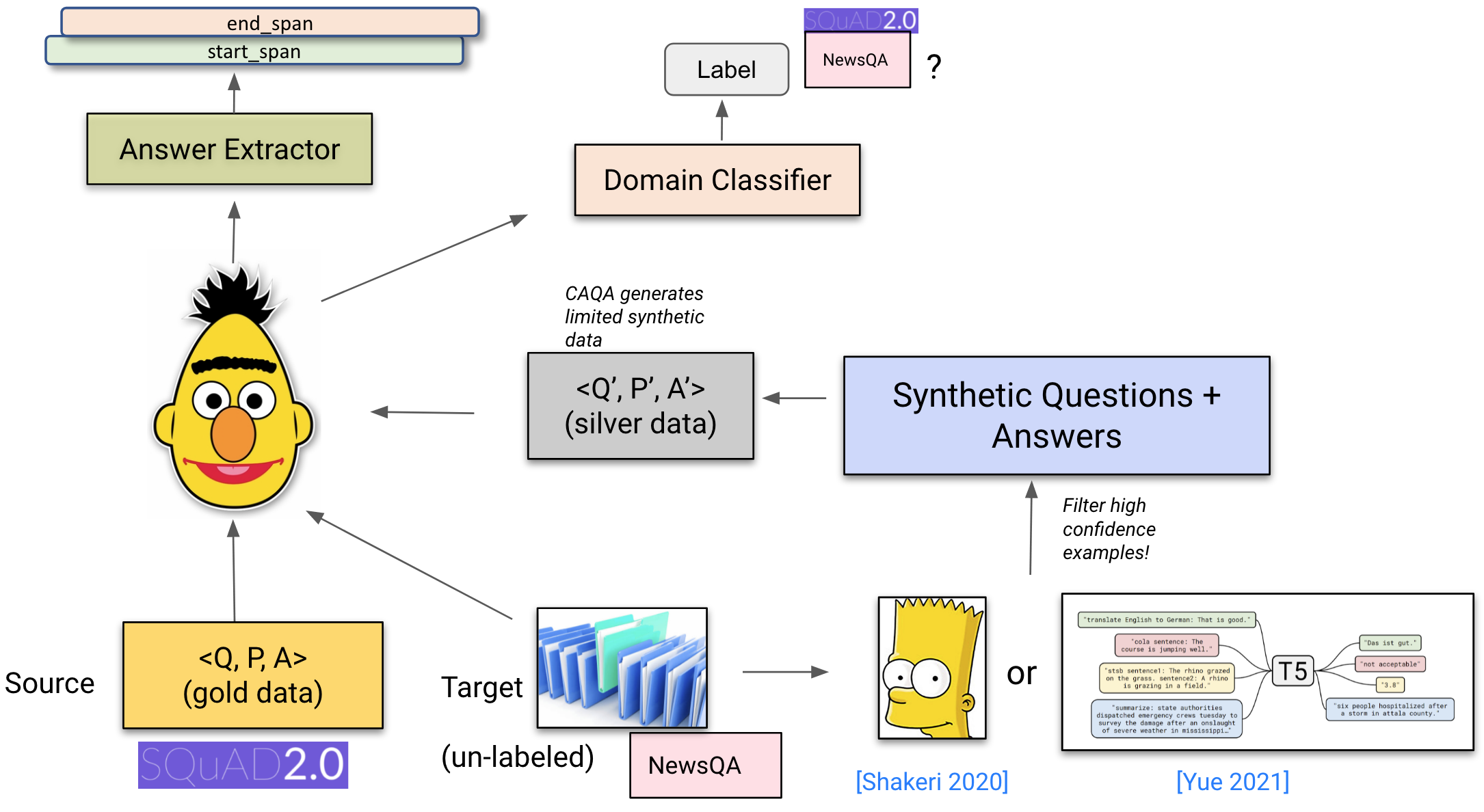
Unsupervised area adaptation for QA assumes entry to labelled information in a supply area and unlabelled goal area information. Within the absence of labelled gold information within the goal area, most strategies depend on producing ‘silver’ <query, paragraph, reply> information within the goal area. To this finish, these strategies practice a query era mannequin primarily based on a pre-trained LM on the supply area after which apply it to the goal area to generate artificial questions given reply spans (Wang et al., 2019; Shakeri et al., 2020; Yue et al., 2021). The QA mannequin is then skilled collectively on the gold supply area and silver goal area information, as may be seen under. That is typically mixed with different area adaptation methods resembling adversarial studying and self-training (Cao et al., 2020).
Area Adaptation with Pre-trained LMs
In lots of eventualities with specialised domains, a normal pre-trained language mannequin resembling BERT might not be ample. As an alternative, domain-adaptive fine-tuning (Howard & Ruder, 2018; Gururangan et al., 2020) of a pre-trained LM on course area information sometimes performs higher. Latest examples resembling BioBERT (Lee et al., 2019) and SciBERT (Beltagy et al., 2019) have been efficient for biomedical and scientific domains respectively.
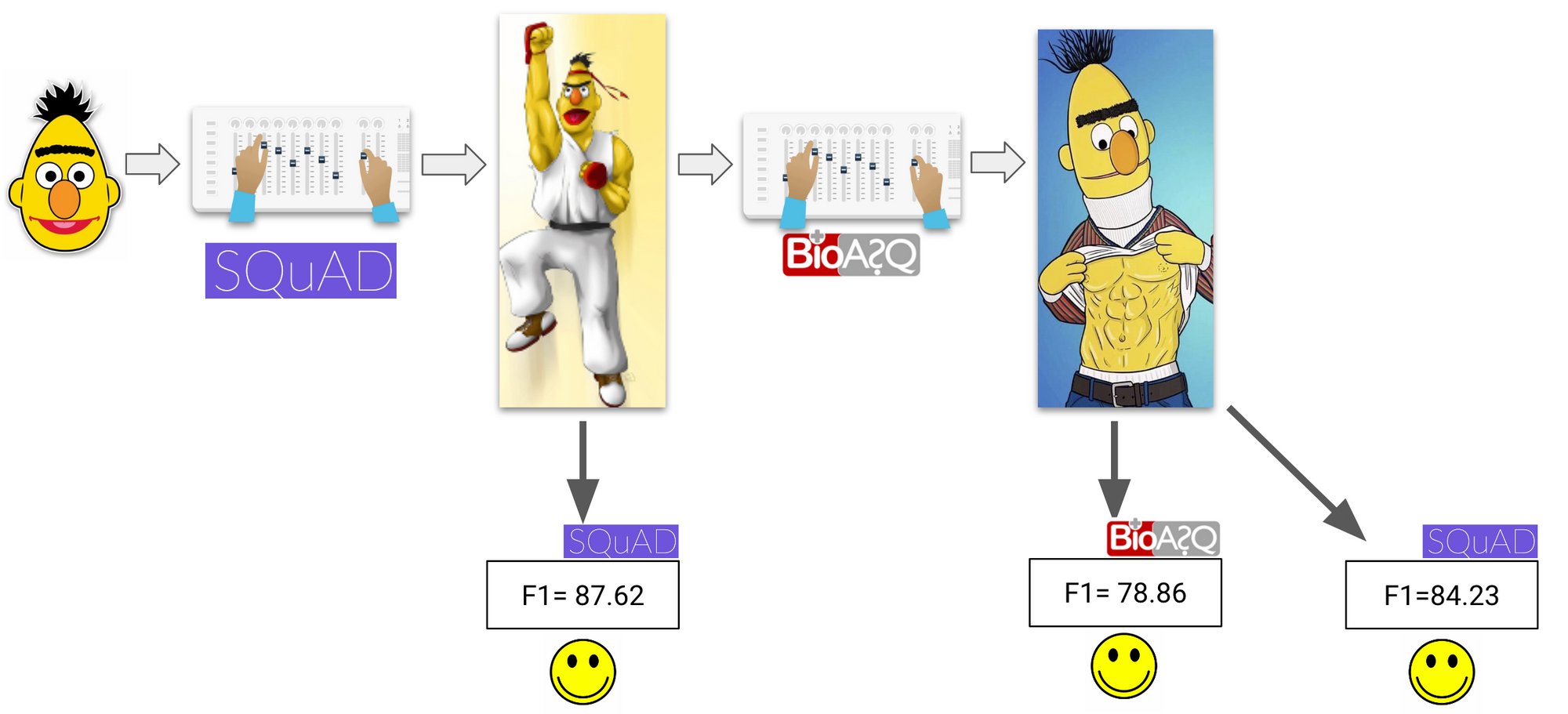
When labelled information in a supply area and within the goal area can be found, a normal recipe is to first fine-tune a mannequin on labelled supply area information after which to subsequently fine-tune it on labelled information within the goal area. Nonetheless, naive fine-tuning usually results in deterioration of efficiency within the supply area, which can be undesirable. As an alternative, methods from continuous studying resembling L2 regularization (Xu et al., 2019) be certain that the parameters of the mannequin fine-tuned on the goal area don’t diverge considerably from the supply area mannequin, thereby lowering catastrophic forgetting as may be seen under.
For very low-resource domains, one other technique is to explicitly adapt the mannequin to traits of the goal area. If the goal area accommodates specialised phrases, the mannequin’s vocabulary may be augmented with these phrases to be taught higher representations. As well as, for a lot of domains, the construction of the unlabelled information can comprise data which may be helpful for the tip process. This construction such because the summary, error description, related trigger, and many others may be leveraged to generate artificial information on which the mannequin may be fine-tuned (Zhang et al., 2020).
Within the open-retrieval setting, dense retrieval strategies (Karpukhin et al., 2020) skilled on a supply area could not generalize in a zero-shot method to low-resource goal domains. As an alternative, we will leverage the identical query era strategies mentioned within the earlier part to create silver information for coaching a retrieval mannequin on the goal area (Reddy et al., 2021). Ensembling over BM25 and the tailored DPR mannequin yields the perfect outcomes.
Area Generalization
In observe, pre-trained fashions fine-tuned on a single area typically generalize poorly. Coaching on a number of supply distributions reduces the necessity for choosing a single supply dataset (Talmor & Berant, 2019). Further fine-tuning on a associated process helps even when utilizing pre-trained fashions.
Nonetheless, totally different datasets typically have totally different codecs, which makes it tough to coach a joint mannequin for them with out task-specific engineering. Latest pre-trained LMs resembling T5 facilitate such cross-dataset studying as every dataset may be transformed to a unified text-to-text format. Coaching a mannequin collectively throughout a number of QA datasets with such a text-to-text format results in higher generalization to unseen domains (Khashabi et al., 2020).
Language may be seen as one other side of the area manifold. As we’ll see, many strategies mentioned within the earlier part can be efficiently utilized to the multilingual setting. On the identical time, multilingual QA poses its personal distinctive challenges.
Datasets for Multilingual QA
Many early multilingual IR and QA datasets have been collected as a part of neighborhood evaluations. Many check collections used newswire articles, e.g. CLIR at TREC 1994–2004, QA at CLEF 2003–2005 (Magnini et al., 2003) or Wikipedia, e.g. QA at CLEF 2006–2008 (Gillard et al., 2006). Such datasets centered primarily on Indo-European languages, although newer ones additionally lined different languages, e.g. Hindi and Bengali at FIRE 2012 (Yadav et al., 2012).
There are big selection of monolingual studying comprehension datasets, lots of them variants of SQuAD (Rajpurkar et al., 2016). Most of them can be found in Chinese language, Russian, and French and so they usually include naturalistic information in every language.
Monolingual open-retrieval QA datasets are extra numerous in nature. They differ primarily based on the sort and quantity of context they supply and infrequently give attention to specialised domains, from Chinese language historical past exams (Zhao & Zhao, 2018) to Chinese language maternity boards (Xu et al., 2020) and Polish ‘Do you know?’ questions (Marcinczuk et al., 2013).
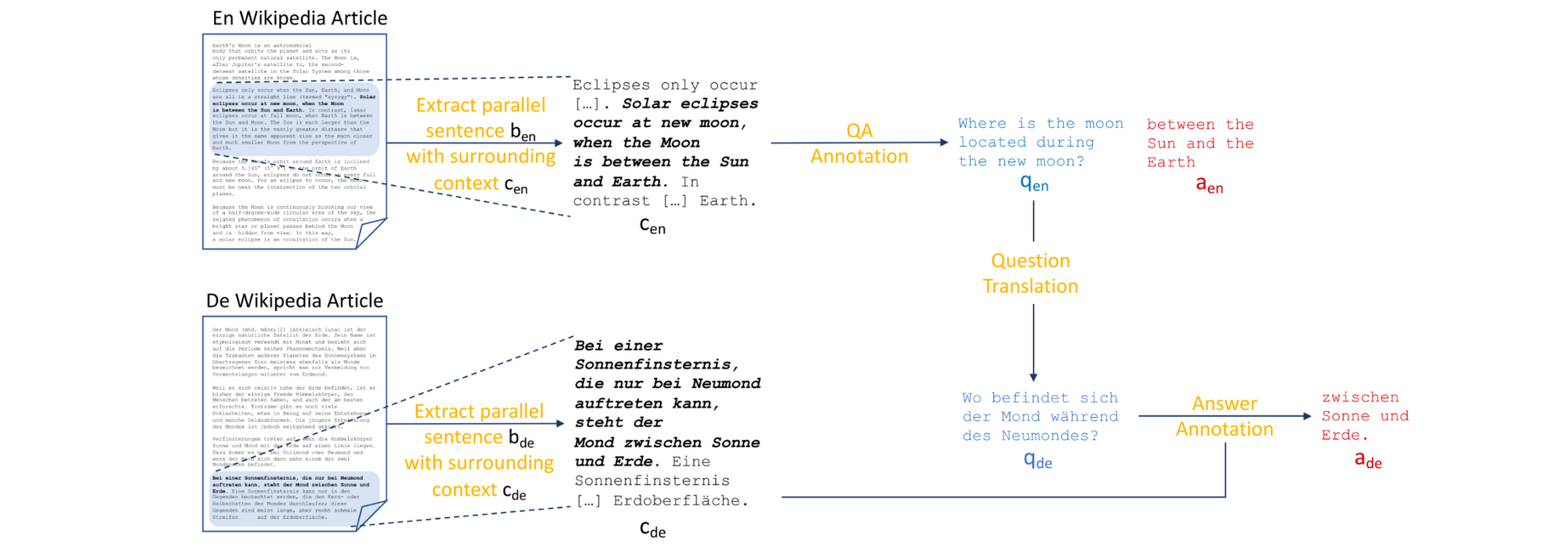
Multilingual studying comprehension datasets have usually been created utilizing translations. MLQA (Lewis et al., 2020), which may be seen above has been created by mechanically aligning Wikipedia paragraphs throughout a number of languages and annotating questions and solutions on the aligned paragraphs. Such computerized alignment, nonetheless, could result in extreme high quality points for some languages (Caswell et al., 2021) and should lead to overfitting to the biases of the alignment mannequin. One other dataset, XQuAD (Artetxe et al., 2020) was created by professionally translating a subset of SQuAD to 10 different languages. Lastly, MLQA-R and XQuAD-R (Roy et al., 2020) are conversions of the previous datasets to the reply sentence retrieval setting.
Multilingual open-retrieval QA datasets sometimes include naturalistic information. XQA (Liu et al., 2019) covers ‘Do you know?’ Wikipedia questions transformed to a Cloze format. For every query, the highest 10 Wikipedia paperwork ranked by BM25 are offered as context. TyDi QA (Clark et al., 2020) ask annotators to jot down “information-seeking” questions primarily based on quick Wikipedia prompts in typologically numerous languages. Such information-seeking questions result in much less lexical overlap in comparison with RC datasets like MLQA and XQuAD and thus lead to a tougher QA setting. Nonetheless, as in-language Wikipedias are used for locating context paragraphs (through Google Search) and because the Wikipedias of many under-represented languages are very small, many questions in TyDi QA are unanswerable.
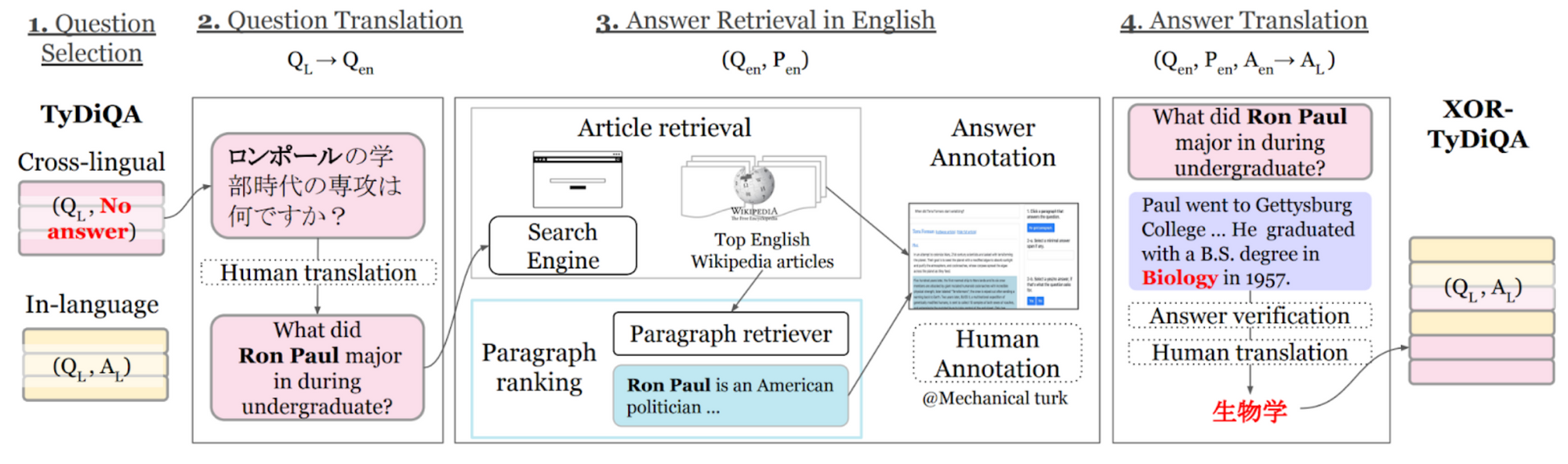
XOR-TyDi QA (Asai et al., 2021) addresses this problem through the above process, which interprets unanswerable TyDi QA inquiries to English and retrieves context paragraphs from English Wikipedia. This technique considerably decreases the fraction of unanswerable questions. Whereas XOR-TyDi QA focuses on cross-lingual retrieval, Mr. TyDi (Zhang et al., 2021) augments TyDi QA with in-language paperwork for evaluating monolingual retrieval fashions. As solutions in TyDi QA are spans in a sentence, Gen-TyDi QA (Muller et al., 2021) extends the dataset with human-generated solutions to allow the analysis of generative QA fashions. Lastly, MKQA (Longpre et al., 2020) interprets 10k queries from Pure Questions (Kwiatkowski et al., 2019) to 25 different languages. As well as, it augments the dataset with annotations that hyperlink immediately towards Wikidata entities, enabling analysis past span extraction.
An rising class of multilingual QA datasets is multilingual widespread sense reasoning. Such datasets include multiple-choice assertions which are translated into different languages (Ponti et al., 2020; Lin et al., 2021).
Problems with Multilingual QA Datasets
Present monolingual and multilingual QA datasets have some points that one ought to concentrate on.
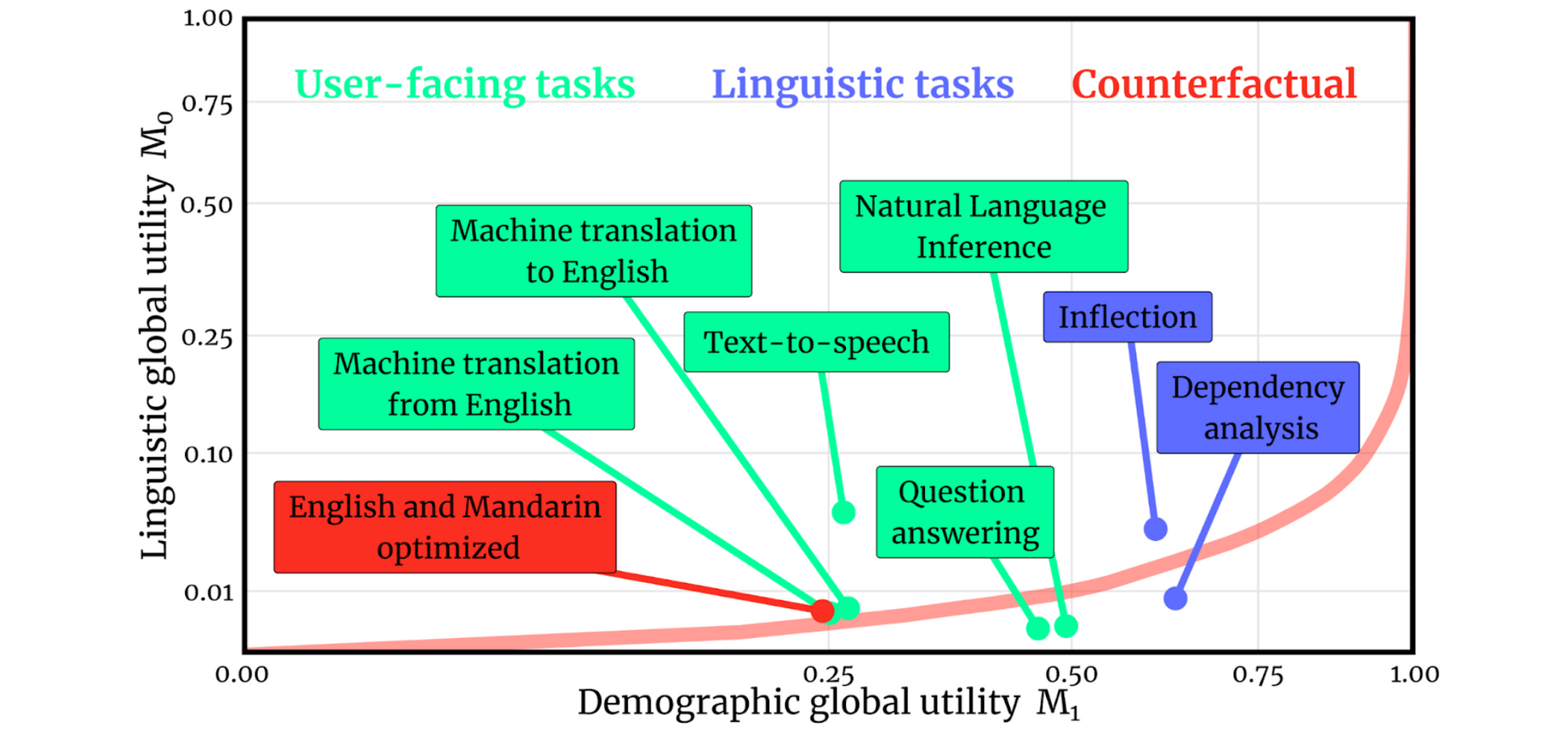
Language distribution Present datasets predominantly give attention to “high-resource” languages the place massive quantities of knowledge can be found. Evaluating QA fashions on such datasets supplies a distorted view of progress within the subject. For example, questions that may be solved by string matching are simple in English however a lot more durable in morphologically wealthy languages (Clark et al., 2020). Amongst present key purposes of NLP, QA has the bottom linguistic world utility, i.e. efficiency averaged the world over’s languages (Blasi et al., 2021), which may be seen under. Whereas QA datasets cowl languages with many audio system, there’s nonetheless a protracted strategy to go when it comes to an equitable protection the world over’s languages.
Homogeneity With the intention to make assortment scalable, multilingual datasets typically accumulate information that covers the identical query or related subjects throughout languages, thus lacking out on language-specific nuances. As well as, it’s typically not possible to do an in-depth error evaluation for each language. The most typical supply of homogeneity is translation, which carries its personal biases.
Limitations of translation “Translationese” differs in lots of elements from pure language (Volanksy et al., 2015). Translated questions typically wouldn’t have solutions in a goal language Wikipedia (Valentim et al., 2021). As well as, datasets created through translation inherit artefacts resembling a big train-test overlap of solutions in NQ (Lewis et al., 2020) and translation additionally results in new artefacts, e.g. in NLI when premise and speculation are translated individually (Artetxe et al., 2020). Lastly, translated questions differ from the kinds of questions “naturally” requested by audio system of various languages, resulting in an English and Western-centric bias.
English and Western-centric bias Examples in lots of QA datasets are biased in the direction of questions requested by English audio system. Cultures differ in what kinds of questions are sometimes requested, e.g. audio system outdoors the US in all probability wouldn’t ask about well-known American soccer or baseball gamers. In COPA (Roemmele et al., 2011), many referents haven’t any language-specific phrases in some languages, e.g. bowling ball, hamburger, lottery (Ponti et al., 2020). Widespread sense information, social norms, taboo subjects, assessments of social distance, and many others are additionally culture-dependent (Thomas, 1983). Lastly, the widespread setting of coaching on English information results in an overestimation of switch efficiency on languages much like English and underestimation on extra distant languages.
Dependence on retrieval The usual setting of figuring out a minimal span for open-domain QA within the retrieved paperwork advantages extractive programs. It assumes there’s a single gold paragraph offering the proper reply and doesn’t think about data from different paragraphs or pages. For unanswerable questions, solutions could typically be present in different pages that weren’t retrieved (Asai & Choi, 2021).
Info shortage Typical information assets resembling language-specific Wikipedias typically don’t comprise the related data, notably for under-represented languages. For such languages, datasets should essentially be cross-lingual. As well as, some data is just obtainable from different sources, e.g. IMDb, information articles, and many others.
Problem of multilingual comparability Evaluating a mannequin’s efficiency throughout totally different languages is tough attributable to a spread of things resembling totally different ranges of query issue, totally different quantities and high quality of monolingual information, influence of translationese, and many others. As an alternative, it’s higher to carry out system-level comparisons throughout languages.
Monolingual vs multilingual QA datasets Creating multilingual QA datasets is dear and thus typically infeasible with tutorial budgets. In distinction, work on monolingual QA datasets is usually perceived as “area of interest”. Such work, nonetheless, is arguably far more necessary and impactful than incremental modelling advances, that are generally accepted to conferences (Rogers et al., 2021). With the intention to foster inclusivity and variety in NLP, it’s key to allow and reward such work, notably for under-represented languages. Language-specific QA datasets can transcend a “replication” of English work by, as an illustration, performing analyses of language-specific phenomena and increasing or bettering the QA setting.
Creating QA Datasets
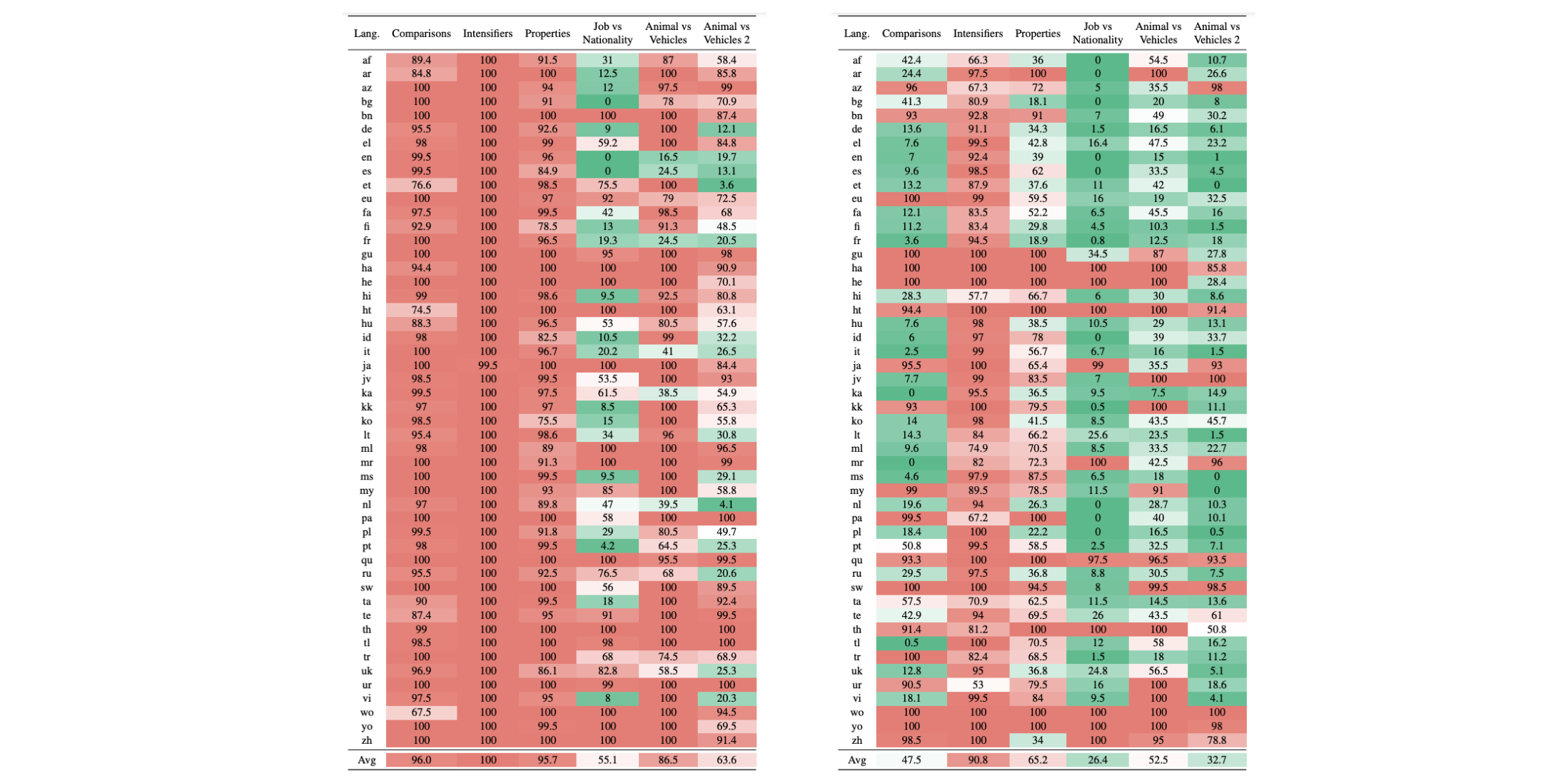
Environment friendly multilingual QA analysis at scale A key problem of multilingual QA is the shortage of knowledge for a lot of languages. As an alternative of labelling massive quantities of knowledge in each language to be able to cowl all the distribution, we will create focused assessments that probe for particular capabilities, as an illustration utilizing CheckList (Ribeiro et al., 2020). This manner, a small variety of templates can cowl many various mannequin capabilities. Such template-based assessments have to date been used for evaluating multilingual studying comprehension (Ruder et al., 2021) and closed-book QA (Jiang et al., 2020; Kassner et al., 2021) the place they permit fine-grained analysis throughout languages as may be seen under. Nonetheless, to be able to scale such assessments throughout languages native speaker experience or translation are nonetheless required.
Greatest practices When creating a brand new QA dataset, you will need to give attention to the analysis questions you need to reply together with your dataset. Attempt to keep away from creating confounding variables (translationese, morphology, syntax, and many others) that obfuscate answering these questions. Think about gathering information in a typologically numerous set of languages and take into consideration the use case of your dataset and the way programs primarily based on the info may assist people. Selected an acceptable dataset format: If you wish to assist individuals world wide reply questions, give attention to information-seeking questions and keep away from cultural bias. If you wish to assist customers ask questions on a brief doc, give attention to studying comprehension. Lastly, to be able to create inclusive and numerous QA datasets, you will need to work with speaker communities and conduct participatory analysis (∀ et al., 2020).
Multilingual QA Analysis
Widespread analysis settings in multilingual QA vary from monolingual QA the place all information is in the identical language to cross-lingual eventualities the place the query, context, and reply may be in several languages in addition to zero-shot cross-lingual switch settings the place coaching information is in a high-resource language and check information is in one other language.
Analysis metrics are primarily based on lexical overlap utilizing both Precise Match (EM) or imply token F1, with elective pre-processing of predictions and solutions (Lewis et al., 2020). Such token-based metrics, nonetheless, are usually not acceptable for languages with out whitespace separation and require a language-specific segmentation methodology, which introduces a dependence on the analysis setting. Moreover, metrics primarily based on string matching penalize morphologically wealthy languages as extracted spans could comprise irrelevant morphemes, favour extractive over generative programs, and are biased in the direction of quick solutions.
Alternatively, analysis may be carried out on the character or byte degree. As commonplace metrics used for pure language era (NLG) resembling BLEU or ROUGE present little correlation with human judgements for some languages (Muller et al., 2021), realized metrics primarily based on sturdy pre-trained fashions resembling BERTScore (Zhang et al., 2020) or SAS (Risch et al., 2021) could also be most popular, notably for evaluating generative fashions.
Multilingual QA Fashions
Multilingual fashions for QA are usually primarily based on pre-trained multilingual Transformers resembling mBERT (Devlin et al., 2019), XLM-R (Conneau et al., 2020), or mT5 (Xue et al., 2021).
Fashions for Multilingual Studying Comprehension
For studying comprehension, a multilingual mannequin is usually fine-tuned on information in English after which utilized to check information within the goal language through zero-shot switch. Latest fashions usually carry out nicely on high-resource languages current in commonplace QA datasets whereas efficiency is barely decrease for languages with totally different scripts (Ruder et al., 2021), which may be seen under. Nice-tuning the mannequin on information within the goal language utilizing masked language modelling (MLM) earlier than coaching on task-specific information usually improves efficiency (Pfeiffer et al., 2020).

In observe, fine-tuning on a number of labelled goal language examples can considerably enhance switch efficiency in comparison with zero-shot switch (Hu et al., 2020; Lauscher et al., 2020). Nonetheless, the identical doesn’t maintain for the tougher open-retrieval QA (Kirstain et al., 2021). Multi-task coaching on information in lots of languages improves efficiency additional (Debnath et al., 2021).
Most prior work on multilingual QA makes use of the translate-test setting, which interprets all information into English—sometimes utilizing a web based MT system as a black field—after which applies a QA mannequin skilled on English to it (Hartrumpf et al., 2008; Lin & Kuo, 2010; Shima & Mitamura, 2010). With the intention to map the expected English reply to the goal language, back-translation of the reply span doesn’t work nicely as it’s agnostic of the paragraph context. As an alternative, latest strategies make use of the eye weights from a neural MT system to align the English reply span to a span within the unique doc (Asai et al., 2018; Lewis et al., 2020).
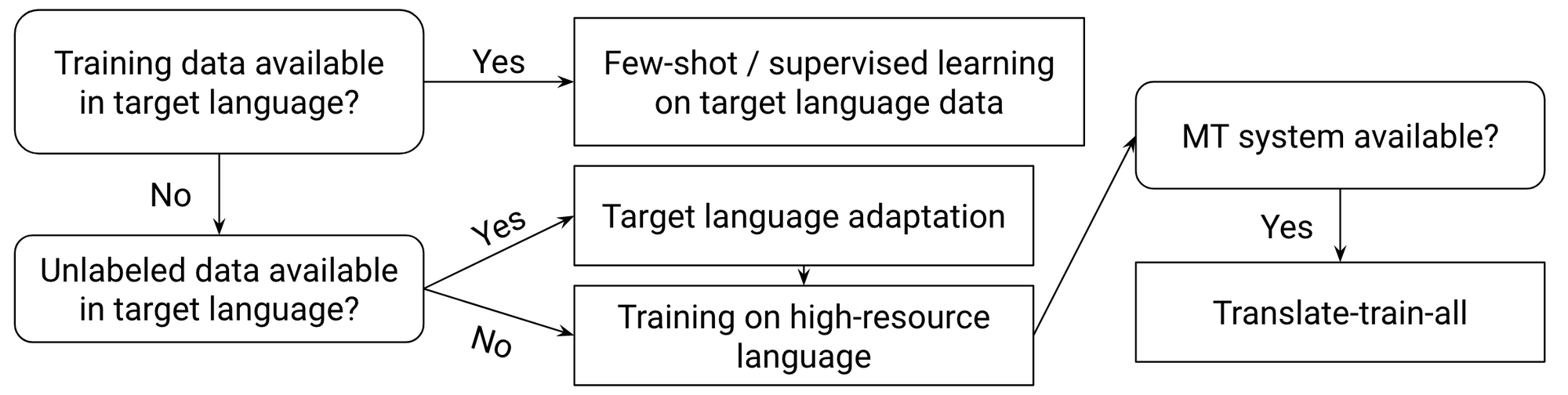
Alternatively, within the translate-train setting the English coaching information is translated to the goal language and a goal language QA mannequin is skilled on the info. On this case, it’s essential to make sure that reply spans may be recovered after translation by enclosing them with tags or utilizing fuzzy search (Hsu et al., 2019; Hu et al., 2020). We are able to go even additional and translate the English information to all goal languages on which we practice a multilingual QA mannequin. This translate-train-all setting usually performs greatest for studying comprehension (Conneau et al., 2020; Hu et al., 2020; Ruder et al., 2021) and achieves efficiency near English on high-resource languages however decrease on others. The under flowchart exhibits what methodology achieves the perfect efficiency relying on the obtainable information.
Fashions for Multilingual Open-Retrieval QA
Translate-test is the usual strategy for open-retrieval QA because it solely requires entry to English assets. Along with coaching a doc reader mannequin on English information, the open-retrieval setting additionally necessitates coaching an English retrieval mannequin. Throughout inference, we apply the fashions to the translated information and back-translate the reply to the goal language, which may be seen under. Nonetheless, low-quality MT could result in error propagation and for some questions solutions might not be obtainable within the English Wikipedia. However, translate-train is mostly infeasible within the open-retrieval setting because it requires translating all potential context (resembling all the Wikipedia) to the goal language. As a substitute, solely questions may be translated, which can outperform translate-test (Longpre et al., 2020).
With out utilizing translations, we have to practice cross-lingual retrieval and doc reader fashions that may assess similarity between questions and context paragraphs and reply spans respectively throughout languages. To this finish, we have to fine-tune a pre-trained multilingual mannequin utilizing goal language questions and English contexts. Nonetheless, proscribing retrieval to English paperwork limits the viewpoints and information sources at our disposal. We’d thus like to increase retrieval to paperwork in a number of languages.
Nice-tuning a pre-trained multilingual mannequin to retrieve passages solely on English information doesn’t generalize nicely to different languages (Zhang et al., 2021), much like the multi-domain setting. With the intention to practice a retrieval mannequin that higher generalizes to different languages, we will fine-tune the mannequin on multilingual information as an alternative (Asai et al., 2021). Alternatively, we will make use of information augmentation. Just like the multi-domain setting, we will receive silver information within the goal language by producing artificial goal language questions, on this case utilizing a translate-train mannequin (Shi et al., 2021). As well as, we will receive weakly supervised examples utilizing language hyperlinks in Wikipedia as may be seen under (Shi et al., 2021; Asai et al., 2021). Particularly, we retrieve the articles similar to the unique reply and reply paragraph in different languages and use them as new coaching examples. Lastly, a mix of BM25 + dense retrieval additionally performs greatest on this setting (Zhang et al., 2021).

To combination the retrieved passages in several languages we will practice a pre-trained multilingual text-to-text mannequin resembling mT5 to generate a solution when supplied with the passages as enter (Muller et al., 2021; Asai et al., 2021). The total pipeline consisting of multilingual retrieval and reply era fashions may be seen under. Because the mannequin will solely be taught to generate solutions in languages lined by current datasets, information augmentation is once more key. Moreover, fashions may be iteratively skilled utilizing newly retrieved and newly recognized solutions as further coaching information in subsequent iterations (Asai et al., 2021). The perfect fashions obtain sturdy efficiency within the full open-retrieval setting however there’s nonetheless important headroom left.
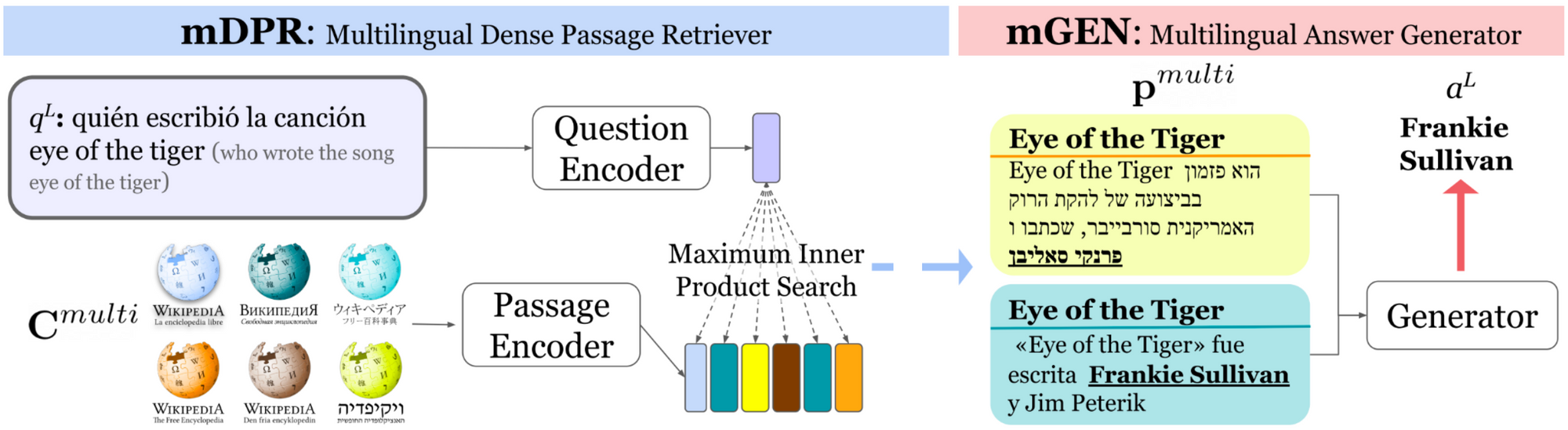
Two of probably the most difficult elements of multilingual open-retrieval QA are discovering the paragraph containing the reply (paragraph choice) and figuring out whether or not a doc accommodates the reply to a question (answerability prediction; Asai & Choi, 2021). A associated downside is reply sentence choice the place fashions predict whether or not a sentence accommodates the reply (Garg et al., 2020). Unanswerability is usually attributable to errors in doc retrieval or unanswerable questions requiring a number of paragraphs to reply. To deal with this headroom, Asai and Choi (2021) advocate to a) transcend utilizing Wikipedia for retrieval; b) to enhance the standard of annotated questions in current and future datasets; and c) to maneuver from extracting a span to producing the reply.
Multi-modal query answering For a lot of language varieties and domains, it could be simpler to acquire information in different modalities. As a latest instance, SD-QA (Faisal et al., 2021) augments TyDi QA with spoken utterances matching the questions in 4 languages and a number of dialects.
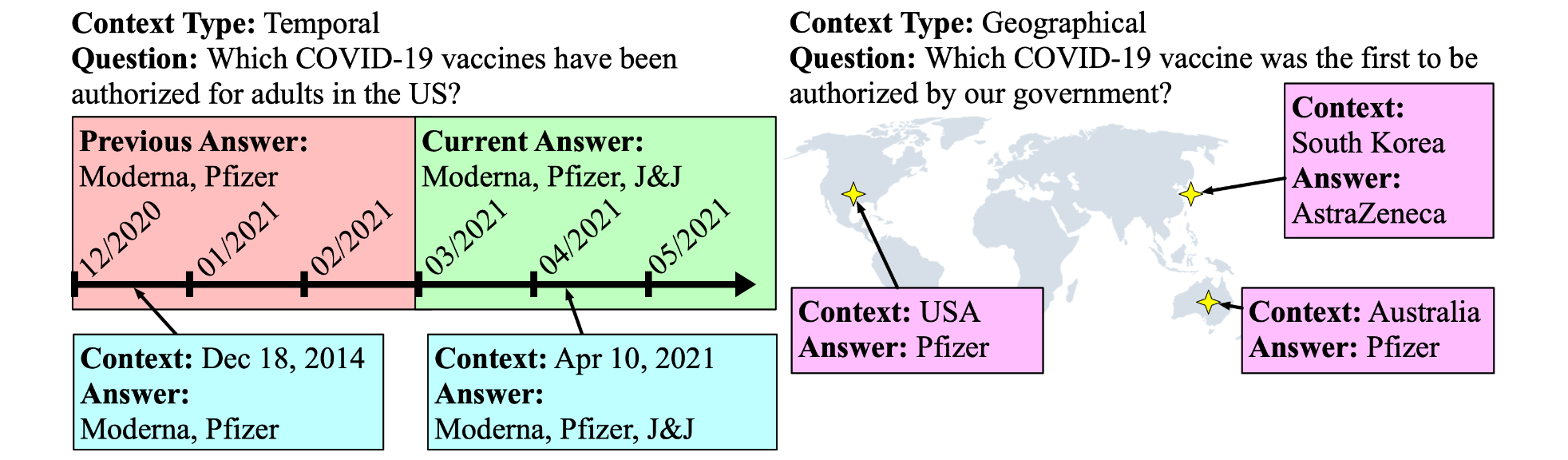
Different domains: time and geography A website can embrace many aspects not lined in current work. For example, solutions typically depend upon extra-linguistic context such because the time and site the place the questions had been requested. SituatedQA (Zhang & Choi, 2021) augments context-dependent questions in Pure Questions with time and geography-dependent contexts to review such questions.
Code-switching Code-switching is a typical phenomenon in multilingual communities however principally uncared for in QA analysis. Solely few assets exist in Bengali, Hindi, Telugu, and Tamil (Raghavi et al., 2015; Banerjee et al., 2016; Chandu et al., 2018; Gupta et al., 2018). For a broader overview of code-switching, take a look at this survey (Doğruöz et al., 2021).
Multilingual multi-domain generalization Most open-retrieval QA datasets solely cowl Wikipedia whereas many domains necessary in real-world purposes (e.g. tech questions) solely have English QA datasets. Different domains with out a lot information are notably related in non-Western contexts, e.g. finance for small companies, authorized and well being questions. As well as, at present unanswerable questions require retrieving data from a wider set of domains resembling IMDb (Asai et al., 2021). With the intention to create actually open-domain QA programs, we thus want to coach open-retrieval QA programs to reply questions from many various domains.
Information augmentation Technology of artificial multilingual QA information has been little explored past translation and retrieval (Shi et al., 2021). The era of knowledge about non-Western entities could also be notably useful.
Generative query answering In most current QA datasets, the quick reply is a span within the context. With the intention to practice and consider fashions extra successfully, extra datasets want to incorporate longer, extra pure solutions. The era of long-form solutions is especially difficult, nonetheless (Krishna et al., 2021).
Aggregating proof from numerous sources We have to develop higher aggregation strategies that cowl reasoning paths, e.g. for multi-hope reasoning (Asai et al., 2020). Fashions additionally want to have the ability to generate solutions which are trustworthy to the retrieved passages, requiring clear reply attribution. Lastly, we require strategies that may successfully mix proof from totally different domains and even totally different modalities.
Conversational query answering Present open-retrieval QA datasets are usually single-turn and don’t depend upon any exterior context. With the intention to practice usually helpful QA programs, fashions also needs to be capable to consider conversational context as required by datasets resembling QuAC (Choi et al., 2018). Particularly, they need to be capable to deal with coreference, ask for clarification relating to ambiguous questions, and many others.
Additional studying
Listed below are some further assets which may be helpful to be taught extra about totally different elements of the subject:
Credit score
Due to the next individuals for suggestions on a draft of the tutorial slides: Jon Clark, Tim Möller, Sara Rosenthal, Md Arafat Sultan, and Benjamin Muller.
Quotation
In case you discovered this put up useful, think about citing the tutorial as:
@inproceedings{ruder-sil-2021-multi,
title = "Multi-Area Multilingual Query Answering",
creator = "Ruder, Sebastian and
Sil, Avi",
booktitle = "Proceedings of the 2021 Convention on Empirical Strategies in Pure Language Processing: Tutorial Abstracts",
month = nov,
12 months = "2021",
handle = "Punta Cana, Dominican Republic {&} On-line",
writer = "Affiliation for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-tutorials.4",
pages = "17--21",
}

{kind=link}