
A while again, I discovered myself considering of various knowledge augmentation methods for unbalanced datasets, i.e. datasets by which a number of courses are over-represented in comparison with the others, and questioning how these methods stack as much as each other. So I made a decision to arrange a easy experiment to check them. This submit describes the experiment and its outcomes.
The dataset I selected for this experiment was the SMS Spam Assortment Dataset from Kaggle, a group of virtually 5600 textual content messages, consisting of 4825 (87%) ham and 747 (13%) spam messages. The community is an easy 3 layer totally linked community (FCN), whose enter is a 512 factor vector generated utilizing the Google Common Sentence Encoder (GUSE) in opposition to the textual content message, and outputs the argmax of a 2 factor vector (representing “ham” or “spam”). The textual content augmentation methods I thought of in my experiment are as follows:
- Baseline — it is a baseline for outcome comparability. For the reason that process is binary classification, the metric we selected is Accuracy. We practice the community for 10 epochs utilizing Cross Entropy and the AdamW Optimizer with a studying price of 1e-3.
- Class Weights — Class Weights try to deal with knowledge imbalance by giving extra weight to the minority class. Right here we assign class weights to our optimizer proportional to the inverse of their counts within the coaching knowledge.
- Undersampling Majority Class — on this situation, we pattern from the bulk class the variety of information within the minority class, and solely use the sampled subset of the bulk class plus the minority class for our coaching.
- Oversampling Minority Class — that is the other situation, the place we pattern (with alternative) from the minority class a variety of information which are equal to the quantity within the majority class. The sampled set will include repetitions. We then use the sampled set plus the bulk class for coaching.
- SMOTE — it is a variant on the earlier technique of oversampling the minority class. SMOTE (Artificial Minority Oversampling TEchnique) ensures extra heterogeneity within the oversampled minority class by creating artificial information by interpolating between actual information. SMOTE wants the enter knowledge to be vectorized.
- Textual content Augmentation — like the 2 earlier approaches, that is one other oversampling technique. Heuristics and ontologies are used to make modifications to the enter textual content preserving its which means so far as doable. I used the TextAttack, a Python library for textual content augmentation (and producing examples for adversarial assaults).
A couple of factors to notice right here.
First, all of the sampling strategies, i.e., all of the methods listed above aside from the Baseline and Class Weights, requires you to separate your coaching knowledge into coaching, validation, and take a look at splits, earlier than they’re utilized. Additionally, the sampling needs to be completed solely on the coaching break up. In any other case, you danger knowledge leakage, the place the augmented knowledge leaks into the validation and take a look at splits, supplying you with very optimistic outcomes throughout mannequin improvement which is able to invariably not maintain as you progress your mannequin into manufacturing.
Second, augmenting your knowledge utilizing SMOTE can solely be completed on vectorized knowledge, because the thought is to search out and use factors in function hyperspace which are “in-between” your present knowledge. Due to this, I made a decision to pre-vectorize my textual content inputs utilizing GUSE. Different augmentation approaches thought of right here do not want the enter to be pre-vectorized.
The code for this experiment is split into two notebooks.
- blog_text_augment_01.ipynb — On this pocket book, I break up the dataset right into a practice/validation/take a look at break up of 70/10/20, and generate vector representations for every textual content message utilizing GUSE. I additionally oversample the minority class (spam) by producing roughly 5 augmentations for every report, and generate their vector representations as properly.
- blog_text_augment_02.ipynb — I outline a typical community, which I retrain utilizing Pytorch for every of the 6 augmentation situations listed above, and evaluate their accuracies.
Outcomes are proven beneath, and appear to point that oversampling methods are inclined to work one of the best, each the naive one and the one primarily based on SMOTE. The following best option appears to be class weights. This appears comprehensible as a result of oversampling offers the community probably the most knowledge to coach with. That’s most likely additionally why undersampling would not work properly. I used to be a bit shocked additionally that textual content augmentation methods didn’t carry out in addition to the opposite oversampling methods.
 |
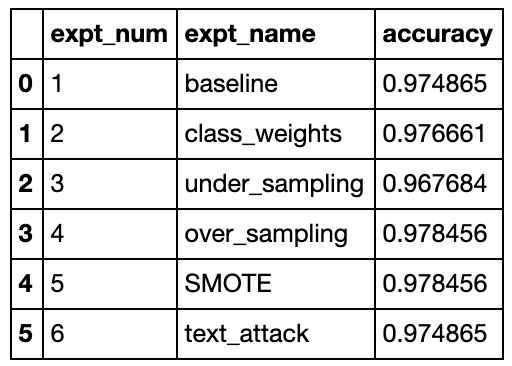 |
Nonetheless, the variations listed here are fairly small and presumably probably not vital (observe the y-axis within the bar chart is exagerrated (0.95 to 1.0) to focus on this distinction). I additionally discovered that the outcomes different throughout a number of runs, most likely ensuing from totally different initialization situations. However general the sample proven above was the commonest.
Edit 2021-02-13: @Yorko urged utilizing confidence intervals with the intention to tackle my above concern (see feedback beneath), so I collected the outcomes from 10 runs and computed the imply and customary deviation for every strategy throughout all of the runs. The up to date bar chart above reveals the imply worth and has error bars of +/- 2 customary deviations off the imply outcome. Due to the error bars, we are able to now draw just a few extra conclusions. First, we observe that SMOTE oversampling can certainly give higher outcomes than naive oversampling. It additionally reveals that undersampling outcomes will be very extremely variable.

{kind=link}