Over the past years, fashions in NLP have change into far more highly effective, pushed by advances in switch studying. A consequence of this drastic improve in efficiency is that present benchmarks have been left behind. Current fashions “have outpaced the benchmarks to check for them” (AI Index Report 2021), shortly reaching super-human efficiency on commonplace benchmarks equivalent to SuperGLUE and SQuAD. Does this imply that we have now solved pure language processing? Removed from it.
Nevertheless, the normal practices for evaluating efficiency of NLP fashions, utilizing a single metric equivalent to accuracy or BLEU, counting on static benchmarks and summary activity formulations now not work as effectively in mild of fashions’ surprisingly sturdy superficial pure language understanding means. We thus have to rethink how we design our benchmarks and consider our fashions in order that they’ll nonetheless function helpful indicators of progress going ahead.
This put up goals to offer an outline of challenges and alternatives in benchmarking in NLP, along with some basic suggestions. I attempted to cowl views from current papers, talks at ACL 2021 in addition to on the ACL 2021 Workshop on Benchmarking: Previous, Current and Future, along with a few of my very own ideas.
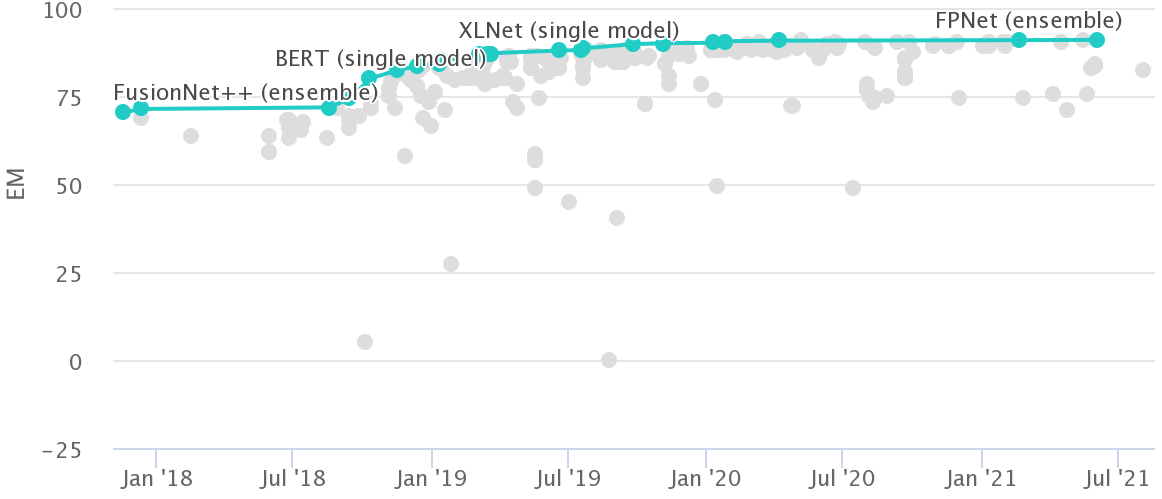
Header picture: Efficiency on SQuAD 2.0 over time (Credit score: Papers with Code)
Desk of contents:
What’s a benchmark?
“Datasets are the telescopes of our area.”—Aravind Joshi
The unique use of the time period refers to horizontal marks made by surveyors in stone buildings, into which an angle-iron could possibly be positioned to type a “bench” for a leveling rod. Figuratively, a benchmark refers to a normal level of reference in opposition to which issues may be in contrast. A benchmark as it’s utilized in ML or NLP sometimes has a number of parts: it consists of 1 or a number of datasets, one or a number of related metrics, and a technique to combination efficiency.
A benchmark units a normal for assessing the efficiency of various programs that’s agreed upon by the group. To make sure that a benchmark is accepted by the group, many current benchmarks both choose a consultant set of ordinary duties, equivalent to GLUE or XTREME or actively solicit activity proposals from the group, equivalent to SuperGLUE, GEM, or BIG-Bench.
For individuals within the area, benchmarks are essential instruments to trace progress. Aravind Joshi mentioned that with out benchmarks to evaluate the efficiency of our fashions, we’re identical to “astronomers eager to see the celebs however refusing to construct telescopes”.
For practitioners and outsiders, benchmarks present an goal lens right into a area that allows them to determine helpful fashions and hold monitor of a area’s progress. As an illustration, the AI Index Report 2021 makes use of SuperGLUE and SQuAD as a proxy for general progress in pure language processing.
Reaching human efficiency on influential benchmarks is usually seen as a key milestone for a area. AlphaFold 2 reaching efficiency aggressive with experimental strategies on the CASP 14 competitors marked a main scientific advance within the area of structural biology.
A short historical past of benchmarking
“Creating good benchmarks is tougher than most think about.”—John R. Mashey; foreword to Methods Benchmarking (2020)
Benchmarks have a protracted historical past of getting used to evaluate the efficiency of computational programs. The Normal Efficiency Analysis Company (SPEC), established in 1988 is among the oldest organisations devoted to benchmarking the efficiency of pc {hardware}. Crucially, SPEC had assist from most necessary corporations within the area. Yearly, it might launch totally different benchmark units, every composed of a number of packages, with efficiency measured because the geometric imply of thousands and thousands of directions per second (MIPS).
A current ML-specific analogue to SPEC is MLCommons, which organises the MLPerf collection of efficiency benchmarks specializing in mannequin coaching and inference. Just like SPEC, MLPerf has a broad base of assist from academia and business, constructing on earlier particular person efforts for measuring efficiency equivalent to DeepBench by Baidu or DAWNBench by Stanford.
For US companies equivalent to DARPA and NIST, benchmarks performed an important position in measuring and monitoring scientific progress. Early benchmarks for computerized speech recognition (ASR) equivalent to TIMIT and Switchboard have been funded by DARPA and coordinated by NIST beginning in 1986. Later influential benchmarks in different areas of ML equivalent to MNIST have been additionally based mostly on NIST information.
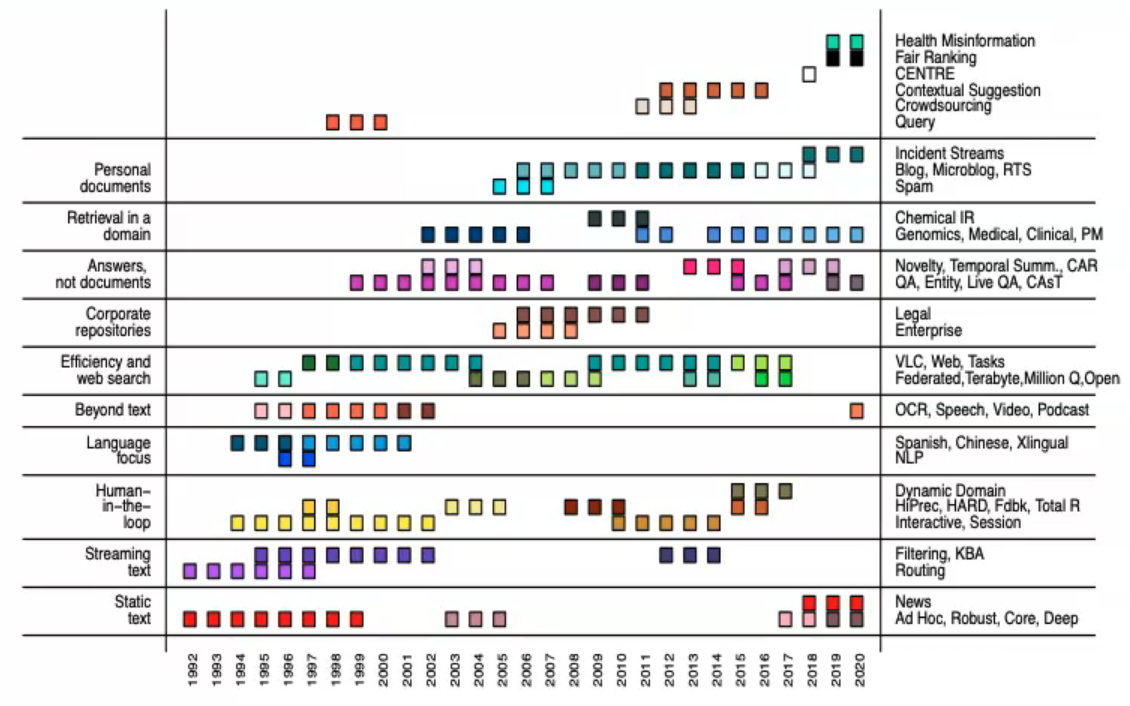
For language expertise and knowledge retrieval (IR), NIST ran the DARPA-funded TREC collection of workshops overlaying a big selection of tracks and subjects, which may be seen beneath. TREC organised competitions constructed on an analysis paradigm pioneered by Cranfield within the Sixties the place fashions are evaluated based mostly on a set of take a look at collections, consisting of paperwork, questions, and human relevance judgements. Because the variance in efficiency throughout subjects is giant, scores are averaged over many subjects. TREC’s “commonplace, broadly out there, and thoroughly constructed set of information laid the groundwork for additional innovation” (Varian, 2008) in IR.
Many current influential benchmarks equivalent to ImageNet, SQuAD, or SNLI are giant in scale, consisting of a whole bunch of hundreds of examples and have been developed by educational teams at well-funded universities. Within the period of deep studying, such large-scale datasets have been credited as one of many pillars driving progress in analysis, with fields equivalent to NLP or biology witnessing their ‘ImageNet second’.
As fashions have change into extra highly effective and general-purpose, benchmarks have change into extra application-oriented and more and more moved from single-task to multi-task and single-domain to multi-domain benchmarks. Key examples of those developments are a transition from a give attention to core linguistic duties equivalent to part-of-speech tagging and dependency parsing to duties which are nearer to the real-world equivalent to goal-oriented dialogue and open-domain query answering (Kwiatkowski et al., 2019); the emergence of multi-task datasets equivalent to GLUE; and multi-modality datasets equivalent to WILDS.
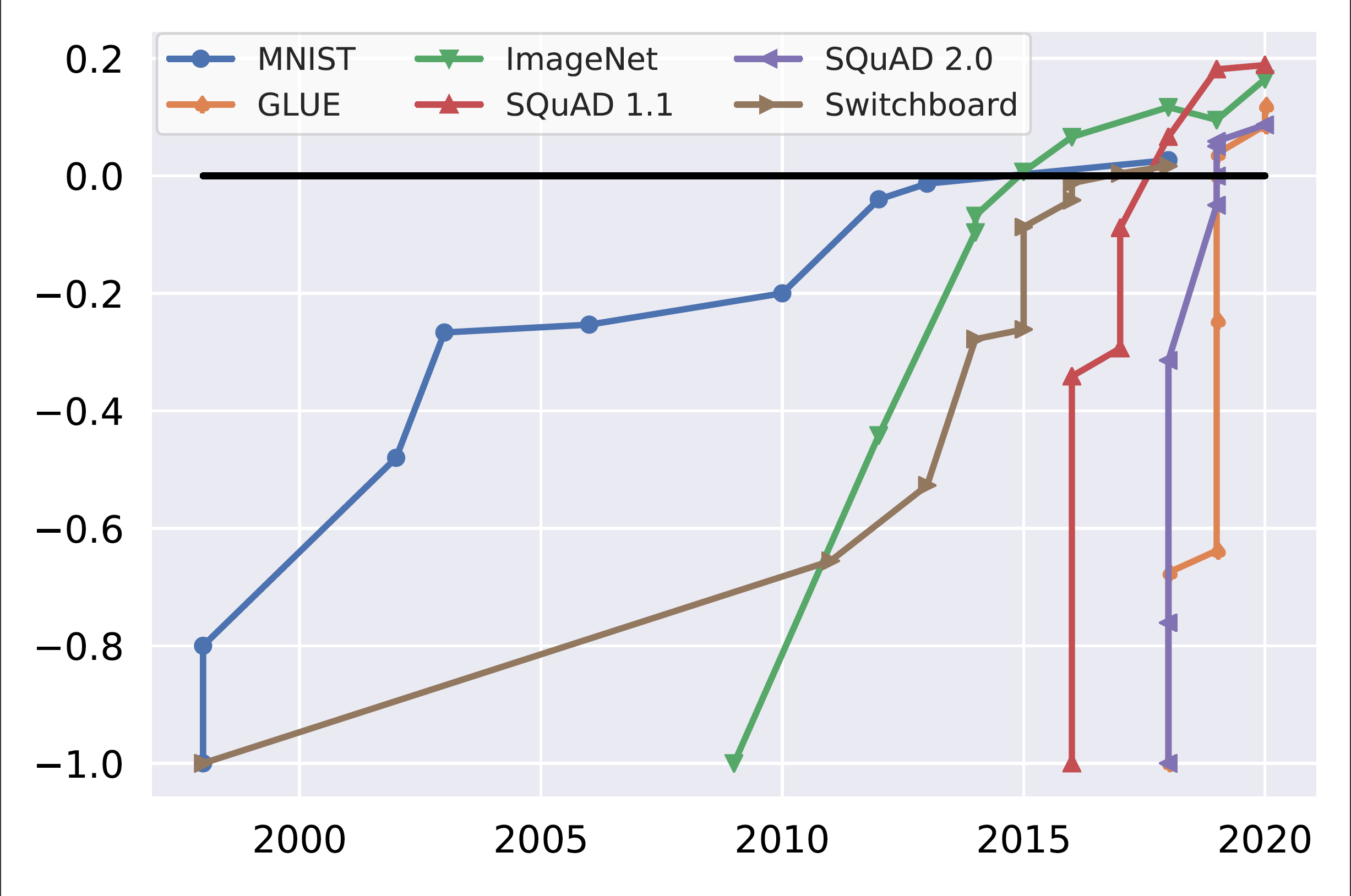
Nevertheless, whereas it took greater than 15 years to attain superhuman efficiency on basic benchmarks equivalent to MNIST or Switchboard, fashions have achieved superhuman efficiency on more moderen benchmarks equivalent to GLUE and SQuAD 2.0 inside a few yr of their launch, as may be seen within the determine beneath. On the identical time, we all know that the capabilities that these benchmarks goal to check, equivalent to basic query answering are removed from being solved.
One other issue that has contributed to the saturation of those benchmarks is that limitations and annotation artefacts of current datasets have been recognized far more shortly in comparison with earlier benchmarks. In SNLI, annotators have been proven to depend on heuristics, which permit fashions to make the right prediction in lots of circumstances utilizing the speculation alone (Gururangan et al., 2018) whereas fashions educated on SQuAD are topic to adversarially inserted sentences (Jia and Liang, 2017).
A current pattern is the event of adversarial datasets equivalent to Adversarial NLI (Nie et al., 2020), Beat the AI (Bartolo et al., 2020), and others the place examples are created to be tough for present fashions. Dynabench (Kiela et al., 2021), a current open-source platform has been designed to facilitate the creation of such datasets. A good thing about such benchmarks is that they are often dynamically up to date to be difficult as new fashions emerge and consequently don’t saturate as simply as static benchmarks.
Metrics matter
“When you may measure what you’re talking of and specific it in numbers, you realize that on which you’re discussing. However while you can’t measure it and specific it in numbers, your information is of a really meagre and unsatisfactory variety.”—Lord Kelvin
On the subject of measuring efficiency, metrics play an necessary and infrequently under-appreciated position. For classification duties, accuracy or F-score metrics might look like the plain alternative however—relying on the applying—various kinds of errors incur totally different prices. For fine-grained sentiment evaluation, complicated between constructive and very constructive is probably not problematic whereas mixing up very constructive and very detrimental is. Chris Potts highlights an array of sensible examples the place metrics like F-score fall brief, many in eventualities the place errors are far more pricey.
Designing a superb metric requires area experience. MLPerf measures the wallclock time required to coach a mannequin to a dataset-specific efficiency goal, a measure knowledgeable by each finish use circumstances and the issue to match different effectivity metrics equivalent to FLOPS throughout fashions. In ASR, solely the share of appropriately transcribed phrases (akin to accuracy) was initially used because the metric. The group later settled on phrase error charge, i.e. $frac{textual content{substitutions} + textual content{deletions} + textual content{insertions}}{textual content{variety of phrases in reference}}$ because it immediately displays the price of correcting transcription errors.
There’s a giant distinction between metrics designed for decades-long analysis and metrics designed for near-term growth of sensible purposes, as highlighted by Mark Liberman. For growing decade-scale expertise, we’d like environment friendly metrics that may be crude so long as they level within the basic route of our distant purpose. Examples of such metrics are the phrase error charge in ASR (which assumes that each one phrases are equally necessary) and BLEU in machine translation (which assumes that phrase order shouldn’t be necessary). In distinction, for the analysis of sensible expertise we’d like metrics which are designed with the necessities of particular purposes in thoughts and that may take into account various kinds of error courses.
The fast improve in mannequin efficiency lately has catapulted us from the decade-long to the near-term regime for a lot of purposes. Nevertheless, even on this extra application-oriented setting we’re nonetheless counting on the identical metrics that we have now used to measure long-term analysis progress to this point. In a current meta-analysis, Marie et al. (2021) discovered that 82% papers of machine translation (MT) papers between 2019–2020 solely consider on BLEU—regardless of 108 different metrics having been proposed for MT analysis within the final decade, lots of which correlate higher with human judgements. As fashions change into stronger, metrics like BLEU are now not in a position to precisely determine and examine the best-performing fashions.
Whereas analysis of pure language technology (NLG) fashions is notoriously tough, commonplace n-gram overlap-based metrics equivalent to ROUGE or BLEU are moreover much less suited to languages with wealthy morphology, which will probably be assigned comparatively decrease scores.
A current pattern in NLG is in the direction of the event of computerized metrics equivalent to BERTScore (Zhang et al., 2020) that leverage the facility of huge pre-trained fashions. A current modification of this technique makes it extra appropriate for near-term MT analysis by assigning bigger weights to tougher tokens, i.e. tokens which are translated appropriately solely by few MT programs (Zhan et al., 2021).
As a way to proceed to make progress, we’d like to have the ability to replace and refine our metrics, to interchange environment friendly simplified metrics with application-specific ones. The current GEM benchmark, for example, explicitly consists of metrics as a element that must be improved over time, as may be seen beneath.
Suggestions:
- Think about metrics which are higher suited to the downstream activity and language.
- Think about metrics that spotlight the trade-offs of the downstream setting.
- Replace and refine metrics over time.
Think about the downstream use case
“[…] benchmarks form a area, for higher or worse. Good benchmarks are in alignment with actual purposes, however dangerous benchmarks are usually not, forcing engineers to decide on between making adjustments that assist finish customers or making adjustments that solely assist with advertising.”—David A. Patterson; foreword to Methods Benchmarking (2020)
NLP expertise is more and more utilized in many real-world utility areas, from artistic self-expression to fraud detection and suggestion. It’s thus key to design benchmarks with such real-world settings in thoughts.
A benchmark’s information composition and analysis protocol ought to mirror the real-world use case, as highlighted by Ido Dagan. For relation classification, for example, the FewRel dataset lacks some necessary reasonable properties, which Few-shot TACRED addresses. For binary sentiment classification on the IMDb dataset, solely extremely polarised constructive and detrimental critiques are thought of and labels are precisely balanced. In data retrieval, retrieving related earlier than non-relevant paperwork is essential however not enough for real-world utilization.
As a primary rule of social accountability for NLP, Chris Potts proposes “Do precisely what you mentioned you’d do”. As researchers within the area, we should always talk clearly what efficiency on a benchmark displays and the way this corresponds to real-world settings. In an identical vein, Bowman and Dahl (2021) argue that good efficiency on a benchmark ought to suggest sturdy in-domain efficiency on the duty.
Nevertheless, the real-world utility of a activity might confront the mannequin with information totally different from its coaching distribution. It’s thus key to evaluate the robustness of the mannequin and the way effectively it generalises to such out-of-distribution information, together with information with a temporal shift and information from different language varieties.
In mild of the restricted linguistic range in NLP analysis (Joshi et al., 2020), it’s moreover essential to not deal with English because the singular language for analysis. When designing a benchmark, amassing—at a minimal—take a look at information in different languages might assist to spotlight new challenges and promote language inclusion. Equally, when evaluating fashions, leveraging the growing variety of non-English language datasets in duties equivalent to query answering and summarisation (Hasan et al., 2021) can present extra proof of a mannequin’s versatility.
In the end, contemplating the challenges of present and future real-world purposes of language expertise might present inspiration for a lot of new evaluations and benchmarks. Benchmarks are among the many most impactful artefacts of our area and infrequently result in solely new analysis instructions, so it’s essential for them to mirror real-world and doubtlessly bold use circumstances of our expertise.
Suggestions:
- Design the benchmark and its analysis in order that it displays the real-world use case.
- Consider in-domain and out-of-domain generalisation.
- Accumulate information and consider fashions on different languages.
- Take inspiration from real-world purposes of language expertise.
Superb-grained analysis
“Irrespective of how a lot individuals need efficiency to be a single quantity, even the proper imply with no distribution may be deceptive, and the unsuitable imply definitely isn’t any higher.”—John R. Mashey
The downstream use case of expertise also needs to inform the metrics we use for analysis. Particularly, for downstream purposes usually not a single metric however an array of constraints have to be thought of. Rada Mihalcea requires shifting away from simply specializing in accuracy and to give attention to different necessary elements of real-world eventualities. What’s necessary in a specific setting, in different phrases, the utility of an NLP system, finally depends upon the necessities of every particular person consumer (Ethayarajh and Jurafsky, 2020).
Societal wants have typically not been emphasised in machine studying analysis (Birhane et al., 2021). Nevertheless, for real-world purposes it’s significantly essential {that a} mannequin doesn’t exhibit any dangerous social biases. Testing for such biases in a task-specific method ought to thus change into a normal a part of algorithm growth and mannequin analysis.
One other facet that’s necessary for sensible purposes is effectivity. Relying on the applying, this may relate to each pattern effectivity, FLOPS, and reminiscence constraints. Evaluating fashions in resource-constrained settings can usually result in new analysis instructions. As an illustration, the EfficientQA competitors (Min et al., 2020) at NeurIPS 2020 demonstrated the advantages of retrieval augmentation and enormous collections of weakly supervised query–reply pairs (Lewis et al., 2021).
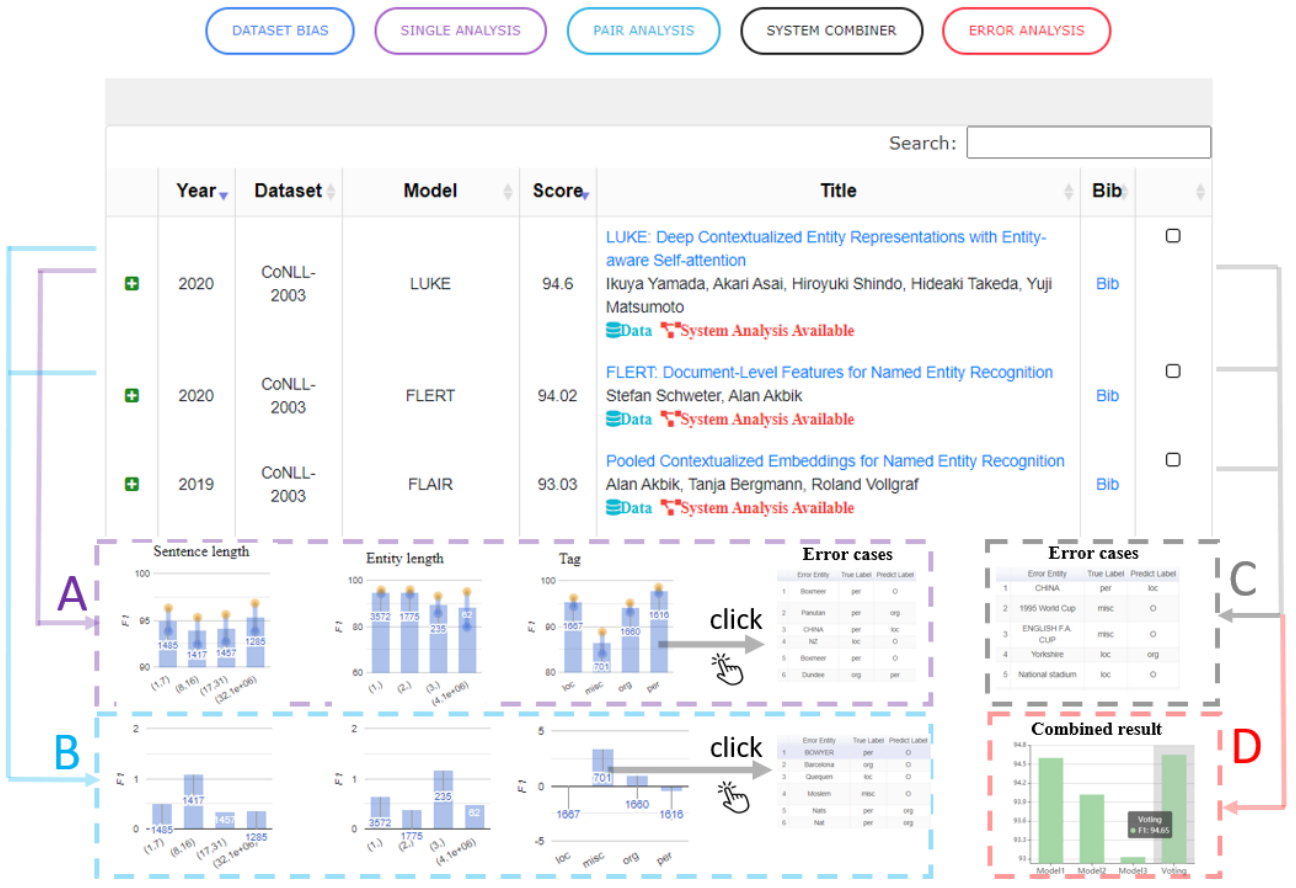
As a way to higher perceive the strengths and weaknesses of our fashions, we moreover require extra fine-grained analysis throughout a single metric, highlighting on what varieties of examples fashions excel and fail at. ExplainaBoard (Liu et al., 2021) implements such a fine-grained breakdown of mannequin efficiency throughout totally different duties, which may be seen beneath. One other technique to acquire a extra fine-grained estimate of mannequin efficiency is to create take a look at circumstances for particular phenomena and mannequin behaviour, for example utilizing the CheckList framework (Ribeiro et al., 2020).
As particular person metrics may be flawed, it’s key to guage throughout a number of metrics. When evaluating on a number of metrics, scores are sometimes averaged to acquire a single rating. A single rating is helpful to match fashions at a look and gives individuals outdoors the group a transparent technique to assess mannequin efficiency. Nevertheless, utilizing the arithmetic imply shouldn’t be applicable for all functions. SPEC used the geometric imply, $sqrt[leftroot{-2}uproot{2}n]{x_1 x_2 ldots x_n}$, which is helpful when aggregating values which are exponential in nature, equivalent to runtimes.
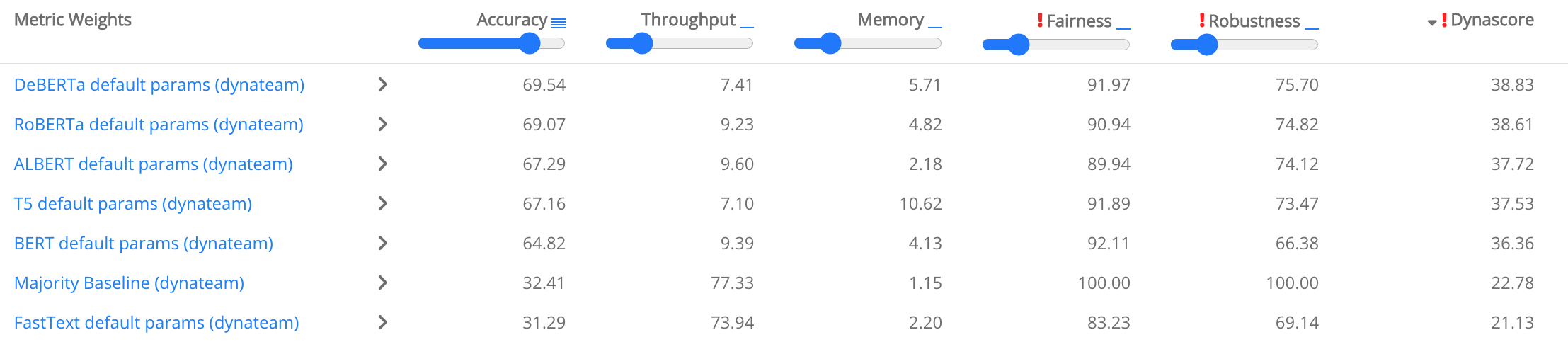
Another is to make use of a weighted sum and to allow the consumer to outline their very own weights for every element. DynaBench makes use of such a dynamic weighting to weight the significance of mannequin efficiency but additionally take into account mannequin throughput, reminiscence consumption, equity, and robustness, which permits customers to successfully outline their very own leaderboard (Ethayarajh and Jurafsky, 2020), as may be seen beneath.
Suggestions:
- Transfer away from utilizing a single metric for efficiency analysis.
- Consider social bias and effectivity.
- Carry out a fine-grained analysis of fashions.
- Think about how one can combination a number of metrics.
The lengthy tail of benchmark efficiency
Provided that present fashions carry out surprisingly effectively on in-distribution examples, it’s time to shift our consideration to the tail of the distribution, to outliers and atypical examples. Reasonably than contemplating solely the common case, we should always care extra in regards to the worst case and subsets of our information the place our fashions carry out the worst.
As fashions change into extra highly effective, the fraction of examples the place the efficiency of fashions differs and that thus will be capable of differentiate between sturdy and the perfect fashions will develop smaller. To make sure that analysis on this lengthy tail of examples is dependable, benchmarks have to be giant sufficient in order that small variations in efficiency may be detected. It is very important notice that bigger fashions are usually not uniformly higher throughout all examples (Zhong et al., 2021).
As a substitute, we will develop mechanisms that enable us to determine the perfect programs with few examples. That is significantly essential in settings the place assessing efficiency of many programs is pricey, equivalent to in human analysis for pure language technology. Mendonça et al. (2021) body this as a web-based studying downside within the context of MT.
Benchmarks also can give attention to annotating examples which are far more difficult. That is the route taken by current adversarial benchmarks (Kiela et al., 2021). Such benchmarks, so long as they don’t seem to be biased in the direction of a particular mannequin, is usually a helpful complement to common benchmarks that pattern from the pure distribution. These instructions profit from the event of lively analysis strategies to determine or generate essentially the most salient and discriminative examples to evaluate mannequin efficiency in addition to interpretability strategies to permit annotators to higher perceive fashions’ determination boundaries.
Because the finances (and thus dimension) of benchmarks typically stays fixed, statistical significance testing turns into much more necessary because it permits us to reliably detect qualitatively related efficiency variations between programs.
As a way to carry out dependable comparisons, the benchmark’s annotations must be right and dependable. Nevertheless, as fashions change into extra highly effective, many situations of what seem like mannequin errors could also be real examples of ambiguity within the information. Bowman and Dahl (2021) spotlight how a mannequin might exploit clues about such disagreements to achieve super-human efficiency on a benchmark.
If potential, benchmarks ought to goal to gather a number of annotations to determine ambiguous examples. Such data might present a helpful studying sign (Plank et al., 2014) and may be useful for error evaluation. In mild of such ambiguity, it’s much more necessary to report commonplace metrics equivalent to inter-annotator settlement as this gives a ceiling for a mannequin’s efficiency on a benchmark.
Suggestions:
- Embody many and/or arduous examples within the benchmark.
- Conduct statistical significance testing.
- Accumulate a number of annotations for ambiguous examples.
- Report inter-annotator settlement.
Massive-scale steady analysis
“When a measure turns into a goal, it ceases to be a superb measure.”—Goodhart’s legislation
Multi-task benchmarks equivalent to GLUE have change into key indicators of progress however such static benchmark collections shortly change into outdated. Modelling advances typically additionally don’t result in uniform progress throughout duties. Whereas fashions have achieved super-human efficiency on most GLUE duties, a spot to 5-way human settlement stays on some duties equivalent to CoLA (Nangia and Bowman, 2019). On XTREME, fashions have improved far more on cross-lingual retrieval.
In mild of the quick tempo of mannequin enhancements, we’re in want of extra nimble mechanisms for mannequin analysis. Particularly, past dynamic single-task evaluations equivalent to DynaBench, it might be helpful to outline a dynamic assortment of benchmark datasets on which fashions haven’t reached human efficiency. This assortment must be managed by the group, with datasets eliminated or down-weighted as fashions attain human efficiency and new difficult datasets being usually added. Such a group must be versioned, to allow updates past the cycle of educational evaluate and to allow replicability and comparability to prior approaches.
Present multi-task benchmarks equivalent to GEM (Gehrmann et al., 2021), which explicitly goals to be a ‘residing’ benchmark, typically embody round 10–15 totally different duties. Reasonably than limiting the benchmark to a small assortment of consultant duties, in mild of the variety of new datasets consistently being launched, it could be extra helpful to incorporate a bigger cross-section of NLP duties. Given the various nature of duties in NLP, this would supply a extra sturdy and up-to-date analysis of mannequin efficiency. LUGE by Baidu is a step in the direction of such a big assortment of duties for Chinese language pure language processing, at present consisting of 28 datasets.
The gathering of duties may be damaged down in numerous methods, offering extra a fine-grained evaluation of mannequin capabilities. Such a breakdown could also be significantly insightful if duties or subsets of activity information are categorised based on the behaviour they’re testing. BIG-Bench, a current collaborative benchmark for language mannequin probing features a categorisation by key phrase.
A key problem for such large-scale multi-task analysis is accessibility. Duties have to be out there in a standard enter format in order that they are often run simply. As well as, duties must be environment friendly to run or alternatively infrastructure must be out there to run duties even with out a lot compute.
One other level of consideration is that such a group favours giant general-purpose fashions, that are typically educated by deep-pocketed corporations or establishments. Such fashions, nonetheless, are already used as the place to begin for many present analysis efforts and may be—as soon as educated—extra effectively used by way of fine-tuning, distillation, or pruning.
Suggestions:
- Think about amassing and evaluating on a big, numerous, versioned assortment of NLP duties.
Conclusion
As a way to sustain with advances in modelling, we have to revisit many tacitly accepted benchmarking practices equivalent to counting on simplistic metrics like F1-score and BLEU. To this finish, we should always take inspiration from real-world purposes of language expertise and take into account the constraints and necessities that such settings pose for our fashions. We also needs to care extra in regards to the lengthy tail of the distribution as that’s the place enhancements will probably be noticed for a lot of purposes. Lastly, we must be extra rigorous within the analysis on our fashions and depend on a number of metrics and statistical significance testing, opposite to present developments.
Quotation
For attribution in educational contexts, please cite this work as:
@misc{ruder2021benchmarking,
creator = {Ruder, Sebastian},
title = {{Challenges and Alternatives in NLP Benchmarking}},
yr = {2021},
howpublished = {url{http://ruder.io/nlp-benchmarking}},
}

{kind=link}