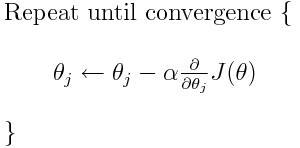
A while again, Quora routed a “Keras vs. Pytorch” query to me, which I made a decision to disregard as a result of it appeared an excessive amount of like flamebait to me. Couple of weeks again, after discussions with colleagues and (skilled) acquaintances who had tried out libraries like Catalyst, Ignite, and Lightning, I made a decision to get on the Pytorch boilerplate elimination prepare as effectively, and tried out Pytorch Lightning. As I did so, my ideas inevitably went again to the Quora query, and I got here to the conclusion that, of their present type, the 2 libraries and their respective ecosystems are extra related than they’re totally different, and that there isn’t any technological cause to decide on one over the opposite. Permit me to elucidate.
Neural networks be taught utilizing Gradient Descent. The central thought behind Gradient Descent might be neatly encapsulated within the equation under (extracted from the identical linked Gradient Descent article), and is known as the “coaching loop”. After all, there are different points of neural networks, comparable to mannequin and knowledge definition, however it’s the coaching loop the place the variations within the earlier variations of the 2 libraries and their subsequent coming collectively are most obvious. So I’ll principally discuss in regards to the coaching loop right here.

Keras was initially conceived of as a excessive degree API over the low degree graph based mostly APIs from Theano and Tensorflow. Graph APIs enable the consumer to first outline the computation graph after which execute it. As soon as the graph is outlined, the library will try and construct probably the most environment friendly illustration for the graph earlier than execution. This makes the execution extra environment friendly, however provides a variety of boilerplate to the code, and makes it tougher to debug if one thing goes improper. The most important success of Keras in my view is its capability to cover the graph API nearly fully behind a chic API. Specifically, its “coaching loop” appears like this:
mannequin.compile(optimizer=optimizer, loss=loss_fn, metrics=[train_acc])
mannequin.match(Xtrain, ytrain, epochs=epochs, batch_size=batch_size)
|
After all, the match methodology has many different parameters as effectively, however at its most advanced, it’s a single line name. And, that is in all probability all that’s wanted for simplest instances. Nonetheless, as networks get barely extra advanced, with possibly a number of fashions or loss features, or customized replace guidelines, the one choice for Keras was to drop right down to the underlying Tensorflow or Theano code. In these conditions, Pytorch seems actually engaging, with the ability, simplicity, and readability of its coaching loop.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
dataloader = DataLoader(Xtrain, batch_size=batch_size)
for epoch in epochs:
for batch in dataloader:
X, y = batch
logits = mannequin(X)
loss = loss_fn(logits, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# mixture metrics
train_acc(logits, loss)
# consider validation loss, and many others.
|
Nonetheless, with the discharge of Tensorflow 2.x, which included Keras as its default API by means of the tf.keras bundle, it’s now potential to do one thing similar with Keras and Tensorflow as effectively.
1 2 3 4 5 6 7 8 9 10 11 12 |
dataset = Dataset.from_tensor_slices(Xtrain).batch(batch_size)
for epoch in epochs:
for batch in dataset:
X, y = batch
with tf.GradientTape as tape:
logits = mannequin(X)
loss = loss_fn(y_pred=logits, y_true=y)
grads = tape.gradient(loss, mannequin.trainable_weights)
optimizer.apply_gradients(zip(grads, mannequin.trainable_weights))
# mixture metrics
train_acc(logits, y)
|
In each instances, builders settle for having to cope with some quantity of boilerplate in return for extra energy and adaptability. The strategy taken by every of the three Pytorch add-on libraries I listed earlier, together with Pytorch Lightning, is to create a Coach object. The coach fashions the coaching loop as an occasion loop with hooks into which particular performance might be injected as callbacks. Performance in these callbacks could be executed at particular factors within the coaching loop. So a partial LightningModule subclass for our use case would look one thing like this, see the Pytorch Lightning Documentation or my code examples under for extra particulars.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
class MyLightningModel(pl.LightningModule):
def __init__(self, args):
# similar as Pytorch nn.Module subclass __init__()
def ahead(self, x):
# similar as Pytorch nn.Module subclass ahead()
def training_step(self, batch, batch_idx):
x, y = batch
logits = self.ahead(x)
loss = loss_fn(logits, y)
acc = self.train_acc(logits, y)
return loss
def configure_optimizers(self):
return self.optimizer
mannequin = MyLightningModel()
coach = pl.Coach(gpus=1)
coach.match(mannequin, dataloader)
|
If you concentrate on it, this occasion loop technique utilized by Lightning’s coach.match() is just about how Keras manages to transform its coaching loop to a single line mannequin.match() name as effectively, its many parameters performing because the callbacks that management the coaching conduct. Pytorch Lightning is only a bit extra express (and okay, a bit extra verbose) about it. In impact, each libraries have options that handle the opposite’s ache factors, so the one cause you’ll select one or the opposite is private or company choice.
Along with callbacks for every of coaching, validation, and take a look at steps, there are further callbacks for every of those steps that can be known as on the finish of every step and epoch, for instance: training_epoch_end() and training_step_end(). One other good facet impact of adopting one thing like Pytorch Lightning is that you just get a few of the default performance of the occasion loop without cost. For instance, logging is finished to Tensorboard by default, and progress bars are managed utilizing TQDM. Lastly, (and that’s the raison d’etre for Pytorch Lightning from the perspective of its builders) it helps you arrange your Pytorch code.
To get acquainted with Pytorch Lightning, I took three of my outdated notebooks, every coping with coaching one main kind of Neural Community structure (from the outdated days) — a completely related, convolutional, and recurrent community, and transformed it to make use of Pytorch Lightning. Chances are you’ll discover it helpful to take a look at, along with Pytorch Lightning’s intensive documentation, together with hyperlinks to them under.

{kind=link}