
This publish gathers ten ML and NLP analysis instructions that I discovered thrilling and impactful in 2019.
For every spotlight, I summarise the principle advances that befell this 12 months, briefly state why I believe it is crucial, and supply a brief outlook to the long run.
The complete listing of highlights is right here:
- Common unsupervised pretraining
- Lottery tickets
- The Neural Tangent Kernel
- Unsupervised multilingual studying
- Extra strong benchmarks
- ML and NLP for science
- Fixing decoding errors in NLG
- Augmenting pretrained fashions
- Environment friendly and long-range Transformers
- Extra dependable evaluation strategies
What occurred? Unsupervised pretraining was prevalent in NLP this 12 months, primarily pushed by BERT (Devlin et al., 2019) and different variants. A complete vary of BERT variants have been utilized to multimodal settings, largely involving photos and movies along with textual content (for an instance see the determine under). Unsupervised pretraining has additionally made inroads into domains the place supervision had beforehand reigned supreme. In biology, Transformer language fashions have been pretrained on protein sequences (Rives et al., 2019). In pc imaginative and prescient, approaches leveraged self-supervision together with CPC (Hénaff et al., 2019), MoCo (He et al., 2019), and PIRL (Misra & van der Maaten, 2019) in addition to robust turbines corresponding to BigBiGAN (Donahue & Simonyan, 2019) to enhance pattern effectivity on ImageNet and picture era. In speech, representations discovered with a multi-layer CNN (Schneider et al., 2019) or bidirectional CPC (Kawakami et al., 2019) outperform state-of-the-art fashions with a lot much less coaching information.
Why is it essential? Unsupervised pretraining permits coaching fashions with a lot fewer labelled examples. This opens up new purposes in many various domains the place information necessities have been beforehand prohibitive.
What’s subsequent? Unsupervised pretraining is right here to remain. Whereas the largest advances have been achieved thus far in particular person domains, it is going to be fascinating to see a spotlight in the direction of tighter integration of a number of modalities.

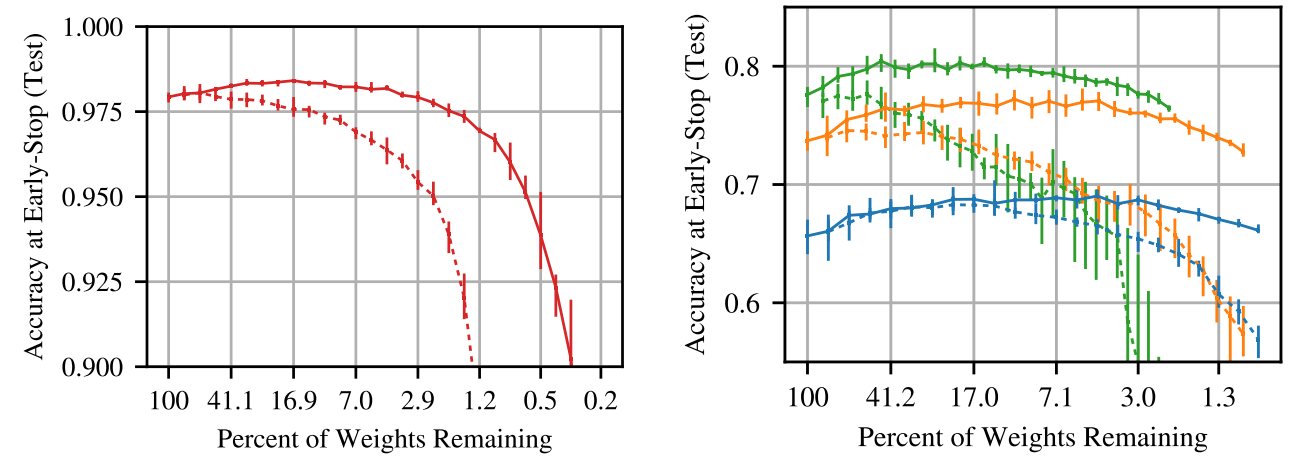
What occurred? Frankle and Carbin (2019) recognized successful tickets, subnetworks in dense, randomly-initialised, feed-forward networks which can be so effectively initialised that coaching them in isolation achieves comparable accuracy to coaching the complete community, as will be seen under. Whereas the preliminary pruning process solely labored on small imaginative and prescient duties, later work (Frankle et al., 2019) utilized the pruning early in coaching as a substitute of at initialisation, which makes it potential to search out small subnetworks of deeper fashions. Yu et al. (2019) discover successful ticket initialisations additionally for LSTMs and Transformers in NLP and RL fashions. Whereas successful tickets are nonetheless costly to search out, it’s promising that they appear to be transferable throughout datasets and optimisers (Morcos et al., 2019) and domains (Desai et al., 2019).
Why is it essential? State-of-the-art neural networks are getting bigger and dearer to coach and to make use of for prediction. With the ability to constantly determine small subnetworks that obtain comparable efficiency permits coaching and inference with a lot fewer assets. This may velocity up mannequin iteration and opens up new purposes in on-device and edge computing.
What’s subsequent? Figuring out successful tickets is presently nonetheless too costly to offer actual advantages in low-resource settings. Extra strong one-shot pruning strategies which can be much less prone to noise within the pruning course of ought to mitigate this. Investigating what makes successful tickets particular also needs to assist us acquire a greater understanding of the initialisation and studying dynamics of neural networks.
What occurred? Considerably counter-intuitively, very vast (extra concretely, infinitely vast) neural networks are simpler to check theoretically than slim ones. It has been proven that within the infinite-width restrict, neural networks will be approximated as linear fashions with a kernel, the Neural Tangent Kernel (NTK; Jacot et al., 2018). Consult with this publish for an intuitive rationalization of NTK together with an illustration of its coaching dynamics (see the determine under). In follow, such fashions, have underperformed their finite-depth counterparts (Novak et al., 2019; Allen-Zhu et al., 2019; Bietti & Mairal, 2019), which limits making use of the findings to straightforward strategies. Latest work (Li et al., 2019; Arora et al., 2019), nevertheless, has considerably lowered the efficiency hole to straightforward strategies (see Chip Huyen’s publish for different associated NeurIPS 2019 papers).
Why is it essential? The NTK is probably probably the most highly effective instrument at our disposal to analyse the theoretical behaviour of neural networks. Whereas it has its limitations, i.e. sensible neural networks nonetheless carry out higher than their NTK counterparts, and insights thus far haven’t translated into empirical positive factors, it might assist us open the black field of deep studying.
What’s subsequent? The hole to straightforward strategies appears to be primarily as a result of advantages of the finite width of such strategies, which future work could search to characterise. This may hopefully additionally assist translating insights from the infinite-width restrict to sensible settings. Finally, the NTK could assist us make clear the coaching dynamics and generalisation behaviour of neural networks.
What occurred? Cross-lingual representations had largely centered on the phrase stage for a few years (see this survey). Constructing on advances in unsupervised pretraining, this 12 months noticed the event of deep cross-lingual fashions corresponding to multilingual BERT, XLM (Conneau & Lample, 2019), and XLM-R (Conneau et al., 2019). Although these fashions don’t use any express cross-lingual sign, they generalise surprisingly effectively throughout languages—even and not using a shared vocabulary or joint coaching (Artetxe et al., 2019; Karthikeyan et al., 2019; Wu et al., 2019). For an summary, take a look at this publish. Such deep fashions additionally introduced enhancements in unsupervised MT (Music et al., 2019; Conneau & Lample, 2019), which hit its stride final 12 months (see highlights of 2018) and noticed enhancements from a extra principled mixture of statistical and neural approaches (Artetxe et al., 2019). One other thrilling improvement is the bootstrapping of deep multilingual fashions from available pretrained representations in English (Artetxe et al., 2019; Tran, 2020), which will be seen under.
Why is it essential? Prepared-to-use cross-lingual representations allow coaching of fashions with fewer examples for languages apart from English. Moreover, if labelled information in English is out there, these strategies allow basically free zero-shot switch. They could lastly assist us acquire a greater understanding of the relationships between totally different languages.
What’s subsequent? It’s nonetheless unclear why these strategies work so effectively with none cross-lingual supervision. Gaining a greater understanding of how these strategies work will doubtless allow us to design extra highly effective strategies and might also reveal insights concerning the construction of various languages. As well as, we must always not solely give attention to zero-shot switch but additionally think about studying from few labelled examples within the goal language (see this publish).
There’s something rotten within the state-of-the-art.
—Nie et al. (2019) paraphrasing Shakespeare
What occurred? Latest NLP datasets corresponding to HellaSWAG (Zellers et al., 2019) are created to be troublesome for state-of-the-art fashions to resolve. Examples are filtered by people to explicitly retain solely these the place state-of-the-art fashions fail (see under for an instance). This technique of human-in-the-loop adversarial curation will be repeated a number of instances corresponding to within the current Adversarial NLI (Nie et al., 2019) benchmark to allow the creation of datasets which can be rather more difficult for present strategies.
Why is it essential? Many researchers have noticed that present NLP fashions don’t be taught what they’re speculated to however as a substitute undertake shallow heuristics and exploit superficial cues within the information (described as the Intelligent Hans second). As datasets develop into extra strong, we might hope that fashions might be compelled to finally be taught the true underlying relations within the information.
What’s subsequent? As fashions develop into higher, most datasets will must be repeatedly improved or will rapidly develop into outdated. Devoted infrastructure and instruments might be essential to facilitate this course of. As well as, applicable baselines needs to be run together with easy strategies and fashions utilizing totally different variants of the info (corresponding to with incomplete enter) in order that preliminary variations of datasets are as strong as potential.

What occurred? There have been some main advances of ML being utilized to basic science issues. My highlights have been the appliance of deep neural networks to protein folding and to the Many-Electron Schrödinger Equation (Pfau et al., 2019). On the NLP aspect, it’s thrilling to see what influence even commonplace strategies can have when mixed with area experience. One examine used phrase embeddings to analyse latent information within the supplies science literature (Tshitoyan et al., 2019), which can be utilized to foretell which supplies may have sure properties (see the determine under). In biology, lots of information corresponding to genes and proteins is sequential in nature. It’s thus a pure match for NLP strategies corresponding to LSTMs and Transformers, which have been utilized to protein classification (Strodthoff et al., 2019; Rives et al., 2019).
Why is it essential? Science is arguably one of the impactful utility domains for ML. Options can have a big influence on many different domains and can assist resolve real-world issues.
What’s subsequent? From modelling power in physics issues (Greydanus et al., 2019) to fixing differential equations (Lample & Charton, 2020), ML strategies are continually being utilized to new purposes in science. It will likely be fascinating to see what probably the most impactful of those might be in 2020.
What occurred? Regardless of ever extra highly effective fashions, pure language era (NLG) fashions nonetheless continuously produce repetitions or gibberish as will be seen under. This was proven to be primarily a results of the utmost chance coaching. I used to be excited to see enhancements that intention to ameliorate this and are orthogonal to advances in modelling. Such enhancements got here within the type of new sampling strategies, corresponding to nucleus sampling (Holtzman et al., 2019) and new loss features (Welleck et al., 2019). One other shocking discovering was that higher search doesn’t result in higher generations: Present fashions rely to some extent on an imperfect search and beam search errors. In distinction, an actual search most frequently returns an empty translation within the case of machine translation (Stahlberg & Byrne, 2019). This reveals that advances in search and modelling should usually go hand in hand.
Why is it essential? Pure language era is among the most common duties in NLP. In NLP and ML analysis, most papers give attention to bettering the mannequin, whereas different components of the pipeline are usually uncared for. For NLG, you will need to remind ourselves that our fashions nonetheless have flaws and that it might be potential to enhance the output by fixing the search or the coaching course of.
What’s subsequent? Regardless of extra highly effective fashions and profitable purposes of switch studying to NLG (Music et al., 2019; Wolf et al., 2019), mannequin predictions nonetheless comprise many artefacts. Figuring out and understanding the causes of such artefacts is a crucial analysis course.

What occurred? I used to be excited to see approaches that equip pretrained fashions with new capabilities. Some strategies increase a pretrained mannequin with a information base in an effort to enhance modelling of entity names (Liu et al., 2019) and the recall of info (Logan et al., 2019). Others allow it to carry out easy arithmetic reasoning (Andor et al., 2019) by giving it entry to various predefined executable packages. As most fashions have a weak inductive bias and be taught most of their information from information, one other technique to prolong a pretrained mannequin is by augmenting the coaching information itself, e.g. to seize frequent sense (Bosselut et al., 2019) as will be seen under.
Why is it essential? Fashions have gotten extra highly effective however there are numerous issues {that a} mannequin can’t be taught from textual content alone. Notably when coping with extra advanced duties, the accessible information could also be too restricted to be taught express reasoning utilizing info or frequent sense and a stronger inductive bias could usually be essential.
What’s subsequent? As fashions are being utilized to tougher issues, it is going to more and more develop into essential for modifications to be compositional. Sooner or later, we’d mix highly effective pretrained fashions with learnable compositional packages (Pierrot et al., 2019).

What occurred? This 12 months noticed a number of enhancements to the Transformer (Vaswani et al., 2017) structure. The Transformer-XL (Dai et al., 2019) and the Compressive Transformer (Rae et al., 2020), which will be seen under allow it to higher seize long-range dependencies. Many approaches sought to make the Transformer extra environment friendly largely utilizing totally different—usually sparse—consideration mechanisms, corresponding to adaptively sparse consideration (Correia et al., 2019), adaptive consideration spans (Sukhbaatar et al., 2019), product-key consideration (Lample et al., 2019), and locality-sensitive hashing (Kitaev et al., 2020). On the Transformer-based pretraining entrance, there have been extra environment friendly variants corresponding to ALBERT (Lan et al., 2020), which employs parameter sharing and ELECTRA (Clark et al., 2020), which makes use of a extra environment friendly pretraining process. There have been additionally extra environment friendly pretrained fashions that didn’t utilise a Transformer, such because the unigram doc mannequin VAMPIRE (Gururangan et al., 2019) and the QRNN-based MultiFiT (Eisenschlos et al., 2019). One other pattern was the distillation of huge BERT fashions into smaller ones (Tang et al., 2019; Tsai et al., 2019; Sanh et al., 2019).
Why is it essential? The Transformer structure has been influential since its inception. It is part of most state-of-the-art fashions in NLP and has been efficiently utilized to many different domains (see Sections 1 and 6). Any enchancment to the Transformer structure could thus have robust ripple results.
What’s subsequent? It’ll take a while for these enhancements to trickle right down to the practitioner however given the prevalence and ease of use of pretrained fashions, extra environment friendly options will doubtless be adopted rapidly. General, we are going to hopefully see a unbroken give attention to mannequin architectures that emphasise effectivity, with sparsity being one of many key tendencies.
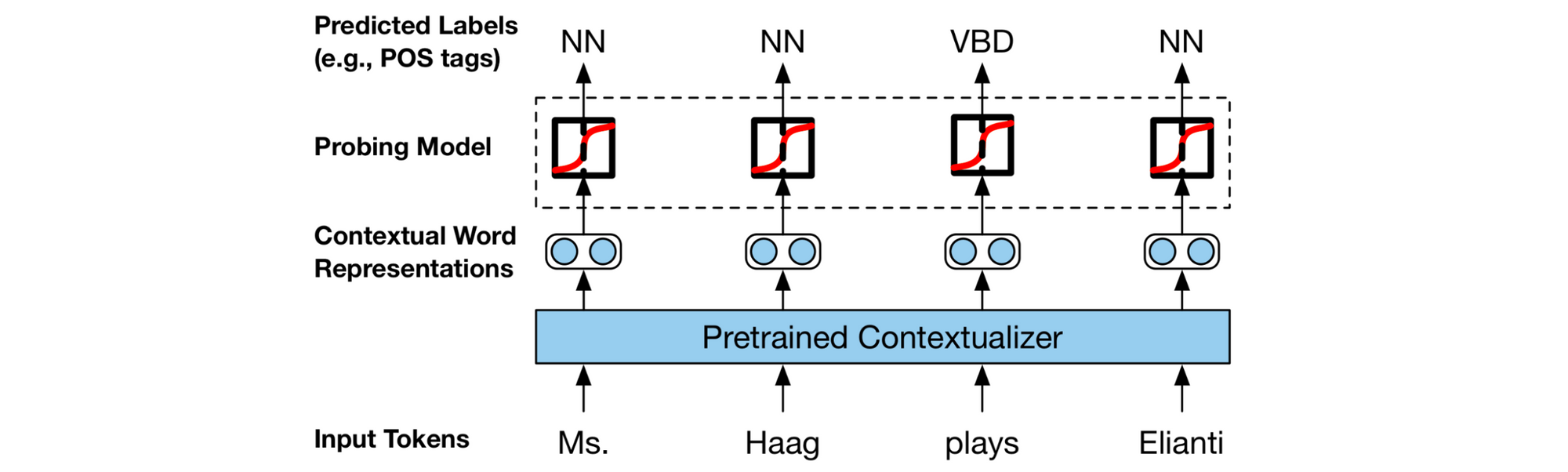
What occurred? A key pattern for me this 12 months was the rising variety of papers analysing fashions. In reality, a number of of my favorite papers this 12 months have been such evaluation papers. An early spotlight was the wonderful survey of research strategies by Belinkov & Glass (2019). This 12 months was additionally the primary one (in my reminiscence) the place many papers have been devoted to analysing a single mannequin, BERT (such papers are referred to as BERTology). On this context, probes (see the determine under), which intention to grasp whether or not a mannequin captures morphology, syntax, and so forth. by predicting sure properties have develop into a standard instrument. I notably appreciated papers that make probes extra dependable (Liu et al., 2019; Hewitt & Liang, 2019). Reliability can be a theme within the ongoing dialog on whether or not consideration gives significant explanations (Jain & Wallace, 2019; Wiegreffe & Pinter, 2019; Wallace, 2019). The persevering with curiosity in evaluation strategies is probably finest exemplified by the brand new ACL 2020 observe on Interpretability and Evaluation of Fashions in NLP.
Why is it essential? State-of-the-art strategies are used as black bins. As a way to develop higher fashions and to make use of them in the true world, we have to perceive why fashions make sure selections. Nevertheless, our present strategies to clarify fashions’ predictions are nonetheless restricted.
What’s subsequent? We’d like extra work on explaining predictions that goes past visualisation, which is commonly unreliable. An essential pattern on this course are human-written explanations which can be being offered by extra datasets (Camburu et al., 2018; Rajani et al., 2019; Nie et al., 2019).

{kind=link}